



Pandas –Introducción








Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
El Data Science es un campo interdisciplinario que involucra métodos científicos para extraer conocimiento de datos. En este documento, se presenta una revisión de Pandas, una biblioteca de software escrita como extensión de NumPy para manipulación y análisis de datos en Python. Se explica el objetivo de Pandas, sus componentes principales Series y DataFrames, y sus características. Además, se incluyen pasos para instalar y importar Pandas, así como cómo crear y manipular Series y DataFrames.
Tipo: Apuntes
1 / 25

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
El Data Science es un campo interdisciplinario que involucra métodos científicos, procesos y sistemas para extraer conocimiento o un mejor entendimiento de datos en sus diferentes formas, ya sea estructurados o no estructurados, lo cual es una continuación de algunos campos de análisis de datos como la estadística, la minería de datos, el aprendizaje automático y la analítica predictiva. El Data Science combina software, estadística, matemática, programación y visualización. Y su objetivo es extraer datos factibles de interpretarse e incluso crear nueva información. Las conclusiones que se obtienen permiten desarrollar productos demandados en el mercado o generar oportunidades de negocio de una empresa.
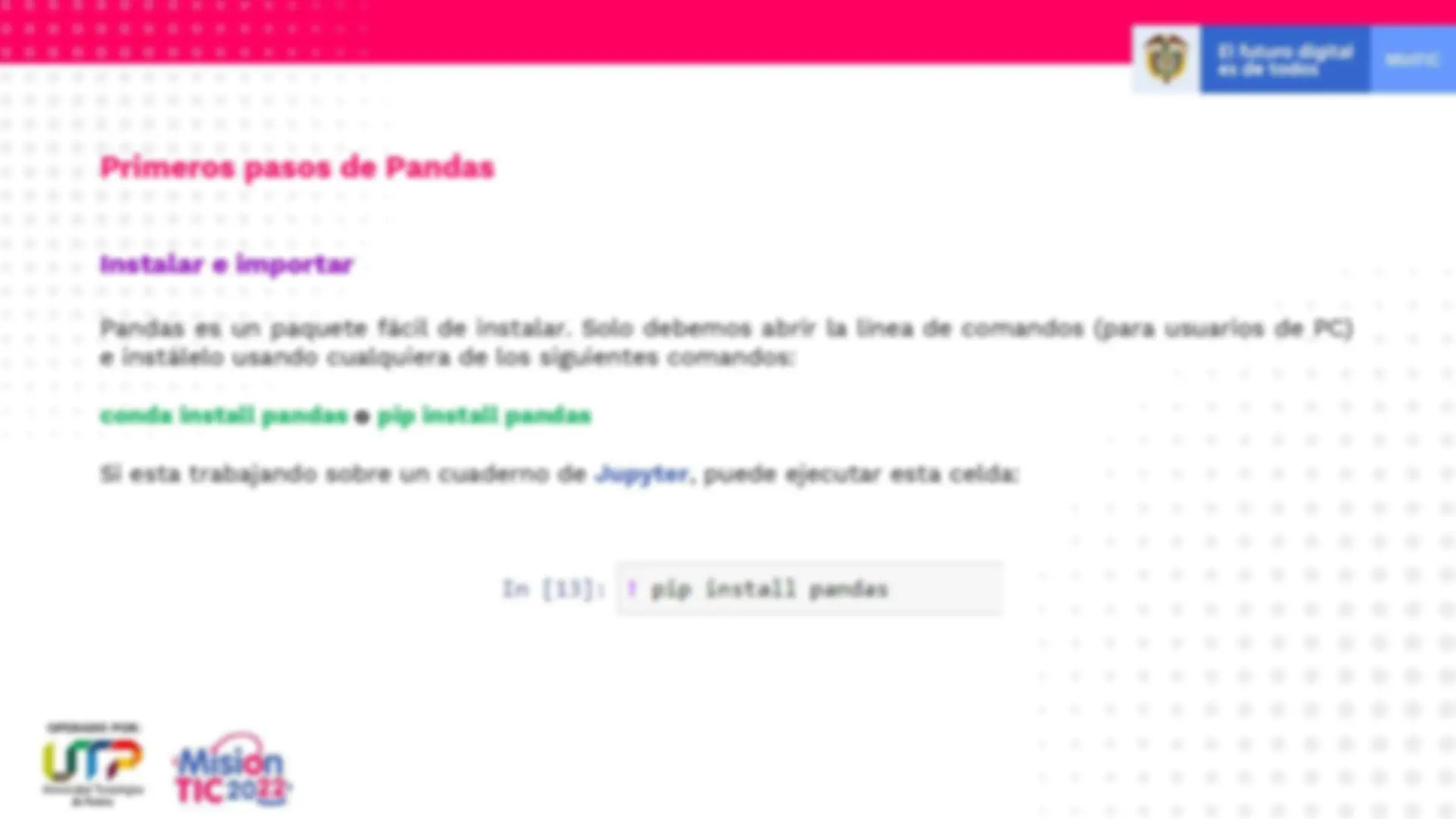
Pandas es un paquete fácil de instalar. Solo debemos abrir la línea de comandos (para usuarios de PC) e instálelo usando cualquiera de los siguientes comandos: conda install pandas o pip install pandas Si esta trabajando sobre un cuaderno de Jupyter , puede ejecutar esta celda:
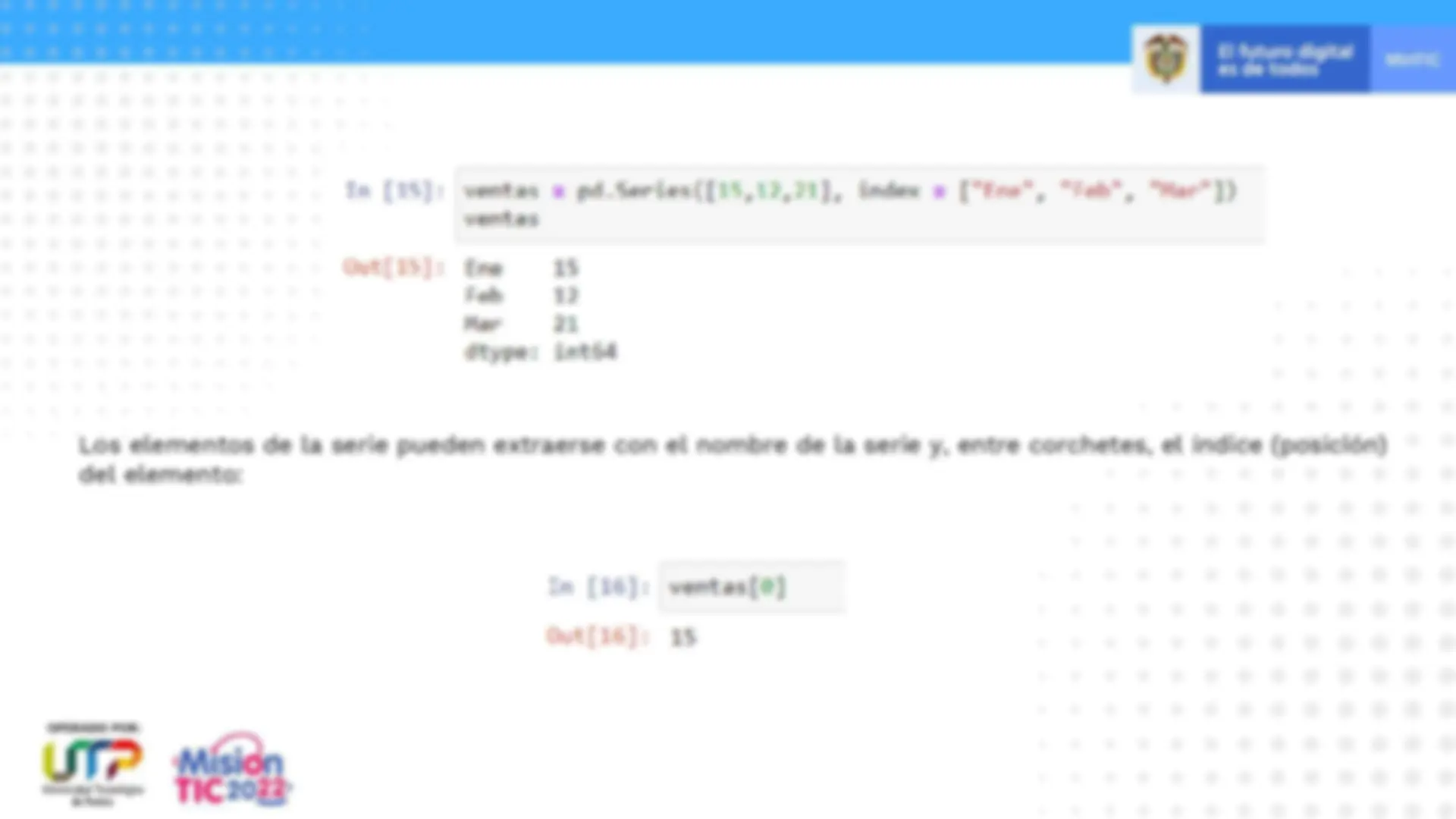
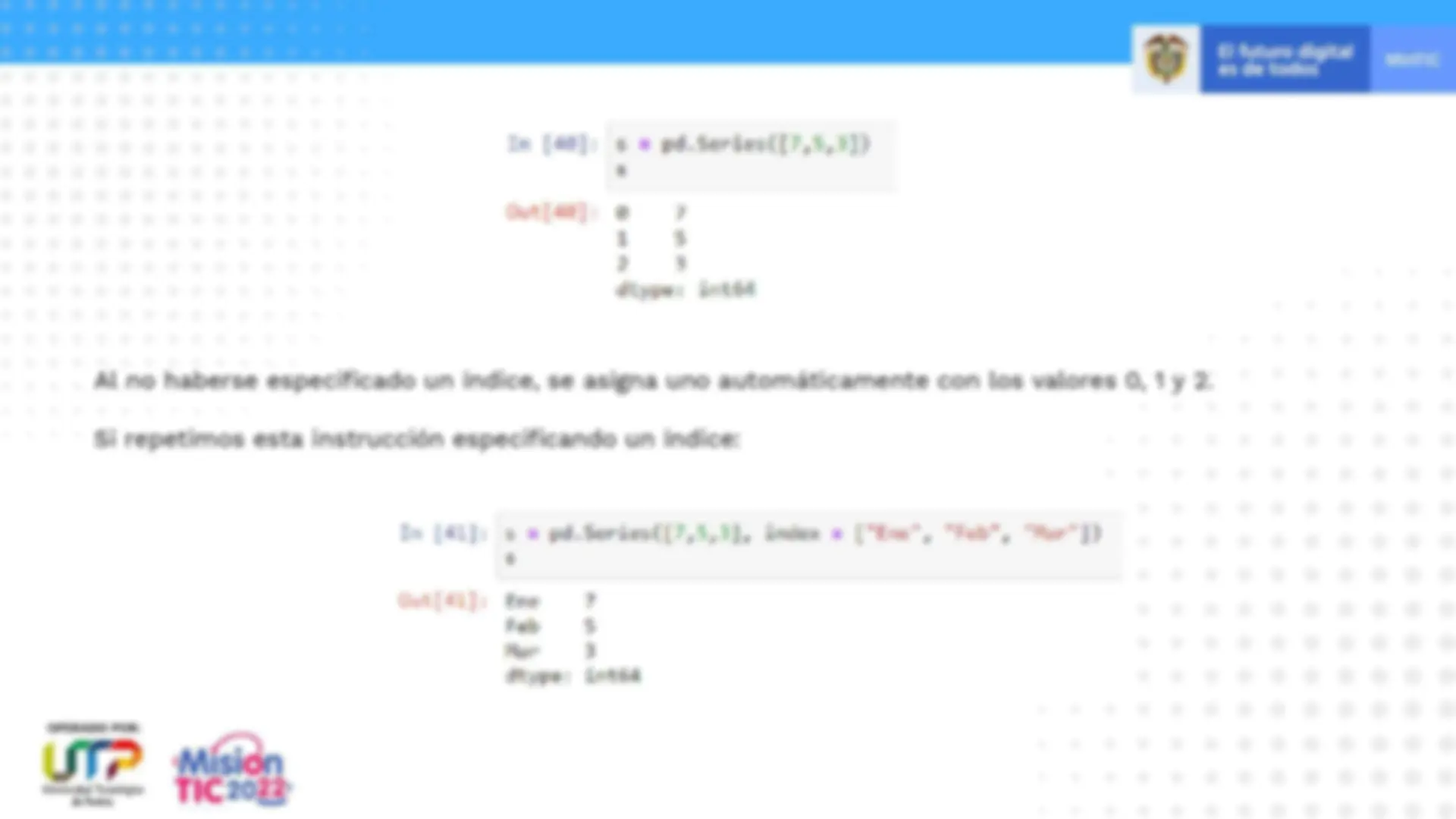
Las series son estructuras unidimensionales conteniendo un array de datos (de cualquier tipo soportado por NumPy ) y un array de etiquetas que van asociadas a los datos, llamado índice ( index en la literatura en inglés):
