¡Descarga Análisis de Interacción con Regresión: Rectas Simples y Variables Interactuantes. - Prof. y más Apuntes en PDF de Psicología solo en Docsity!
PARTE 4: ANÁLISIS DE LA INTERACCIÓN ENTRE VARIABLES
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
- Interacción entre una variable cuantitativa y otra cualitativa Índice de contenido
- 1.1. Predictoras cuantitativas centradas
- 1.2. Profundizando en el análisis de una interacción significativa
- 1.2.1. Codificación dummy
- 1.2.2. Codificación de efectos
- 1.2.3. Representación gráfica.................................................................
- 1.3. Análisis de la covarianza (ANCOVA)
- Interacción entre variables cuantitativas
- 2.1. Variables predictoras centradas................................................................
- 2.2. Profundizando en el análisis de una interacción significativa
- 2.3. Representación gráfica
- 2.4. Coeficientes estandarizados
- Interacción entre variables categóricas
- 3 1 Codificación de efectos
- 3.2. Codificación ortogonal
- 3.3. Codificación dummy
- 3.4. Secuencia de prueba en los diseños factoriales no ortogonales
- Referencias
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
En este último tema nos ocuparemos de cómo analizar la interacción entre variables desde un modelo de regresión. Esta será la opción idónea cuando alguna de las variables predictoras sea cuantitativa, como suele ocurrir en las investigaciones correlacionales de encuesta. Sin embargo, el análisis de regresión puede ser utilizado igualmente cuando todas las predictoras son categóricas, como ocurre en las investigaciones factoriales entregrupos. Abordaremos este procedimiento en el último aparto del tema, aunque ante un diseño factorial es más habitual recurrir a los modelos de ANOVA.
1. Interacción entre una variable cuantitativa y otra cualitativa Supongamos que queremos analizar la satisfacción docente del alumnado en función del tipo de clase recibido, de estilo directivo o no directivo, y su tolerancia a la ambigüedad, medida ésta cuantitativamente a través de una escala. Podríamos plantearnos la posibilidad de que el alumnado inmerso en clases de estilo no directivo esté más satisfecho con las clases recibidas cuanto mayor sea su tolerancia a la ambigüedad (relación positiva), ya que la tolerancia a la ambigüedad es fundamental para sentirse a gusto en ese tipo de clases. En cambio, entre quienes reciben clases de estilo directivo, la satisfacción docente podría disminuir conforme aumenta la tolerancia a la ambigüedad (relación negativa), debido a que cuanto mayor es la tolerancia a la ambigüedad menos se valoran este tipo de clases. Estaríamos planteando así una hipótesis sobre la interacción entre las variables predictoras, de forma que dependiendo del tipo de clase recibido, la relación entre la satisfacción docente y la tolerancia a la ambigüedad pasa de ser positiva a negativa. Veamos cómo analizar este tipo de hipótesis a través de un modelo de regresión utilizando como ejemplo los datos propuestos por Pedhazur (1982, p.464). Para la variable tipo de clase recibido podrá usarse cualquier sistema de codificación, aunque las codificaciones dummy y de efectos pueden tener ventajas en cuanto a la interpretación de los coeficientes del modelo. Una vez decidida la codificación, para analizar el efecto interactivo será necesario construir una nueva variable resultado de multiplicar la tolerancia a la ambigüedad por la variable tipo de clase. Supongamos por ejemplo que utilizamos la codificación dummy. A continuación se muestran los coeficientes de dos modelos diferentes, el primero incluyendo exclusivamente a los efectos principales de ambas variables y el segundo a éstos más la interacción:
Como puede comprobarse, la introducción del componente de interacción hace que varíen drásticamente los coeficientes relativos a las variables aisladas. Como
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
Adicionalmente, si comparamos los cambios ocurridos entre el modelo 1 y 2 de cada tabla podemos comprobar que éstos son más drásticos cuando se utilizan puntuaciones directas, debido a la fuerte colinealidad, que disminuye cuando se utilizan predictoras centradas. Este es el motivo por el que se recomienda centrar las predictoras cuantitativas antes de iniciar el análisis de regresión.
1.2. Profundizando en el análisis de una interacción significativa Una vez detectada como significativa una interacción entre dos variables, carece de sentido la interpretación de la relación general entre la satisfacción docente y la tolerancia a la ambigüedad. Por el contrario, una interacción significativa pone de manifiesto la conveniencia de describir dos rectas de regresión simples diferentes de la satisfacción sobre la tolerancia, una para cada tipo de clase. Dichas rectas de regresión simples serán independientes del tipo de codificación utilizada, pero, como veremos a continuación, la relación entre éstas y los datos de la ecuación general sí dependen de la misma.
