


Unsupervised Learning:
Clustering & Model Fitting













Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of unsupervised learning, focusing on clustering and model fitting. Topics include the goals of presentations, unsupervised problems, typical tasks, and bioinformatics applications using microarrays. Agglomerative clustering, distance measures between clusters, and dendrograms.
Typology: Assignments
1 / 23

This page cannot be seen from the preview
Don't miss anything!
Reminder: office hours truncated tomorrow
“whenever I get in” until noon
HW3 due: Dec 2
Have an excellent Turkey Day!
Do NOT tell us:
Every detail of every experiment
Choose the parts to show us carefully
Each thing you show us should be informative
about your conclusions
Place for excruciating detail is the paper
Every step of all the math
Every background reference
Focus on the “big picture” and the “take home
message”
Listeners will take home ~10 bytes. Make sure
they’re the right 10 bytes!
Given:
Set of data points
Find:
Good description of the data
Given, data matrix
Which points are similar?
How do points cluster together?
How many groups are there?
Statistical description of distribution of data?
11
12
1 N
21
2 N
d 1
dN
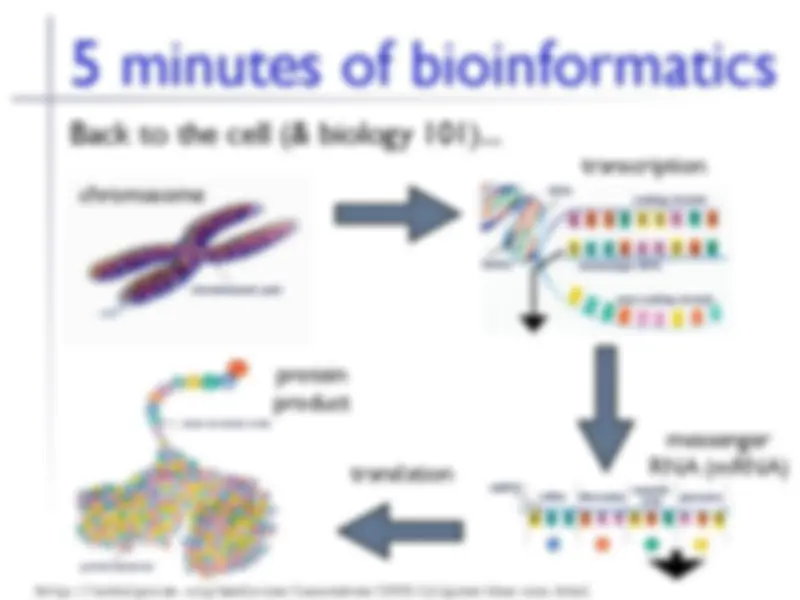
Gene microarray (a.k.a., genechip, DNA chip, etc.)
Measure thousands (10s or 100s of thousands) of
genes simultaneously
Critical tool in bioinformatics
Understand function of genes, networks of gene
activity, response to stimuli, etc.
Leads to some very nasty analysis problems...
Only mRNA can be (easily measured)
When gene is “activated”, mRNA is produced
Can be “upregulated” or “downregulated” to
produce diff. concentrations of mRNA
Can be active or inactive under different
conditions:
External stimuli (food, ph, temperature, viral
infection, etc.)
Internal metabolic processes (cell cycles,
pathways, etc.)
mRNA measurements correlated with cell activity
measuring many mRNA...
Population A of cells
Population B of cells
mRNA pool A
mRNA pool B
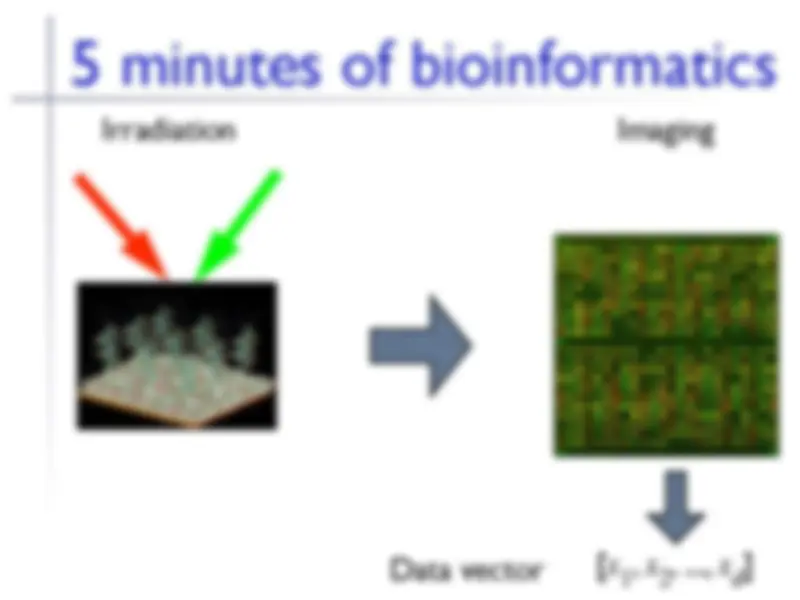
Irradiation
Imaging
[ x
1
, x
2
, ..., x
d
Data vector
Measure populations over
time
Monitor development of
cell, metabolic processes,
response to introduction
of stimulus, etc.
Time series of data
x 11
x 12
· · · x 1 N
x 21
.
.
. x 2 N
.
.
.
.
.
.
x d 1
... x dN
Can consider either rows or
columns to be “points”, depending
on what you want to know
Most clust. algorithms based on distances between
points
Recall: distance (metric) function d ( x
1
, x
2
Symmetry: d ( x
1
, x
2
)= d ( x
2
, x
1
Identity: d ( x
1
, x
1
Triangle inequality: d ( x
1
, x
3
)<= d ( x
1
, x
2
)+ d ( x
2
, x
3
E.g., Euclidean distance, kernel distance, etc.
Sometimes have a natural similarity function instead
Can usually convert to a metric or semi-metric
Group clusters by mutual distance
“Bottom-up” method: start w/ points and combine
into groups, combine groups, etc.
Problem: We have distance between pairs of points
Agglomerative clustering requires distance between
pairs of clusters
A number of measures are possible:
min
1
2
x∈c 1
;x
′ ∈c 2
′
c
c
Problem: We have distance between pairs of points
Agglomerative clustering requires distance between
pairs of clusters
A number of measures are possible:
max
1
2
x∈c 1
;x
′ ∈c 2
′
c
c