Los elementos de la serie pueden extraerse con el nombre de la serie y, entre corchetes, el índice (posición) del elemento:
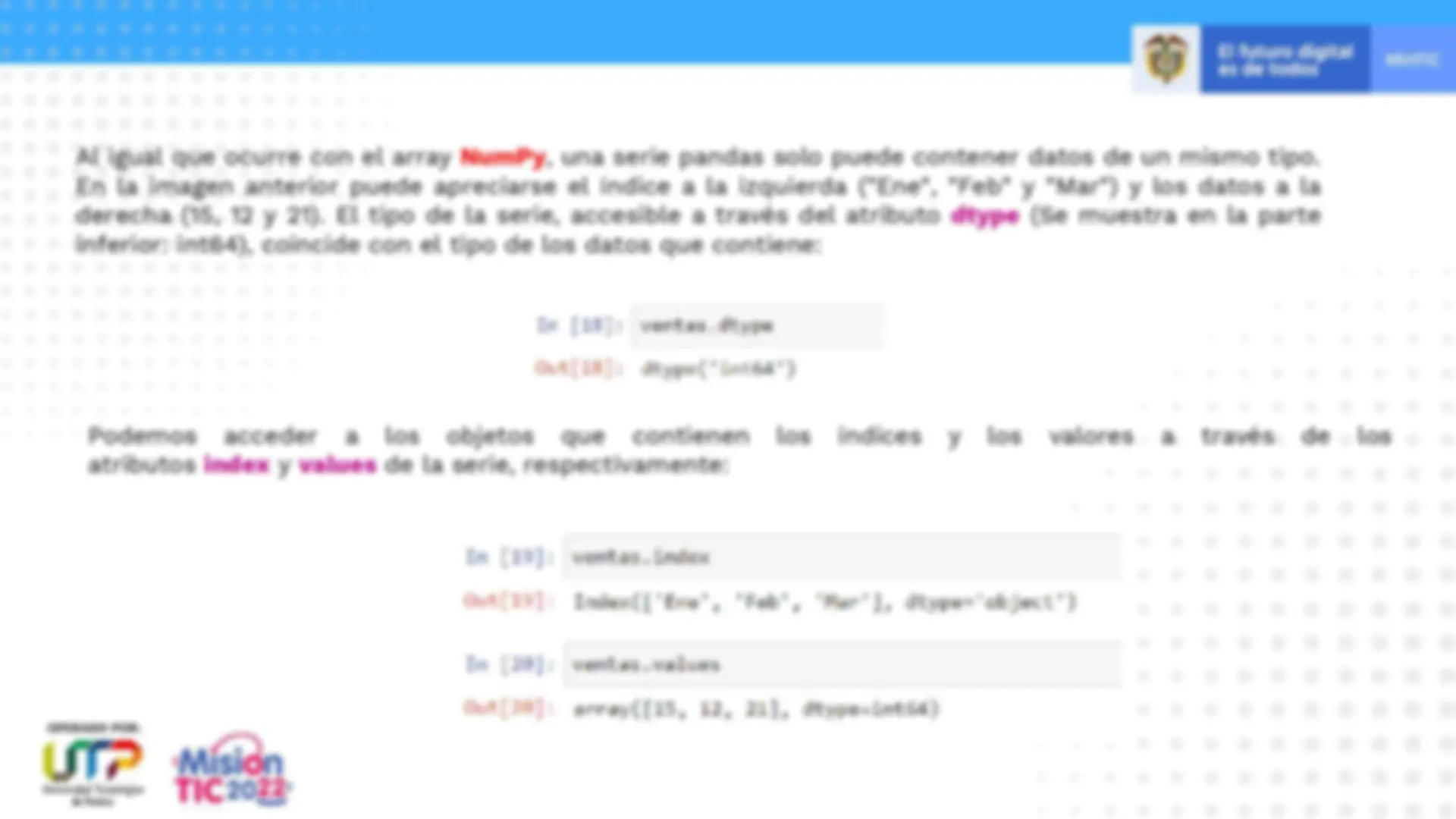
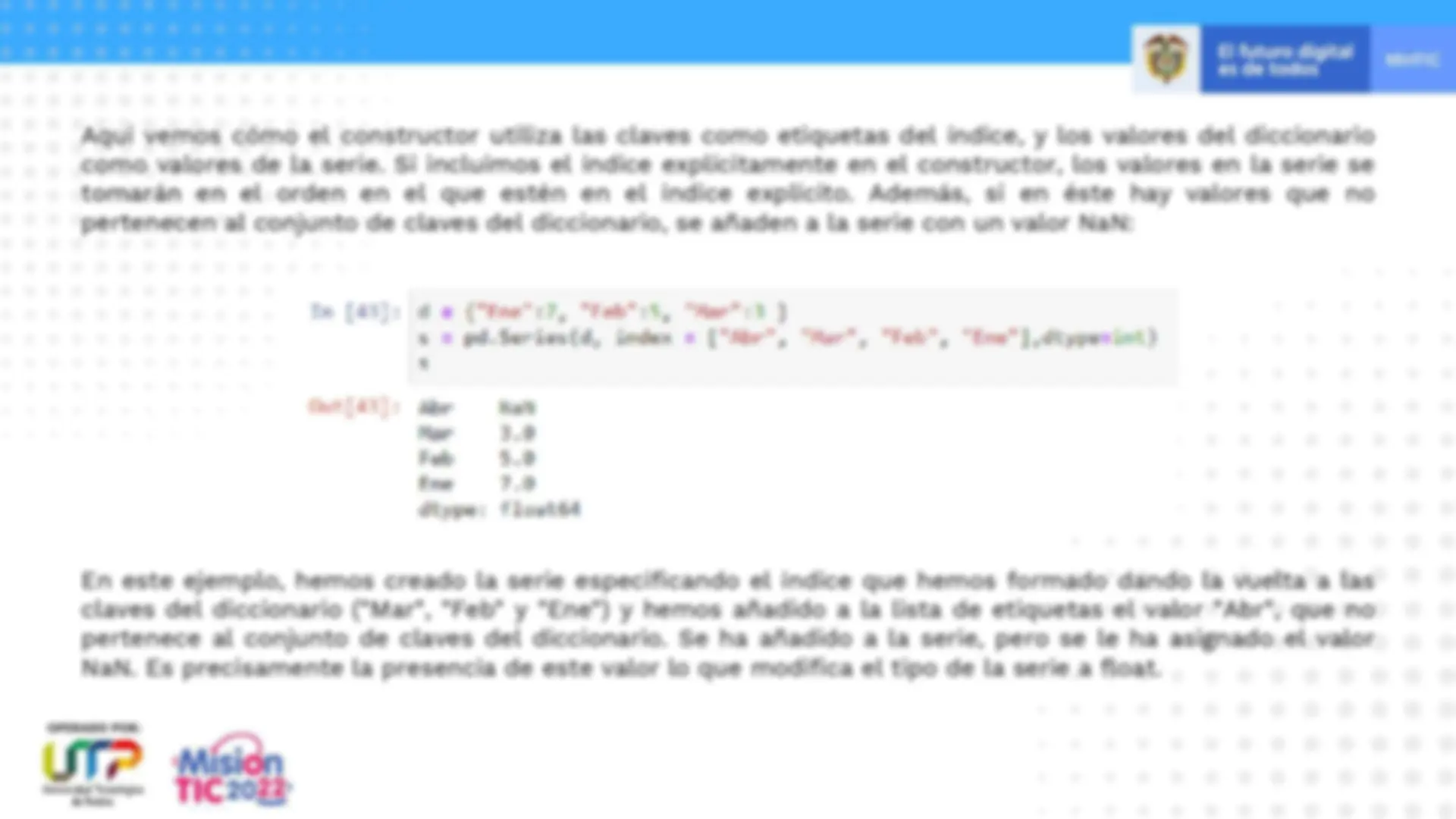
Al igual que ocurre con el array NumPy , una serie pandas solo puede contener datos de un mismo tipo. En la imagen anterior puede apreciarse el índice a la izquierda ("Ene", "Feb" y "Mar") y los datos a la derecha ( 15 , 12 y 21 ). El tipo de la serie, accesible a través del atributo dtype (Se muestra en la parte inferior: int 64 ), coincide con el tipo de los datos que contiene: Podemos acceder a los objetos que contienen los índices y los valores a través de los atributos index y values de la serie, respectivamente:
