¡Descarga Multiprocesadores de memoria compartida y más Apuntes en PDF de Ingeniería del Software solo en Docsity!
Tema 10: Multiprocesadores de memoria compartida
Introducción al procesamiento paralelo
p
p
Estructura de los multiprocesadores de memoria compartida
Medio de interconexión de los procesadores con la memoria
C
i t
i
d
i
hé
Consistencia de memoria caché
Modelo de programación
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Fuentes de paralelismo en los programas
En relación con la explotación del paralelismo para su traducción en mejora de rendimiento
p
p
p
j
las aplicaciones (programas) manifiestan tres tipos:
Paralelismo de control
Paralelismo de datos
Paralelismo de flujo
El
paralelismo de control
proviene del hecho de que determinadas sub-tareas de la
aplicación son independientes y en consecuencia pueden realizarse en paraleloaplicación son independientes y en consecuencia pueden realizarse en paralelo(simultáneamente).
Los elementos de proceso se asocian a las sub-tareas independientes
El
paralelismo de datos
proviene del hecho de que ciertas aplicaciones trabajan con
estructuras de datos muy regulares (vectores y matrices), repitiendo una misma acción sobrecada elemento de la estructura.
Los elementos de proceso se asocian a los datos elementales de las estructuras.
El
paralelismo de flujo
proviene del hecho de que ciertas aplicaciones funcionan como un
fl j
d
d t
b
l
d b
f
t^
ió
d
i^
d
( t
flujo de datos sobre el que debe efectuarse una sucesión de operaciones en cascada (etapas).
Los elementos de proceso se asocian a las múltiples etapas de la aplicación.
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Clasificación de los multiprocesadores por la ubicación de la memoria
Multiprocesadores de
memoria compartida
Multiprocesadores
de memoria compartida
Todos los procesadores acceden a una memoria común
La comunicación entre procesadores se hace a través de la memoria
Se necesitan primitivas de sincronismo para asegurar el intercambio de datos
P
1
P
n
R d d
i t
ió
di á
i
P
2
Red de interconexión dinámica
Memoria compartida
Multiprocesadores de memoria distribuida o multicomputadores
Cada procesador tiene su propia memoria
La comunicación se realiza por intercambio explicito de mensajes a través de una red
p
p
j
M^ P
1
M P
1
M P
1
P^1 Red de interconexión estática
P
1
P
1
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
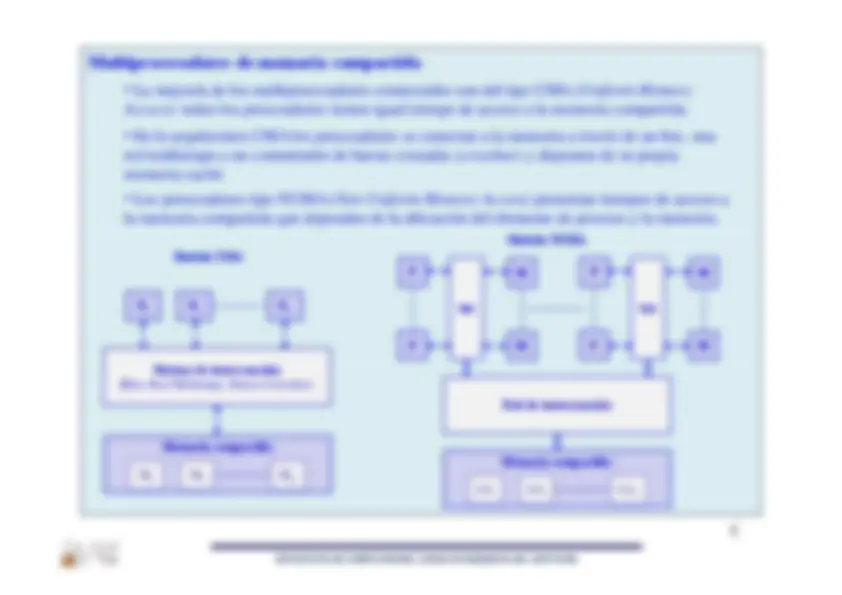
Multiprocesadores de memoria compartida
La mayoría de los multiprocesadores comerciales son del tipo UMA (
Uniform
Memory
La
mayoría de los multiprocesadores comerciales son del tipo UMA (
Uniform
Memory
Access
): todos los procesadores tienen igual tiempo de acceso a la memoria compartida.
En la arquitectura UMA los procesadores se conectan a la memoria a través de un bus, una red multietapa o un conmutador de barras cruzadas (
crossbar
y disponen de su propia
p
) y
p
p
p
memoria caché. •
Los procesadores tipo NUMA (
Non Uniform Memory Access
) presentan tiempos de acceso a
la memoria compartida que dependen de la ubicación del elemento de proceso y la memoria.
