Download World Bank Knowledge for Change Program – Full Proposal ... and more Summaries Machine Learning in PDF only on Docsity!
Basic Data:
Title Structuring 50 years of knowledge on development – Applying natural language processing (NLP) models to a corpus of 500,000+ documents
Linked Project ID N.A. Product Line RA
Applied Amount ($) 60,000 Est. Project Period
Team Leader(s) Olivier Dupriez Managing Unit
DECAT
Contributing unit(s)
DECAT
Funding Window Innovation in Data Production, Analysis and Dissemination
Regions/Countries World
General:
- What is the Development Objective (or main objective) of this Grant?
LOCATING KNOWLEDGE. The design of economic and social development policies and programs, and research on development issues, must start with a review and understanding of existing knowledge on the subject(s) of interest. A common problem that policy makers, program managers, and researchers face when doing such exploratory work is the identification of the most relevant information available. Discovery methods provided by data and documents repositories— through filtering or exact keyword matching —limit the relevance of the results returned to the user; such methods will return the materials that literally match the query ( lexical search ), not those are semantically or conceptually satisfying it ( semantic or conceptual search ). For example, a search for “malnutrition” may fail to return data or documents related to stunting, wasting, or obesity. Also, the search functionalities in data and documents catalogs do not provide adequate solutions to identify documents and datasets based on the combination and relative importance of the topics they address. In summary, search functionalities in data and documents catalogs may be effective at helping users who know precisely what they need to find and who are able to formulate queries accordingly, but they perform poorly as recommender systems.
IDENTIFYING KNOWLEDGE GAPS. Another problem is the identification of gaps in the available resources. Assessing how extensively certain topics (or combination of topics) have been addressed in a knowledge repository, and tracking the coverage of emerging themes, can lead to a better understanding of the dynamics of development policies and to a better alignment of research work to operational priorities.
Such problems can be largely solved by exploiting machine learning algorithms—natural language processing (NLP) in particular—designed to discover information in vast amounts of data and documents that cannot possibly be processed manually.
NLP methods have been the object of extensive research in recent years and are extensively used by the most advanced search engines. Multiple algorithms have been open-sourced by researchers and companies like Google or Facebook. What these algorithms make possible, among other things, is to:
- Automatically identify topics covered in large corpuses of documents and measure the relative importance of each topic in each document, i.e. the topic-composition of each document. This is done in an “unsupervised” manner, without having to provide any pre-defined taxonomy of topics.
- Automatically derive the “semantic closeness” between words and combinations of words included in the vocabulary by generating word embeddings.^1 This semantic closeness between terms and expressions is what allows search engines to “interpret” or “understand” users’ queries. Large companies such as Google and Facebook have been leading the initiative of sharing word embedding models trained on general datasets. Our goal is to train and publish more specialized and domain-specific models, optimized to social and economic development issues.
Applying such techniques to a large quantity of development-related documents^2 can be used (i) to improve the discoverability of these resources, and (ii) to generate derived datasets that will allow researchers to better understand the content, evolution, scope and coverage of knowledge on development, over time and across countries.
Our main objective is to address this knowledge discoverability issue to catalyze the utility and use of the immense volume of knowledge on economic and social development.^3 We will develop new data and data discovery products using state-of-the-art machine learning techniques and artificial intelligence models. These solutions will rely exclusively on open source software and algorithms. The outputs of the project (models, scripts, search tools, and derived datasets) will be made openly accessible to allow adaptation and use in other organizations. The scripts, codebase, and guidelines are also intended to be used as training materials.
- Summary description of Grant financed activities
A comprehensive feasibility study for the proposed activities has already been successfully completed. The Grant-funded activities aim to expand the scope and coverage of this work to increase the accuracy and relevance of the output, and to automate, document and package the proposed solutions. The Grant financed activities will consist of the following:
- Expansion of the corpus. The feasibility study exploited a selection of around 130,000 World Bank documents. To increase the accuracy and relevance of our models and tools, this corpus will be expanded to reach 500,000 documents. The Grant will finance part of the web scraping work required to build our final corpus (consultant time).