Puede apreciarse en el ejemplo que el índice es de tipo "objeto". La serie tiene, además, un atributo name, atributo que también encontramos en el índice. Una vez los hemos fijado, se muestran junto con la estructura al imprimir la serie:
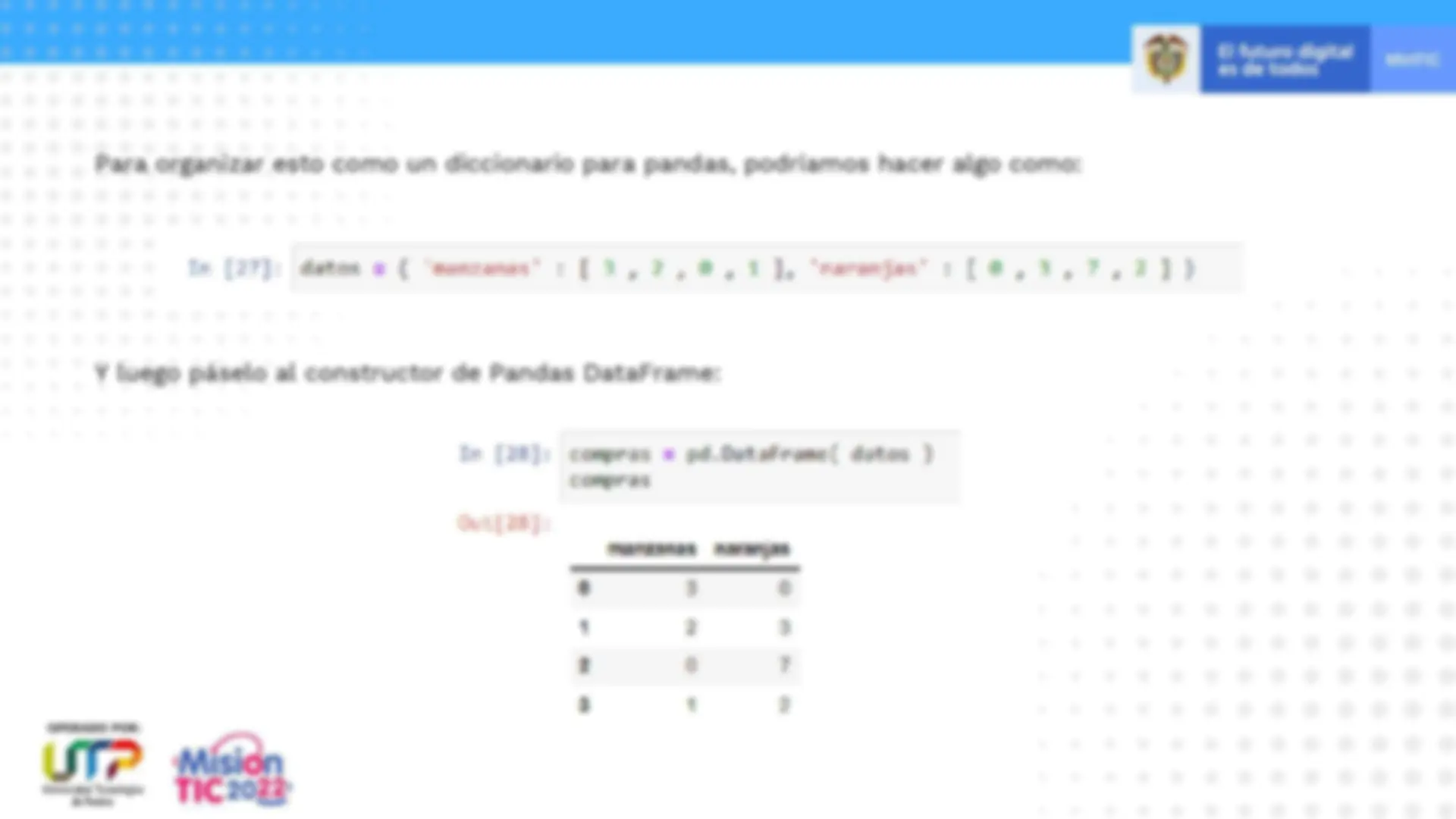
Crear DataFrames directamente en Python y es bastante útil cuando se prueban nuevos métodos y funciones que se encuentran en los documentos de pandas. Hay muchas formas de crear un DataFrame desde cero, pero una gran opción es usar un simple dict. Digamos que tenemos un puesto de frutas que vende manzanas y naranjas. Queremos tener una columna para cada fruta y una fila para cada compra del cliente.