Modelo UMA
M
P
M
P
Modelo NUMA
P
1
P
n
P
2
Red
M
P
Red
M
P
Sistema de interconexión
( Bus, Red Multietapa, Barras Cruzadas)
Red de interconexión
Memoria compartida
M
1
M
m
M
2
Memoria compartida
MG
1
MG
m
MG
2
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolos de transferencia síncronos
- Existe un reloj que gobierna todas las actividades del bus, las cuales tienen lugar en unnúmero entero de ciclos de reloj.• La transferencia coincide con uno de los flancos del reloj (el de bajada en el ejemplo de la
La transferencia coincide con uno de los flancos del reloj (el de bajada en el ejemplo de la figura)
ciclo 2
ciclo 3
ciclo 1
ciclo-
ciclo-
ciclo-
Reloj
tiempo de establecimientotiempo de mantenimiento
Dirección
R/W
Datos
Escritura
Lectura
Escritura
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolos de transferencia semisíncronos
Existe un reloj que gobierna las transferencias en el bus.
j q
g
Existe
una
señal
de
espera
wait
que
es
activada
por
el
slave
(memoria)
cuando
la
transferencia va a durar más de un ciclo de reloj. •
Los
dispositivos
rápidos
operarán
como
en
bus
síncrono
mientras
que
los
lentos
alargarán
la
Los
dispositivos
rápidos
operarán
como
en
bus
síncrono
, mientras que los lentos alargarán la
operación el número de ciclos que les sea necesario.
Reloj Dirección
Datos
Lectura
Espera
Escriturasíncrona
Lecturasíncrona
Escrituraasíncrona
Lectura asíncrona
8
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolos de arbitraje
Organizan
el
uso
compartido
del
bus
garantizando
que
en
un
momento
determinado
el
Organizan
el
uso
compartido
del
bus
garantizando
que
en
un
momento
determinado
el
acceso al bus es realizado por un solo
procesador
Para ello se establecen prioridades cuando más de un procesador requiere su utilización
Existen dos grupos de protocolos de arbitraje, los
centralizados
y los
distribuidos
Centralizados:
existe una unidad de arbitraje (
árbitro del bus
) encargado de gestionar de
forma centralizada el uso del busforma centralizada el uso del bus. •
El árbitro puede ser una unidad físicamente independiente o estar integrado en otra unidad, por ejemplo, uno de los proceadores. •
Estudiaremos dos alternativas:
Encadenamiento de 3 señales
d
i
d
l
Encadenamiento de 4 señales
Distribuidos:
no existe ninguna unidad especial para la gestión del bus.
El arbitraje se realiza de forma distribuida entre todos los procesadores.
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolo de encadenamiento (
daisy chaining)
de tres señales
Utiliza tres líneas para gestionar el arbitraje:
p
etición
,^
ocupación y concesión
p
g
j
p
,^
p
y
La línea de
petición
es compartida por todos los
procesadores
a través de una entrada al
árbitro con capacidad de O-cableada. •
Cuando
un
procesador
toma
el
control
del
bus
activa
la
línea
de
ocupación
Cuando
un
procesador
toma
el
control
del
bus
activa
la
línea
de
ocupación
El árbitro activa la
concesión
cuando recibe una
petición
y la de
ocupación
está desactivada.
Si un procesador recibe la
concesión
y no ha solicitado el bus, transmite la señal al siguiente.
U
d
t
l
t
l d l b
i ti
i ió
l
l^
di
t^
l^
lí
d
U
n procesador toma el control del bus si tiene una
petición
l
ocal pendiente, la línea de
ocupación
está desactivada y recibe el flanco de subida de la señal de
concesión
P
P
Pn
concesión
ti ió
ARBITRO
petic ión ocupación
BUSBUS
11
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolo de arbitraje distribuido
La responsabilidad del arbitraje se distribuye por los diferentes
p
rocesadores
conectados al bus.
p
j^
y
p
p
R
G
R
G
R
G
Rn
Gn
P
P
P
Pn
Bucle de prioridad
ocupación
p
G
p
G
p
Rn
pn
Arbitro 1
Arbitro 2
Arbitro 3
Arbitro n
Arbitro-i concede el bus al
procesador Pi
activando
Gi
si:
Pi
h
ti
d
lí
d
ti ió
d
b
Ri
Pi
h
a activado su línea de petición de bus
Ri
La línea de ocupación está desactivada.
La línea de entrada de prioridad
pi-
está activada
El árbitro
i
activa su línea de prioridad
pi
si:
El árbitro
i
activa su línea de prioridad
pi
si:
Pi
no ha activado su línea de petición
Ri
La línea de prioridad
pi-
está activa
Finaliza una operación de acceso al bus
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Multiprocesadores de memoria compartida: conexión por conmutadores
crossbar
Cada procesador (
Pi
) y cada módulo de memoria (
Mi
) tienen su propio bus
Cada
procesador (
Pi
) y cada módulo de memoria (
Mi
) tienen su propio bus
Existe un conmutador (
S
) en los puntos de intersección que permite conectar un bus de
memoria con un bus de procesador •
Para evitar conflictos cuando más de un procesador pretende acceder al mismo módulo dePara
evitar conflictos cuando más de un procesador pretende acceder al mismo módulo de
memoria se establece un orden de prioridad •
Se trata de una red sin bloqueo con una conectividad completa pero de alta complejidad
P
0
Buses de memoria
P
1
S S^
S S
S S
rocesadores
Pi
Elemento de proceso
P
n
S^
S^
S
Buses de pr
M
j^
Módulo de memoriaConmutador (Switch)
M
0
M
1
M
n
S^
S
S
S
Conmutador
(Switch)
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Ejemplo de rede multietapa: red Omega (
Se trata de una red multietapa compuesta de conmutadores básicos de 2 entradas y 2 salidas
p
p
y
Cada conmutador puede estar en dos estados:
paso
directo
y
cruce
Conmutador básico
Cada conmutador puede estar en dos estados:
paso
directo
y
cruce
1
Cruce
0
Paso directo
La interconexión entre etapas se realiza con un patrón fijo denominado
barajadura perfecta.