- Pre-processing of documents. To be used as input for machine learning models, the documents must be transformed. A pipeline of procedures (involving spell checking, stop-words suppression, n-grams detection, lemmatization, tokenization, part-of-speech tagging, metadata generation, acronyms detection and conversion, named entity recognition, and more) has been developed during our feasibility study. The Grant will finance the optimization, documentation, and automation of this process.
(^1) Word embeddings are representation of words in the form of vectors of real numbers. (^2) They will be applied to publicly-available data and documents from the World Bank and selected development partners, forming a rich and diverse corpus of around 500,000 documents covering the period 1950 to now. (^3) For decades, the World Bank, regional development banks and other development agencies have conducted research, evaluation and analytical work on development issues. Hundreds of thousands of documents have been and continue to be made publicly accessible, forming a rich – and under-exploited – global public good. As of 15 September 2019, the World Bank’s Documents and Reports website provided open access to 337,346 documents (covering the period 1950 to now), and new documents are added on a continuous basis. Among these documents, 78,656 are categorized as “Publications and Research”, 11,759 as “Economic and Sector Work”, and 218,546 as “Project documents” (the Bank also publishes projects description and ratings). Regional development banks, United Nations agencies, and others also publish vast quantities of research, analytical and project documents (for example, as of 15 September 2019, the Asian Development Bank’s website provided access to 11,402 research/analytical documents, and 43,953 project documents).
Use case 1
An environment economist is tasked to write a report on the impact of climate change on poverty. To locate relevant data and documents in World Bank documents and reports, she takes advantage of the data on topic composition of documents generated by topic modeling. The model tells us that the share of topic 27 “climate change”^4 in the available documents^5 ranges from 0 to 95%, and that the share of topic 12 “poverty” ranges from 0 to 52%. Setting a threshold on each topic (e.g., respectively 30% and 20%) will identify documents that significantly cover both topics (documents that are “at least” 30% about climate change and 20% about poverty). This approach returns more relevant documents, and a more relevant ranking of these documents, than what a keyword-based search, or filtering based on documents tags^6 , would return. Additional filters (by country, year, others) could be applied as relevant.
(^4) A topic is defined by a series of related words. Topic 27 which we label “climate change” is defined by words and expressions
like climate change, disaster, flood, etc. (^5) This relates to our test corpus of around 130,000 WB documents. (^6) WB document are tagged against a pre-defined taxonomy of topics. These tags provide a binary variable for filtering documents but fail to indicate the relative importance of a topic in a document.
Use case 2
A researcher wants to identify data of any type (microdata, geospatial, time series, documents, images, and others) on malnutrition available at the World Bank. A single, universal search tool (implemented in a beta version of the cataloguing software developed by the World Bank Data Group^7 ) will interpret this query and identify, through semantic and not simple keyword search, the most relevant resources (independently of the language of the resource, taking advantage of automatic translation tools).
(^7) The Development Data Group has developed the NADA open source software (http://nada.ihsn.org), originally to catalog
and disseminate microdata. A new version of this software is being developed, which can accommodate any data type. Some of the outputs and recommendations of the KCP proposals will be implemented in this software application, providing a convenient solution to external agencies to improve their own cataloguing systems. The software is used by multiple national and international organizations.