Para organizar esto como un diccionario para pandas, podríamos hacer algo como: Y luego páselo al constructor de Pandas DataFrame:
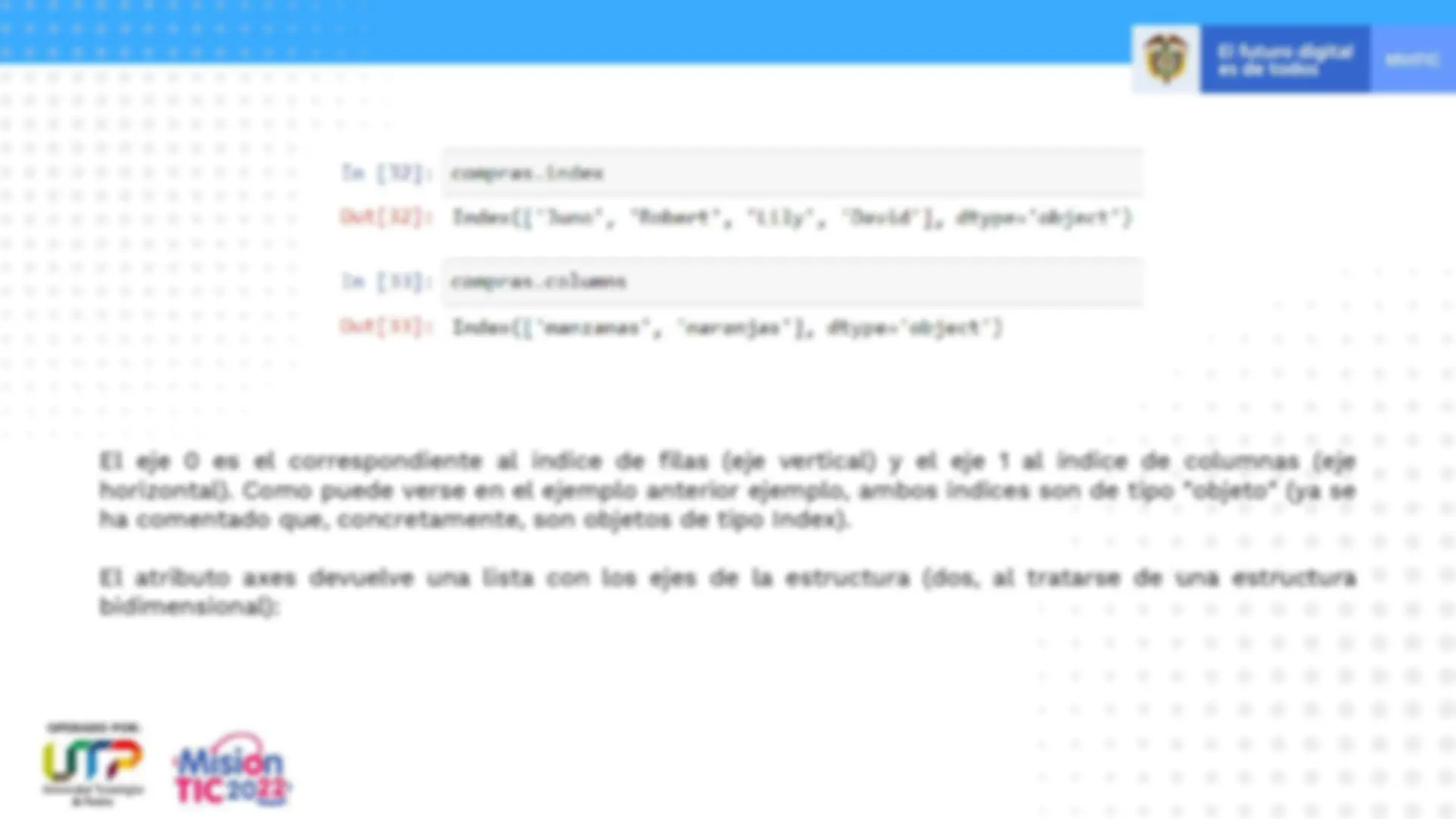
Las etiquetas de filas y de columnas - los índices- son accesibles a través de los atributos index y columns, respectivamente: La nomenclatura usada por pandas puede resultar un tanto confusa en lo que se refiere a los índices: tanto la estructura que contiene las etiquetas de filas como la que contiene las etiquetas de columnas son objetos de tipo Index ("índice", en español), pero, como se ha comentado, el índice de filas se denomina también index (aunque en minúsculas), y el de columna, columns.
Así, el índice del elemento "a" en la lista mencionada es 0 , y el índice del elemento "b" es 1 , lo que no es del todo coherente con el concepto de "índice" de una estructura pandas cuando lo especificamos explícitamente. Para evitar esta confusión, hablaremos normalmente de "índices" (en plural) para referirnos a estas dos estructuras (de filas y columnas), de "índice" (en singular) para referirnos al índice de etiquetas del eje vertical, y de "índice de columnas" y de "índice de filas" siempre que sea necesario remarcar a cuál estamos refiriéndonos. Además, el nombre de "indice" se aplica normalmente a la referencia de un dato en una estructura según su posición. Por ejemplo, en la lista m = ["a", "b"], el índice del primer elemento es el número o valor que, añadido entre corchetes tras el nombre de la lista , nos permite acceder al elemento.