La red de 3 etapas que conecta 8 procesadores con 8 módulos de memoria sería la siguiente:
M
0 M
1
P
(^0) P^1
Etapa 2
Etapa 1
Etapa 0
M
2 M
3 M
4
P
2 P
3 P
4
M
5 M
6 M
7
P
5 P
6 P
7
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Encaminamiento en la red Omega
Algoritmo 1:
2
1
0
,^
,^
d
d
d
índice en binario del módulo de memoria destino
2
1
0
i i d
Conexión de entrada a salida superior
Etapa i si
d
Conexión de entrada a salidainferior
Algoritmo 2:
2
1
0
2
1
0
,^
,^
,^
,^
f
f^
f^
índice en binario del procesador fuente
d
d
d
índice en binario del módulo de memoria destino
^
i^
i
i^
i
d
f
Conexión de paso directo
Etapa i si
d
f
Conexión de cruce
d
=0 2
Conexión superior^ (0 0 1)
d
=1 1
Conexión inferior
d
=1 0
Conexión superior
(0 1 0)(0 0 1)
f^0
= d
0
p
aso directo
f^2
= d
2
paso directo
0
0
p
f^1
≠
d
1
paso cruce
etapa 2
etapa 1
etapa 0
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Solución de la coherencia caché
Existen dos formas de abordar el problema de la coherencia caché.
p
Software, lo que implica la realización de compiladores que eviten la incoherencia entre cachés de datos compartidos.
Hardware que mantengan de forma continua la coherencia en el sistema, siendo además
q
g
transparente al programador.
Podemos distinguir también dos tipos de sistemas multiprocesadores
Sistemas basados en un único bus: se utilizan protocolos de sondeo o
snoopy
que
analizan el bus para detectar incoherencia. Cada nodo procesador tendrá los bitsnecesarios para indicar el estado de cada línea de su caché y así realizar las transaccionesde coherencia necesarias según lo que ocurra en el bus en cada momento.
Si
d
l i
l^
b
d
di
i^
i
l
Si
stemas con redes multietapa: protocolo basado en directorio, que consiste en la
existencia de un directorio común donde se guardan el estado de validez de las líneas delas cachés, de manera que cualquier nodo puede acceder a este directorio común.
Tanto si son de sondeo como si no, existen dos políticas para mantener la coherencia:
Invalidación en escritura (write invalidate):
siempre que un procesador modifica un
dato de un bloque en la caché, invalida todas las demás copias de ese bloque guardadasen las otras cachés.
Actualización en escritura (write update):
actualiza las copias existentes en las otras
cachés en vez de invalidarlas.
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE
Protocolos de sondeo (snoopy)
P
l^
MSI
l
d
i^
lid
ió
hé
i
P
rotocolo MSI: protocolo de invalidación para cachés post-escritura.
Utiliza los siguientes estados:
inválido
(I),
compartido
(S) y
modificado
(M).
Inválido: tiene un significado inmediato.
Compartido: el bloque está presente en la caché y no ha sido modificado, la memoria principal está actualizada y cero o más cachés adicionales pueden tener también unacopia actualizada (compartida).
M difi
d
ú i
d
i^
i^
álid
d l bl
hé
M
odificado: únicamente este procesador tiene una copia válida del bloque en su caché,
la copia en la memoria principal está anticuada y ninguna otra caché puede tener unacopia válida del bloque.
Antes de que un bloque compartido pueda ser escrito y pasar al estado modificado todas las
Antes de que un bloque compartido pueda ser escrito y pasar al estado modificado, todas las demás copias potenciales deben de ser invalidadas vía una transacción de bus de lecturaexclusiva. •
Esta transacción sirve para ordenar la escritura al mismo tiempo que causa la invalidacionesEsta
transacción sirve para ordenar la escritura al mismo tiempo que causa la invalidaciones
y por tanto asegura que la escritura se hace visible a los demás. •
El procesador emite dos tipos de peticiones: lecturas (
PrRd
) y escrituras (
PrWr
Las lecturas o escrituras pueden ser a un bloque de memoria que existe en la caché o a unoLas
lecturas o escrituras pueden ser a un bloque de memoria que existe en la caché o a uno
que no existe. En el último caso, el bloque que esté en la caché en la actualidad seráreemplazado por el nuevo bloque, y si el bloque actual está en el estado modificado sucontenido será volcado a la memoria principal.
ESTRUCTURA DE COMPUTADORES. GRADO EN INGENIERIA DEL SOFTWARE