Use case 4
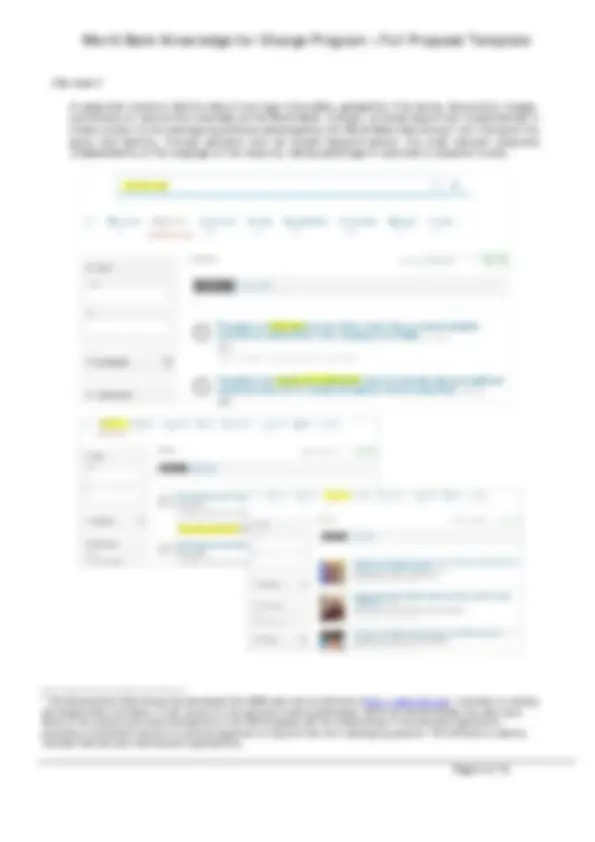
A data scientist wants to mine newsfeeds from Factiva (an international news database produced by Down Jones) to generate predictors—through sentiment analysis—to be used for nowcasting employment rates. A subset only of the millions of news available from Factiva would be relevant for that purpose. To only acquire the ones that have value for his specific purpose, he must apply filters based on related words and expressions. Both the word embedding model (left) and the topic model (right) will provide him with a list of closely related terms and expressions with a “score” or “weight” attached to them (thereby reducing the arbitrariness of keyword selection and the risk to miss relevant news).
Use case 5
The Data Analytics and Tools unit of the World Bank Data Group (the team submitting this KCP proposal), is providing support to the Data Science Institute at the National Polytechnic School of Yamoussoukro in Côte d’Ivoire. Part of this project (funded by the Trust Fund for Statistical Capacity Building) consists of developing training materials and exercises for machine learning course. The KCP project will provide them with training and reference materials (in the form of scripts and guidelines) on data wrangling (text acquisition and pre-processing) and modeling (topic modeling and word embeddings), together with a large curated collection of documents ready to be used for practice and tests.
Use case 6
The IT staff of a research center seek to improve the relevance of the search functionalities of their internal data catalog. The Github repository of the project will provide them with free and unrestricted access to the models (and instructions) they need to infer topics in their resources, without requiring the compute resources that fitting their own models would require. They will also find in the technical documentation generated by the project the necessary recommendations for add semantic capability to their search engines.
- Describe analytic design & methodology. Elaborate on hypotheses, conceptual framework, data (survey design if applicable).
DATA
Topic models and word embedding models must be trained on large quantities of documents. As our objective is to focus on economic and social development, our project will build a large corpus of relevant documents. This corpus will be diverse enough to cover all regions and all themes of importance (health, education, economic growth, infrastructure, and many more). The core data used for the project will consist of a corpus comprising:
- World Bank Documents and Reports (http://documents.worldbank.org/). These documents (~350, documents) cover the period 1950 to now and are publicly accessible. We will exclude some documents that are not relevant for our purpose and expect to retain around 250,000 documents.
- Publications and project documents from regional development banks (African Development Bank, Asian Development Bank, and Inter-American Development Bank), publicly available from these organizations’ respective website.
- Publications and research work from other development agencies, including IMF, OECD, specialized agencies of the United Nations (Food and Agriculture Organization, UNICEF, World health Organization, High Commission for Refugees, World Food Program, International Labor Organization, and others), and think tanks or research organizations.
- Possibly selected academic journals and newsfeeds (to be confirmed after review of their terms of use).
- Detailed metadata on a large collection of micro-datasets (provided by the World Bank’s internal Microdata Library, a catalog of over 8,000 household surveys and censuses) and time series (from the World Bank’s World Development Indicators).
The final corpus will contain around 500,000 documents.
The use of pre-trained models (like GloVe by Stanford or fastText by Facebook) as an input to train our own models will also be considered (these models are not specific to social and economic development and are therefore not fully fit for our purpose).