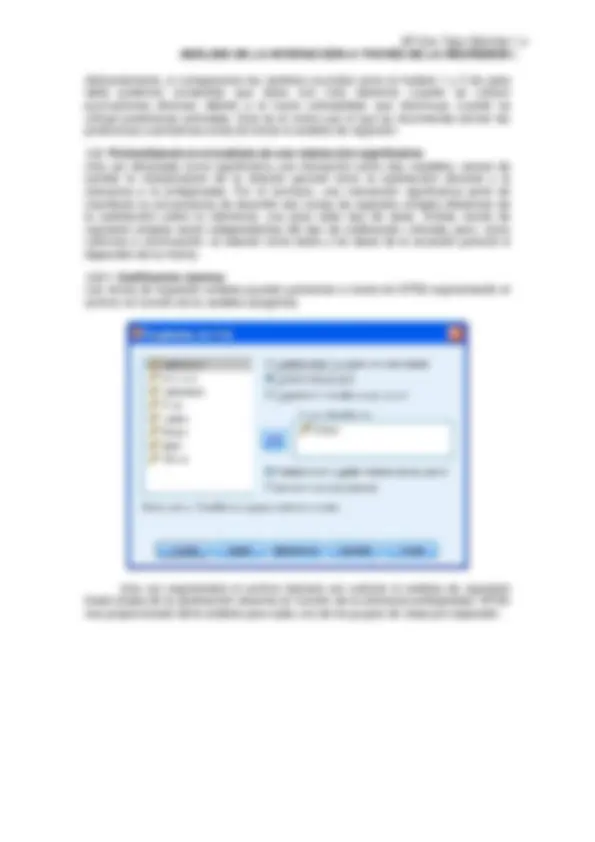
1.2.1. Codificación dummy Las rectas de regresión simples pueden generarse a través de SPSS segmentando el archivo en función de la variable categórica:
Una vez segmentado el archivo bastará con solicitar el análisis de regresión lineal simple de la satisfacción docente en función de la tolerancia ambigüedad. SPSS nos proporcionará dicho análisis para cada uno de los grupos de clase por separado:
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
Podemos comprobar así que en el grupo que recibe clases de estilo no directivo, la satisfacción docente aumenta a medida que aumenta la tolerancia a la ambigüedad. En cambio, en el grupo que recibe clases de estilo directivo, la satisfacción docente aumenta a medida que la tolerancia a la ambigüedad es menor. El cambio entre el coeficiente de regresión de la tolerancia de ambos grupos está relacionado con el coeficiente de la interacción en la ecuación general. Si éste es positivo indica que a medida que el tipo de clase crece (pasa de 0 a 1, de no directivo a directivo en nuestro ejemplo), la relación entre la satisfacción y la tolerancia a la ambigüedad se hace más positiva. Si es negativo, como en nuestro ejemplo, indica que a medida que el tipo de clase crece (pasa de no directiva a directiva) la relación entre las dos variables restantes se hace menos positiva. En nuestro caso, no sólo es menos positiva, sino que llega incluso a ser negativa en el grupo directivo. A la vista de estas rectas de regresión simples podemos hacernos más claramente una idea de los que significan los coeficientes de la recta de regresión general con codificación dummy:
Como puede comprobarse: La constante general equivale a la constante de la recta de regresión simple del grupo con código 0 (no directivo), b 0 = 4.267. El coeficiente de regresión de la tolerancia, representa la pendiente de la recta de regresión simple de ese mismo grupo, b 1 = .098. El coeficiente del tipo de clase representa la diferencia entre las constantes de ambas rectas de regresión simples, b 2 = 3.856-4.267 = -.411. Y el coeficiente de la interacción representa la diferencia entre las pendientes de ambas rectas de regresión simples, b 3 = -.107-.098 = -.205. En general, los datos proporcionados con la codificación dummy se representan gráficamente como sigue:
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
1.2.3. Representación gráfica Independientemente del tipo de codificación utilizado, cuando se detecta una interacción entre variables estadísticamente significativa, suele aportarse una gráfica representativa de dicha interacción. Para ello será necesario despejar las rectas de regresión simples para diferentes valores de la predictora cuantitativa, habitualmente su media (0 por estar centrada) y ± una desviación tipo. No es difícil hacer los cálculos manualmente:
Para el grupo de clase con estilo no directivo (0):
Para el grupo de clase con estilo directivo (1):
No obstante, también existen programas y páginas Webs específicamente diseñadas para calcular las rectas de regresión simples, los puntos a representar gráficamente e incluso obtener las gráficas de interacción correspondientes. Entre ellos están los siguientes: a) El programa IntPlot (http://psych.unl.edu/psycrs/statpage/regression.html), que requiere codificación dummy, nos proporciona los siguientes resultados:
Una vez obtenidos los puntos a representar gráficamente podemos construir nuestra gráfica de interacción con cualquier procesador de textos que nos lo permita:
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
b) Meier (2008) proporciona una hoja de cálculo en Excel sobre la que copiar y pegar las tablas de descriptivos, coeficientes y covarianzas de los coeficientes previamente obtenidas en SPSS. En la Web http://www.urenz.ch/irse pueden obtenerse, además de la hoja de cálculo denominada IRSE, las instrucciones de SPSS necesarias para obtener el modelo de regresión. El resultado gráfico sería el siguiente:
c) Otra opción para realizar al mismo tiempo tanto los cálculos de las rectas de regresión simples como la gráfica correspondiente la proporciona el programa ModGraph, en http://www.victoria.ac.nz/psyc/paul-jose-files/modgraph/modgraph.php, (Jose, 2008):
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
Obtendríamos así los siguientes resultados:
En ellos podemos comprobar que ni la tolerancia a la ambigüedad ( p = .686) ni el tipo de clase ( p = .498) tienen una relación estadísticamente significativa con la satisfacción. A estos mismos resultados llegaríamos con el análisis de regresión eliminando el efecto interactivo, independientemente de la codificación utilizada:
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
Por su parte, en los modelos de ANCOVA el análisis de la interacción no se desarrolla para responder a una pregunta de interés teórico, sino para comprobar un supuesto, la homogeneidad de los coeficientes de regresión simples. Puesto que el objetivo es concluir sobre el efecto principal de la única VI de la investigación, la predictora categórica, hemos de probar previamente que dicho efecto no está condicionado por otro efecto superior en la jerarquía, el efecto de interacción. Ello es equivalente a comprobar que las pendientes de las rectas de regresión simples son homogéneas. Para ello debemos solicitar un modelo de ANCOVA personalizado a través del botón Modelo :
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
la variable de orden superior, la interacción. Pues bien, como ya sabemos, estas variaciones en los coeficientes de las predictoras aisladas serán drásticas si se utilizan puntuaciones directas, debido a los problemas de colinealidad que plantea la introducción de la interacción. Para reducirlos resulta preferible trabajar con puntuaciones centradas. Adicionalmente, hay que destacar que al utilizar predictoras cuantitativas centradas se produce un cambio beneficioso en la interpretación de los coeficientes de cada predictora (Aiken y West, 1992). Así, con puntuaciones directas se interpretan como pendientes de las correspondientes rectas de regresión cuando la otra variable predictora toma el valor 0; con puntuaciones diferenciales se interpretarán como pendientes de las rectas de regresión cuando la otra predictora toma como valor su media. Esta última posibilidad resulta claramente preferible, ya que el valor promedio de una variable es mucho más representativo de la muestra que el valor 0, inexistente en la práctica para muchas variables y contextos. Supongamos por ejemplo que se estudiara la relación entre el consumo de alcohol y las predictoras edad y sueldo semanal de los sujetos. Con puntuaciones directas, el coeficiente del sueldo se interpretaría en relación a una edad de 0 años, aunque obviamente no es posible consumir alcohol con esa edad. Supongamos que analizamos nuevamente la satisfacción docente en función de la tolerancia a la ambigüedad y las preferencias iniciales por un estilo educativo directivo, con todas las variables medidas cuantitativamente. Podríamos suponer que cuando la preferencia por el estilo educativo directivo es baja (porque se prefiere el no directivo), la satisfacción docente será mayor cuanto mayor sea la tolerancia a la ambigüedad, mientras que esta relación puede cambiar o incluso invertirse con una alta preferencia por dicho estilo directivo. Para obtener nuestro análisis debemos centrar ambas predictoras cuantitativas, restándole a cada una su media:
A continuación calcularemos la variable producto de ambas predictoras centradas. Los resultados obtenidos incluirán los siguientes:
Como puede comprobarse, la introducción del componente de interacción no altera demasiado los coeficientes de las predictoras aisladas, gracias a la utilización de puntuaciones centradas de las predictoras. Por su parte, el componente de interacción
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
resulta estadísticamente significativo, por lo que debe tenerse en cuenta en la ecuación de regresión.
