



CS181 Lecture 23:
Wrap-up
David C. Parkes




















































































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
A lecture note from cs181, covering the topic of classification in machine learning. The lecture discusses various supervised learning algorithms such as decision trees, perceptron algorithm, neural networks, support vector machines, and instance-based methods. The concept of inductive bias is introduced, and the difference between restriction bias and preference bias is explained. The lecture also covers practical issues in neural networks and decision trees, as well as an introduction to reinforcement learning.
Typology: Study notes
1 / 93

This page cannot be seen from the preview
Don't miss anything!
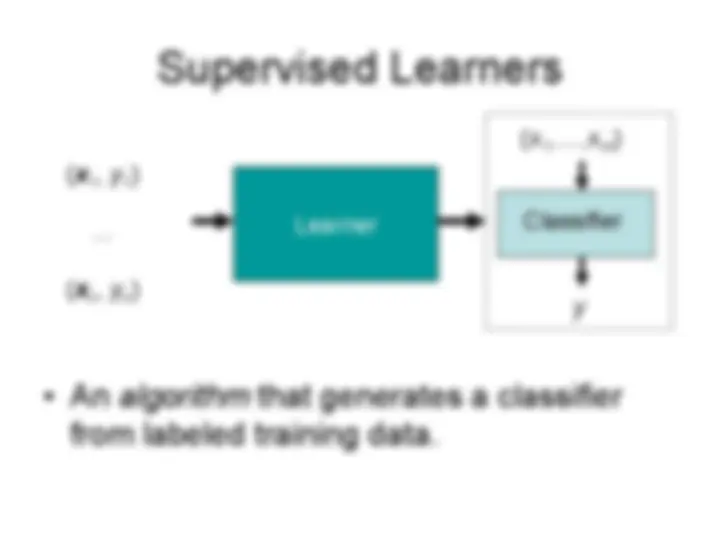
Classifier
( x 1 ,…, xm )
y
Learner
( x 1 , y 1 )
…
( x n, y n)
Example
Only training examples are unambiguously classified.
validation
error
25
train validation test
(Bishop) 35
perceptron learning rule
convergent for separable data
X 1
X 2
-1 1
1
36