- Describe Implementation arrangements. Identify timeline, key team members and their roles. If the partnership is involved, describe the partnership arrangements, and the respective responsibility of Bank units and partners.
The project will be implemented over a period of 16 months (from February 2020 to June 2021).
Task Description Timeline
Building the corpus We already developed scripts to scrape documents for WB, ADB, and IMF; we will develop scripts for the other websites we intend to scrape.
02-20 to 07-
Further development, optimization, and testing of pre-processing scripts
Most pre-processing scripts have already been produced, but a few remain to be optimized (n- grams detection, optimization for large volume of documents, named entity recognition, etc.)
02-20 to 07-
Adaptation of topic modeling scripts (implementing the LDA model) and design of a database to store the models’ output
We tested the Mallet implementation of the LDA model on ~130,000 documents; implementation on our full corpus will require adaptations. A MongoDB database will be created to store the model’s output and documents metadata (currently stored as CSV files).
08-20 to 12-
Adapting and running word embedding models and publish output in new API
We tested word2vec on ~130,000 documents and developed a simple API to retrieve the model’s output. The model will be implemented on the full corpus and a fully- functional API will be developed and documented.
08-20 to 12-
Visualization for dissemination of results
We already adapted an open source D3 tool (DFR-browser) to visualize the output of the LDA topic models; a more flexible JavaScript solution will be developed for dissemination of the results.
06-20 to 03-
Search/discovery tools A web interface with an underlying SOLR search engine will be developed; the output of the models will also be exploited in a new version of the Data Group’s NADA software.
08-20 to 03-
Process automation We will automate the process of acquiring (scraping) documents, inferring topics, and publishing augmented metadata in a database. The objective is to allow our documents database to maintain itself with minimum human intervention after completion of the project.
06-20 to 04-
Analysis/reporting The project objective is to generate input for analysis, not to conduct analysis (which will be best done by subject-matter specialists). We will however generate descriptive analysis as advocacy/demo materials.
06-20 to 04-
Technical documentation A detailed technical report will be produced, describing the whole process of document acquisition, pre-processing, and modeling. The report will also provide guidelines on the use of the project output to improve discoverability in other databases.
08-20 to 06-
Sharing / dissemination Scripts and documentation will be packaged and published on Github.
The output/outcome of the project will be presented at conferences or other events (brown-bag lunches, etc.) at the World Bank and partners (ADB, IDB). They will also be publicized in blogs.
08-20 to 06-
Core team
The project will be implemented by a core team at the Data Analytics and Tools unit of the World bank development Data group comprising of:
- Olivier Dupriez , Acting Manager and Lead Statistician, Data Analytics and Tools unit (DECAT), World
Bank Development Data Group (DECDG): task team leader, project coordination, and reporting.
- Aivin Solatorio , Data Scientist, DECAT: NLP modeling; technical documentation; training. Aivin is an experienced data scientist with strong expertise in Python and natural language processing. He has a background in physics and computer science. He recently joined the Bank, after having worked for five years as chief data scientist in a start-up company.
- Mehmood Asghar , Data Engineer, DECAT: database design; implementation and optimization of SOLR search; automation of processes; technical documentation; training. Mehmood is a computer scientist with extensive experience in software and web development and database management. He has expertise in SQL, SOLR and other techniques that will be used in the project. He is the lead developer of the Bank’s NADA cataloguing application.
- Dharana Rijal , Consultant, DECAT: web scraping; modeling, communication/dissemination. Dharana has expertise in web scraping and in data science using Python.
Collaborators
- World Bank colleagues from the IT Department, Library and Archive. This collaboration is intended to identify additional use cases that will increase the relevance and foster use of the project output, and to ensure compliance with the Bank’s IT environment for implementation of the solutions in a production environment.