2.2. Profundizando en el análisis de una interacción significativa Una vez centradas las variables predictoras y detectada como significativa una interacción, debemos interpretarla. El primer paso en esta interpretación puede ser observar el signo del coeficiente de regresión parcial para la interacción. Como ya se ha comentado, si es positivo indicaría que a medida que aumenta una variable predictora, la relación entre la VD y la otra predictora se hace más positiva. Si es negativo indica lo contrario, que a medida que aumenta una variable predictora, la relación entre la VD y la otra predictora se hace menos positiva, pudiendo incluso llegar a ser negativa. En nuestro ejemplo, dicho coeficiente es negativo, -.024, por lo que habría una relación menos positiva entre la satisfacción y la tolerancia a la ambigüedad con niveles bajos de preferencia por un estilo directivo. Veamos cómo podemos analizar a posteriori este patrón de resultados. En general, la existencia de un componente de interacción estadísticamente significativo indica que no debemos explicar la relación entre una VI y la VD a través de una única recta de regresión promedio. La pendiente de esta recta de regresión promedio vendría determinada por el coeficiente b de cada variable aislada. Pero la existencia de una interacción significativa nos indica que la relación entre cada predictora y la VD cambia en función de los valores que vaya tomando la otra predictora. Para revelar dichos cambios bastará con conocer las rectas de regresión simples de la VD sobre una de las predictoras para diferentes valores de la otra predictora, habitualmente su media y ± una desviación tipo. Adicionalmente, podemos probar si las pendientes de estas rectas de regresión simples son o no diferentes de 0, de forma equivalente a como se prueban a posteriori los efectos simples en los modelos de ANOVA. Supongamos que queremos analizar las rectas de regresión simples de la satisfacción docente sobre la tolerancia a la ambigüedad para diferentes valores de la preferencia por la enseñanza no directiva. La recta de regresión simple para el valor medio de preferencia la obtenemos a partir de la ecuación general, dada la interpretación de los coeficientes con variables centradas:
satisfacción’ = 4.264 - .008(ctolerancia) Para completar el análisis bastará con calcular las rectas de regresión simples para valores bajos y altos de preferencia. Para ello aplicaremos una nueva transformación aditiva de las variables originales, de forma que obtengamos valores de 1 desviación tipo por debajo y por encima de la media. Sabiendo que la media y la desviación tipo de la tolerancia son respectivamente 5.50 y 2.91, las nuevas variables serían las siguientes (A = alta; B = baja; C = centrada):
A continuación volveremos a calcular las correspondientes variables producto:
Una vez confeccionado el nuevo archivo de datos, bastará con pedirle a SPSS la elaboración de dos modelos de regresión lineal con la satisfacción como variable
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
Para una preferencia alta:
0
1
2
3
4
5
6
7
-17,52 0 17,
S a t i s f a c c i ó n
Tolerancia a la ambiguedad
Preferencia baja Preferencia media Preferencia alta
No obstante, también es posible obtener estos mismos datos, y en ocasiones las representaciones gráficas correspondientes, prescindiendo del cálculo manual. Para ello pueden utilizarse diferentes herramientas ya conocidas: a) IntPlot: http://psych.unl.edu/psycrs/statpage/regression.html b) IRSE (Meier, 2008): http://www.urenz.ch/irse c) ModGraph (Jose, 2008): http://www.victoria.ac.nz/psyc/paul-jose-files/modgraph/modgraph.php d) Hojas de cálculo de Jeremy Dawson: http://www.jeremydawson.co.uk/slopes.htm Por ejemplo, con IntPlot obtendríamos aproximadamente los mismos puntos calculados previamente de forma manual para la representación gráfica de nuestra interacción, además del punto de corte entre las tres rectas de regresión diferentes (2.875):
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
2.4. Coeficientes estandarizados Aiken y West (1992) también ponen de manifiesto la imposibilidad de interpretar los coeficientes estandarizados cuando se introducen términos de interacción en el modelo de regresión. Ello se debe a que no es lo mismo estandarizar la variable producto ZX que el producto de las variables previamente estandarizadas Z y X. En caso de querer obtener coeficientes estandarizados, los autores proponen, de acuerdo con Friedrich (1982), estandarizar previamente todas las variables, incluida la variable criterio, obtener el producto de las dos variables predictoras estandarizadas y calcular los coeficientes de regresión para las nuevas variables, que en este caso serán interpretados como coeficientes de regresión estandarizados^1. En SPSS podemos estandarizar las variables solicitando Analizar: Estadísticos descriptivos: Descriptivos y seleccionando la opción Guardar valores tipificados como variables.