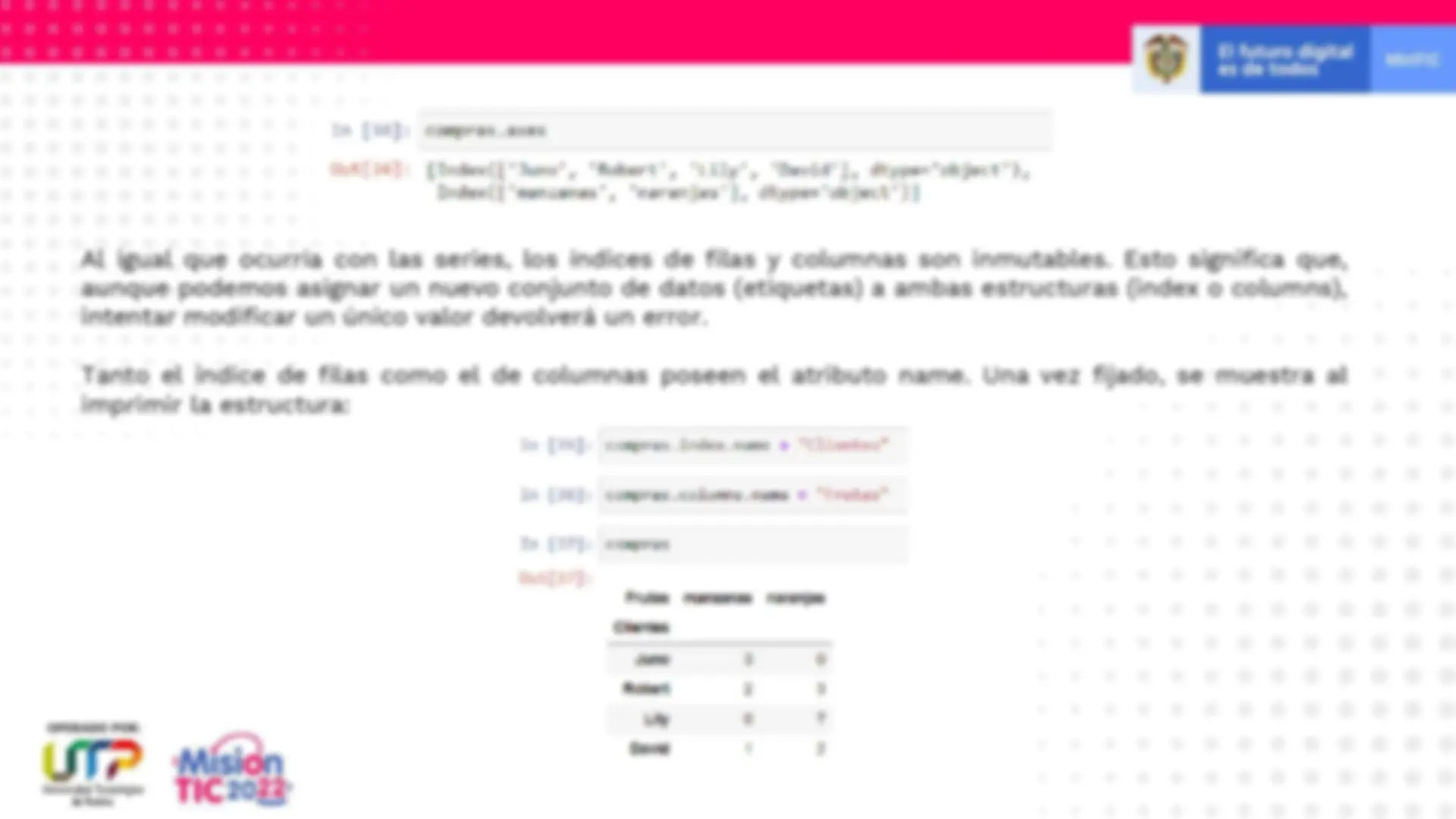
Al igual que ocurría con las series, los índices de filas y columnas son inmutables. Esto significa que, aunque podemos asignar un nuevo conjunto de datos (etiquetas) a ambas estructuras (index o columns), intentar modificar un único valor devolverá un error. Tanto el índice de filas como el de columnas poseen el atributo name. Una vez fijado, se muestra al imprimir la estructura:
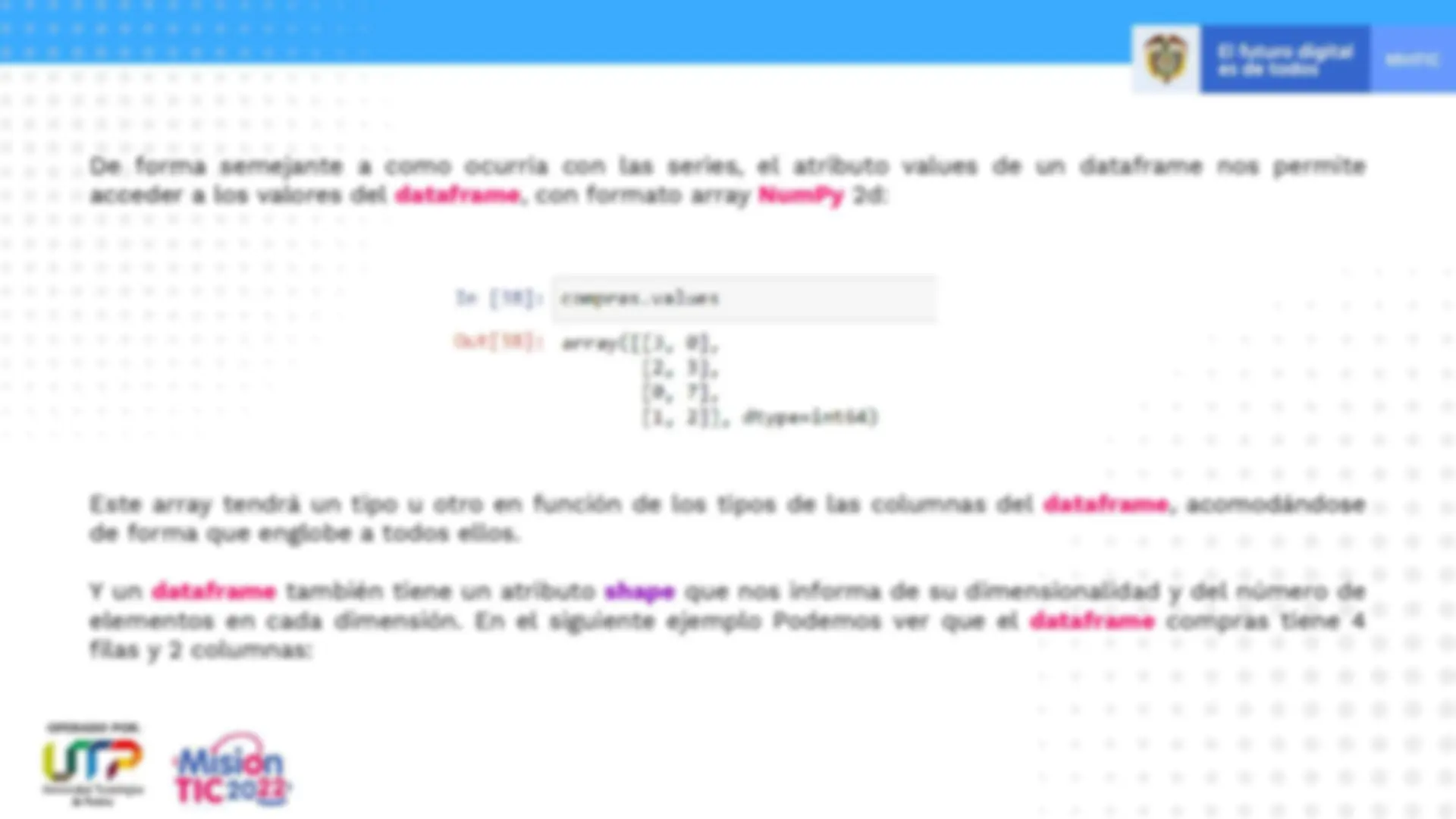
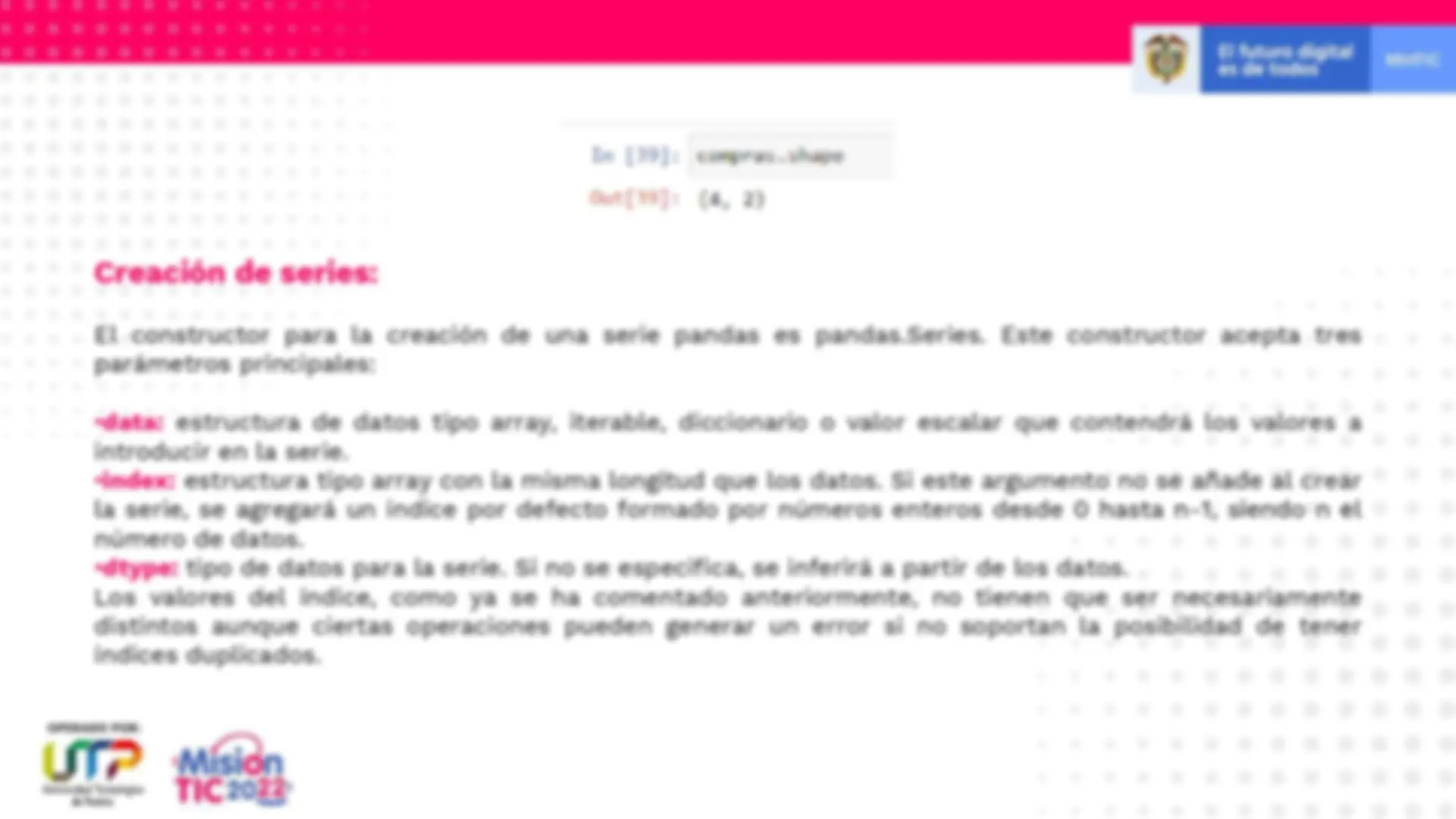
De forma semejante a como ocurría con las series, el atributo values de un dataframe nos permite acceder a los valores del dataframe , con formato array NumPy 2 d: Este array tendrá un tipo u otro en función de los tipos de las columnas del dataframe , acomodándose de forma que englobe a todos ellos. Y un dataframe también tiene un atributo shape que nos informa de su dimensionalidad y del número de elementos en cada dimensión. En el siguiente ejemplo Podemos ver que el dataframe compras tiene 4 filas y 2 columnas: