



Código Genético
Docente o equipo docente
ESCUELA ACADÉMICO PROFESIONAL DE MEDICINA HUMANA
Curso: PROCESOS CELULARES Y MOLECULARES
Unidad: IV






















Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
1 / 30

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Código Genético Docente o equipo docente ESCUELA ACADÉMICO PROFESIONAL DE MEDICINA HUMANA Curso: PROCESOS CELULARES Y MOLECULARES Unidad: IV
Al finalizar la sesión de práctica, el alumno será capaz de determinar el código genético en la síntesis proteica.
La secuencia del material genético se compone de 4 bases nitrogenadas distintas,
Está organizado en tripletes o codones:
El código genético es degenerado:
CÓDIGO GENÉTICO (Carta Universal de codificación) Aminoácidos: Ala=Alanina. Arg=Arginina. Asp=Aspartato. Asn=Asparagina. Cys=Cisteína. Gln=Glutamina. Gly=Glicina. His=Histidina. Ile=Isoleucina. Leu=Leucina. Lys=Lisina. Met=Metionina Phe=Fenilalanina. Pro=Prolina. Ser=Serina. Thr=Treonina. Trp=Triptofano. Tyr=Tirosina. Val=Valina.
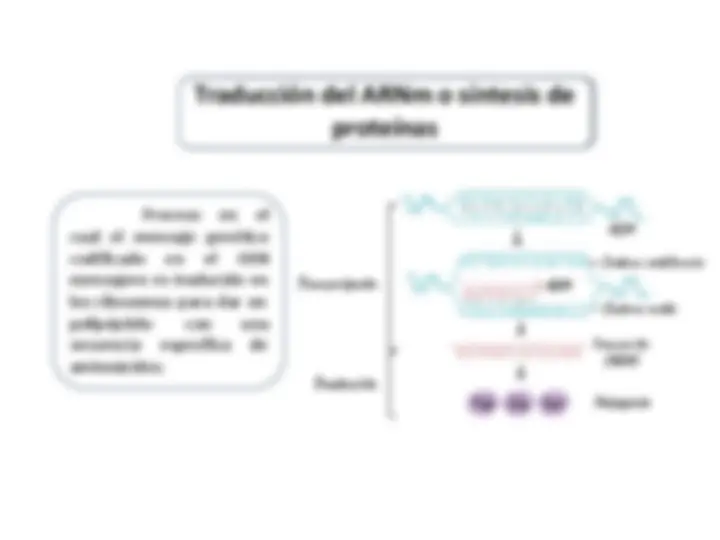
FIG. 2 DOGMA DE LA BIOLOGÍA MOLECULAR “ACTUAL” La información contenida en la molécula de ADN y de ARN es la misma, por lo cual se puede obtener la secuencia proteica codificada en una molécula de ADN a partir de su secuencia.
a) Si obtenemos los mensajeros correspondientes a ambas hélices, teniendo en cuenta que el ARN-m se sintetiza en la dirección 5 ’ → 3 ’ y que la A del ADN aparea con el U del ARN, obtenemos las siguientes secuencias: ADN 3’ T A C G A T A A T G G C C C T T T T A T C 5’ ARN 5’ A U G C U A U U A C C G G G A A A A U A G 3’ La otra secuencia sería: ADN 5’ A T G C T A T T A C C G G G A A A A T A G 3’ ARN 3’ U A C G A U A A U G G C C C U U U U A U C 5’