


Lecture 16
Oct – 31 – 2007











Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Unsupervised learning, specifically clustering and pattern discovery in unlabeled data. Hierarchical clustering, clustering algorithms, and distance measures. Distance measures are crucial in unsupervised learning and often more important than the choice of clustering algorithms. Common distance measures include euclidean distance, city block distance, and cosine similarity.
Typology: Study notes
1 / 22

This page cannot be seen from the preview
Don't miss anything!
x^1
1 ,x
1 , x 2
1 ,…, x 3
(^1) m
x^1
2 ,x
2 , x 2
2 ,…, x 3
(^2) m
… …
x^1
n,x
n, x 2
n,…, x 3
nm
(^1) y (^2) y ny
So far, our data has beenin this form:
x^1
1 ,x
1 , x 2
1 ,…, x 3
(^1) m
x^1
2 ,x
2 , x 2
2 ,…, x 3
(^2) m
… …
x^1
n,x
n, x 2
n,…, x 3
nm
We will be looking at unlabeled data:
What do we expect to learn from such data? I have tons of data and need to:
organize it betterfind trends in itunderstand it better
Finding association patterns in data …
Dimension reduction for visualization
Example Applications
Information retrieval – cluster retrieveddocuments to present more organized andunderstandable results
-^
Image segmentation: decompose an image intoregions with coherent color and texture
-^
Vector quantization for data Compression: groupvectors into similar groups, and use group meanto represent group members
-^
Computational biology: group gene into co-expressed families based on their expressionprofile
Distance Measures
One of the most important question inunsupervised learning
-^
Often more important than the choice ofclustering algorithms
-^
Usually need to consider the application domain
-^
Ideally we would like to learn a distancemeasure from user guidance– A user interface to solicit things like object A is similar
to object B, dissimilar to object C
class, but nonetheless important
Common distance/similarity measures•
Euclidean distance
-^
City block distance (Manhattan distance)
-^
Cosine similarity
-^
More flexible measures:
one can learn the appropriate weights given user guidance
Note: We can always transform between distance and similarity using a
monotonically decreasing function
∑=
′ −
= ′^
d i
i
i^
x
x
x x L
1
2
2
)
(
) , (
2
1
)
(
) , (^
i
d i
i i^
x x w x x D ′ −
= ′^
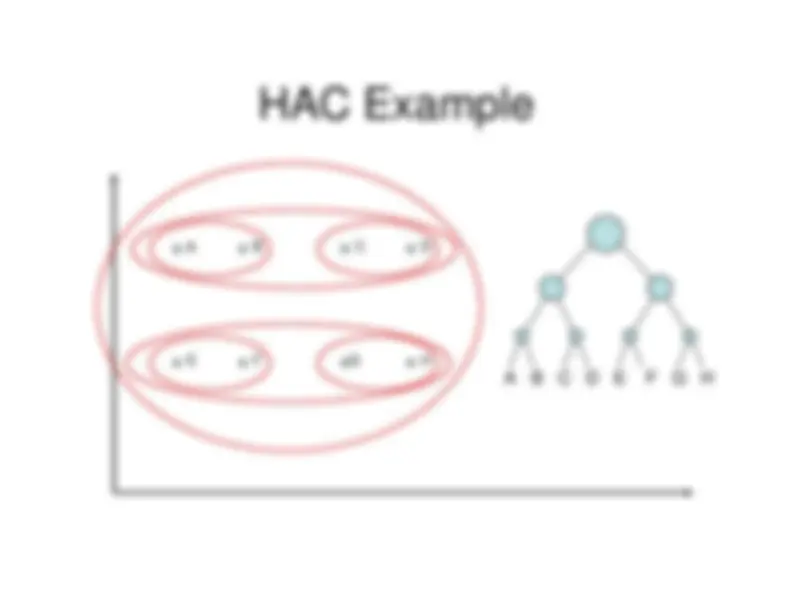
Hierarchical Agglomerative Clustering
Assumes a
similarity function
for determining the
similarity of two instances.– This could just be the inverse of a given distance
function
Starts with each object in a separate cluster andthen repeatedly joins the two clusters that aremost similar until there is only one cluster.
-^
The history of merging forms a binary tree orhierarchy.
HAC Example
A^
B^
C^
D H
G
E^
F
A^
B^
C^
D^
E^
F^
G
H
Cluster Similarity
Assume a similarity function that determinesthe similarity of two instances:
sim
( x
, y
There are multiple way to turn instancesimilarity function into a cluster similarityfunction:– Single Link: Similarity of two most similar members
of clusters
members of clusters
of clusters
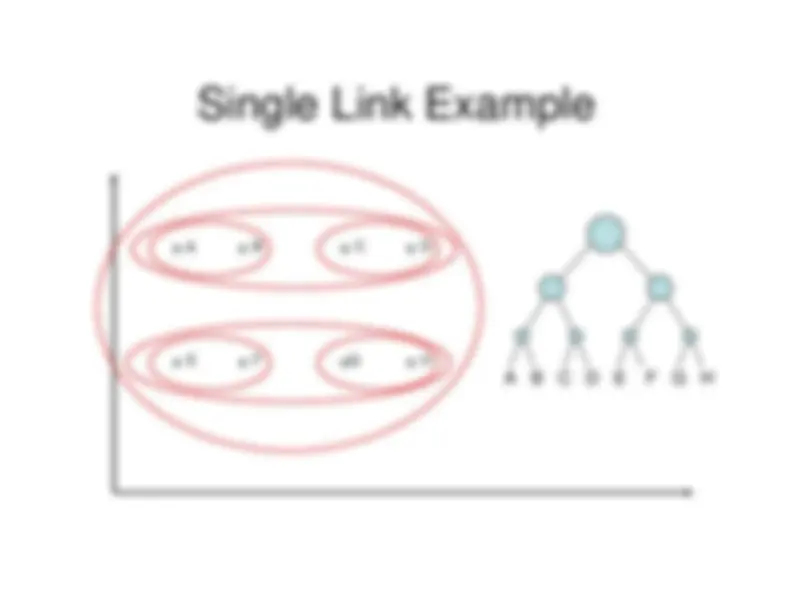
Single Link Agglomerative Clustering
-^
Use maximum similarity of pairs:
-^
Can result in “straggly” (long and thin) clustersdue to
chaining effect
islands.
,
x' x
j
i^
c
c
j i^
∈
∈
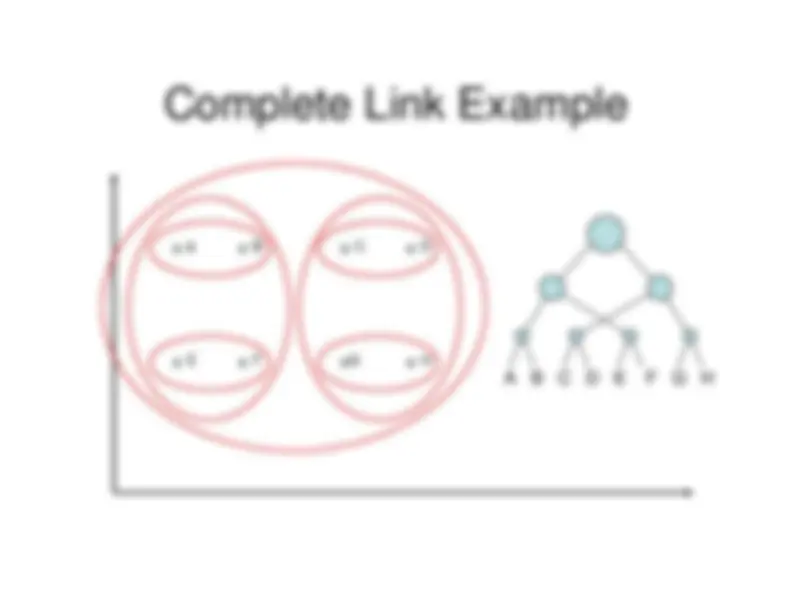
Complete Link Agglomerative Clustering• Use minimum similarity of pairs:• Makes more “tight,” spherical clusters that
,
x' x
j
i^
c
c
j i^
∈
∈
Complete Link Example
A^
B^
C^
D H
G
E^
F
A^
B^
C^
D^
E^
F^
G
H