- Counterparts at the Asian Development Bank and Inter-American development Bank (staff in charge of knowledge products and services). ADB and IDB have been selected due to existing affinities and
We plan to disseminate the results of the project as follows:
- Publish all scripts and related technical documentation on Github (open access); this dissemination channel will target a technical audience
- Present the results – with focus on use cases – at brown-bag-lunches within the Bank, and present the tools and methods to more specialized audiences (data scientists, librarians, IT specialists)
- Present the results of the project at the Inter-American Development Bank, Asian Development Bank, and African Development Bank (for ADB and AfDB, presentations will be by video-conference, or locally if we can take advantage of travel to Manila and Abidjan funded by other projects).
- Organize a training session on natural language processing at the Data Science Institute of the Ecole Nationale Polytechnique Houphouet-Boigny (Côte d’Ivoire), under their master’s in data science program (funded by the Trust Fund for Statistical Capacity Building; no cost charged to the KCP project)
- Embed new search functionalities in the open source NADA cataloguing software application (used by statistical agencies, research centers, and international organizations), and share technical guidelines with the IT staff in organizations that use the application
- Publicize the output and outcome of the project in blogs
- Possibly (to be confirmed), publish a paper on machine learning approaches applied to data discovery in a peer-reviewed journal
We also expect that users of the project output, in particular researchers interested in studying the evolution of development topics over time, will contribute to publicize the outcome of the project. This will likely happen after closing of the project.
- Describe the capacity building components, including the collaboration with local partners, researchers from developing countries.
The implementation of the project requires highly specialized skills and compute power. It is not justified to involve or build such capacity in agencies that do not maintain large collections of data and documents and that do not have an IT environment that would allow them to train machine learning models on large collections of documents and data. For that reason, the collaboration for the implementation of the project focuses on regional development banks. Once the outputs of the project are generated and released (topic models, word embeddings accessible through APIs, improved solutions for search engines, new databases, technical guidelines), many agencies will become potential stakeholders. Our priority will be to build capacity in machine learning (natural language processing) at the Data Science Institute of the Ecole Nationale Polytechnique Houphouet-Boigny (Côte d’Ivoire), in collaboration with a project funded by the Trust Fund for Statistical Capacity Building.
- Document evidence of the consultation process with relevant research and operations units. E.g. consultation conducted, comments received, & how comments were addressed. TTLs should also describe plans to maintain operational and research consultation.
The project team presented the results of the comprehensive feasibility study to World Bank colleagues from the IT department (Library/Archives/IT development) on November 8, 2019. This presentation confirmed the convergence of interest and an interest in collaborating in various aspects of the proposal.
The project team is also working closely with the World Bank team in charge of the management of the Bank’s Microdata Library (one key objective of the project being to add semantic/conceptual search capabilities to this large database of over 9,000 surveys and census datasets).
Counterparts from the Inter-American Development Bank (Knowledge and Learning Department) and Asian Development Bank (Research Department) have been contacted and expressed an interest in the project. The modalities of this collaboration will be determined after the project is approved. This collaboration will involve no cost to the project (except for a planned presentation of the results at ADB at completion of the work; IDB is located in Washington DC and no funding is required for this collaboration). We do not plan to
include the African Development Bank as a collaborator in the project (although we will keep them informed and share output). The reasons are that (i) a significant share of their documents is in French and we prefer at this stage to focus on documents in English and one other language (Spanish) as a test, and (ii) we do not have the same technical relationship that we have with data scientists from the Asian Development Bank or geographic proximity we have with the Inter-American Development Bank.
We also consulted the UNHCR-WB Joint Data Center (JDC) on Forced Displacement. The JDC was established to foster research on forced displacement and to increase investments in operations related to forced displacement. The project will provide a powerful solution to conduct an in-depth assessment of the coverage of displacement-related issues in past research and operational work, and to monitor changes in future research and operational work from a JDC perspective. The JDC would finance the incremental cost involved in implementing this specific monitoring solution (JDC would not cover the cost of modeling but would finance the cost of exploiting the model and tools developed by the KCP project for their specific purpose).
Disbursement Projection
From Date To Date Amount February 2020 June 2020 20, July 2020 June 2021 40,