


Statistics II
Mikel Esnaola
Universitat Autònoma de Barcelona
slides by Xavier Vilà
Year 2017 - 2018
























































Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
A part of the statistics ii course offered at universitat autònoma de barcelona during the academic year 2017-2018. It covers the concepts of inferential statistics, simple random sampling, and the distribution of main sample statistics, including mean, variance, and proportion.
Tipo: Apuntes
1 / 66

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Mikel Esnaola Universitat Autònoma de Barcelona
slides by Xavier Vilà
Attribution-Noncommercial-Share Alike 3.0 Spain
You are free:
Under the following conditions:
For any reuse or distribution, you must make clear to others the license terms of this work. Any of the above conditions can be waived if you get permission from the copyright holder. Nothing in this license impairs or restricts the author’s moral rights.
Copyright ©c 1998-2015 Xavier Vilà.
This is a human-readable summary of the Legal Code (the full license) available in http://creativecommons.org
Mikel Esnaola
Office B3-164 (Unitat de Fonaments de l’Anàlisi Econòmica - Dept. d’Economia i d’Història Econòmica)
Office Hours: Mondays 3pm - 6pm & Tuesdays 3pm - 6pm (send email before)
Statistics becomes extremely important for the first of these three items.
In order to study a real problem, the researcher must observe the real world
Chapter 1 We will study in detail how the reality is rigorously summarized and what are the main features of the results obtained in this process.
Chapter 2 We will see the first approach on how to generate conclusions about some real issues based on what we observe in the summary.
Chapters 3 and 4 introduce more sophisticated techniques to make inferences about the reality using some of the more elemental results seen in Chapter 2.
Chapter 5 Introduces the linear regression analysis, a technique widely used in the economic analysis (and other sciences) to study the relationship between variables.
Chapter 1 is very important in order to easily understand what other chapters deal with, and also to get an global idea of the whole process of statistical inference.
A careful study and deep understanding of the topics in Chapter 1 is necessary before undertaking the study of other chapters
It is important to understand that
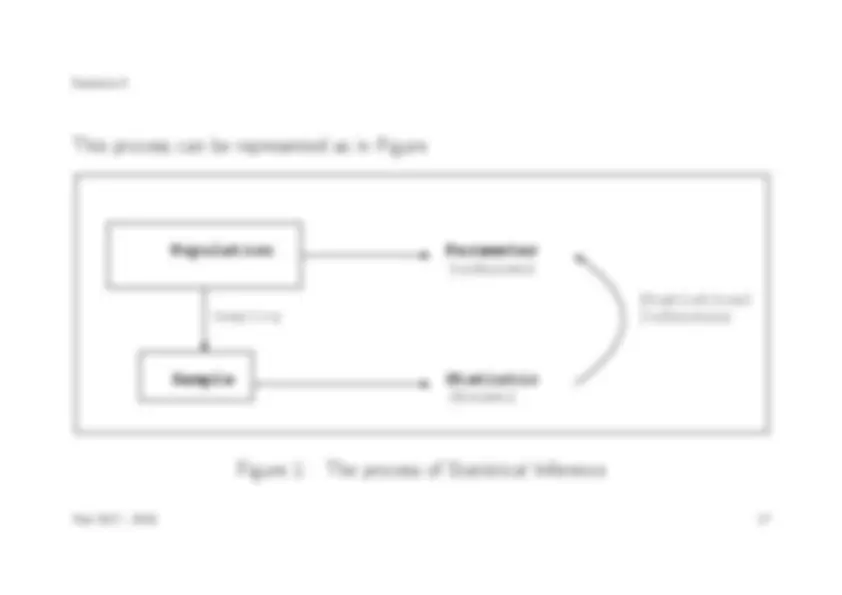
Statistical inference is mainly built upon four main concepts, which will be defined and described below.
Population Is the set of elements that are the object of study. The goal will be to draw some conclusion regarding some specific feature of this population.
Example 2 All the apples in the world. The feature at study is whether an apple falls down or not. Example 3 Labor force in the European Union. The feature at study is whether a worker is unemployed or not. Example 4 Production of Intel chips in a given day. The feature at study is whether a chip is faulty or not.
Sample Subset of the Population used to draw conclusions about the population
Example 5 50 apples in Newton’s garden. Example 6 Unemployment statistics at the European Union. Example 7 25 Intel chips manufactured in a given day.
Statistic Computation made using the elements in the sample and used to get an approximation to the true value of the parameter. It is important to notice that this value will be known (since we will compute it) and will be used to draw conclusions on the true value of the parameter, which is unknown and is what is of interest to us.
Example 11 Proportion of falling apples among the 50 sampled apples in Newton’s garden. Example 12 Unemployment rate among the workers interviewed in the un- employment statistics in the European Union. Example 13 Proportion of faulty chips among the 25 selected chips produced in a given day.
From this four main concepts, the process of statistical inference works as follows:
We can now provide a definition for Statistics (or Statistical Inference, to be more precise) which is more formal than the one offered in the introduction.
Definition 14 Statistical Inference is a subject whose main objective is to draw conclusions regarding a population through the study of one sample by means of probabilistic techniques.
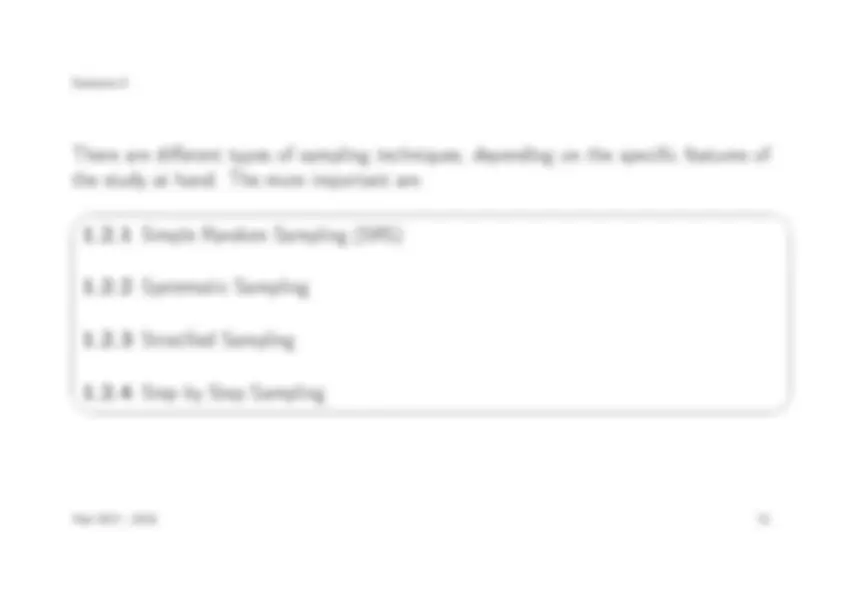
Definition 15 Sampling is a systematic technique to select a sample out of a population in such a way that it is representative of the population