3. Interacción entre variables categóricas Cuando contamos con más de una variable categórica es posible que no contemos con observaciones de todas las combinaciones de valores de las variables. Esta situación será usual en las investigaciones correlacionales, donde el investigador/a no interviene en la administración de los valores de las variables a los sujetos y por tanto, éstas pueden estar correlacionadas. Por ejemplo, supongamos que recogemos datos sobre el nivel de formación de los sujetos y sobre su zona de residencia. Sería perfectamente posible que determinadas zonas de residencia, por ejemplo el medio rural, no cuente con personas del nivel de formación más alto, cuya vida laboral suele requerir la residencia en el medio urbano. Sin embargo, en otras ocasiones sí
(^1) El coeficiente de regresión b 0 no será igual a 0 debido a que la media de la variable producto no tomará este valor.
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
En la codificación de efectos existe correlación entre los dos vectores que representan al método, entre los dos que representan al medio y entre los cuatro que representan a la interacción entre ambas variables. Sin embargo, los vectores de A, B y AB son independientes entre sí. Gracias a ello, cada grupo de vectores nos proporcionará información sobre un componente independiente de la variación total y la secuencia en la que se introduzcan los grupos de vectores no influirá en los resultados. Si hubiésemos desarrollado un modelo de ANOVA factorial habríamos obtenido los siguientes resultados:
Como puede observarse, sólo resultan estadísticamente significativos los efectos principales de las variables medio ( p = .001) y método ( p = .000), pero no la interacción entre ellas ( p = .696). Para llegar a conclusiones similares utilizando el análisis de regresión podemos introducir cada grupo de vectores en un paso diferente y evaluar la significación estadística del incremento en R^2 cuando se introduce cada grupo de vectores en el modelo:
Así, podemos comprobar cómo se produce un cambio significativo cuando se introducen los vectores que representan al efecto principal del método de enseñanza ( p = .002), vuelve a producirse un cambio significativo cuando se introducen los correspondientes al efecto principal del medio en el que residen los sujetos ( p = .000), pero no ocurre lo mismo cuando se introducen los vectores correspondientes a la interacción ( p = .696). No obstante, hay que tener en cuenta que estas significaciones, excepto la última, no coinciden exactamente con las calculadas el modelo de ANOVA, debido a la diferencia en los grados de libertad del error. Mientras que en el ANOVA
ANÁLISIS DE LA INTERACCIÓN A TRAVÉS DE LA REGRESIÓN
los tres efectos se prueban con 9 grados de libertad del error, en la tabla anterior sólo el tercero de los modelos sometidos a prueba, que contiene a todos los vectores, cuenta con estos grados de libertad. Para obtener las pruebas de significación equivalentes a las del ANOVA a través del análisis de regresión deberíamos repetir el proceso de comparación de modelos incluyendo en último lugar el efecto que nos interese en cada momento.
3.2. Codificación ortogonal Supongamos que queremos comparar los dos primeros métodos entre sí y estos dos unidos frente al método tres, y que también queremos comparar los dos primeros medios entre sí y ellos dos unidos frente al tercero. Estas comparaciones ortogonales darían lugar al siguiente archivo de datos:
La principal característica de la codificación ortogonal es que ahora todos los vectores son independientes entre sí, incluso los dos pertenecientes al efecto principal de cada variable y los cuatro de interacción entre sí. Gracias a ello cada coeficiente de regresión se corresponderá con un efecto independiente y podremos comprobar la significación de cada comparación de medias particular introduciendo todos los vectores en un único paso. Observaremos así cómo existen diferencias estadísticamente significativas entre los métodos primero y segundo ( p = .005), entre estos dos unidos frente al tercero ( p = .000), entre los dos primeros medios ( p = .022), y entre ellos y el tercero ( p = .001). En cambio, ninguno de los contrastes de interacción incluidos en el modelo resultó estadísticamente significativo: