¡Descarga Análisis de Bases de Datos: Codificación, Introducción de Datos y Depuración - Prof. Pitar y más Apuntes en PDF de Estadística solo en Docsity!
TEMA 2. Organización de datos.
1. Introducción.
2. Bases de datos.
2.1. Codificación, introducción de datos, depuración, etc
2.2. Valores atípicos.
2.3. Valores faltantes.
3. Distribución de frecuencias.
4. Gráficas.
4.1. Variables cualitativas.
4.2. Variables cuantitativas.
Bases de datos
1) Codificar los datos (crear libro de códigos)
2) Introducir los datos en el SPSS:
- Vista de variables
- Vista de datos (escribir aquí los datos utilizando
tantas filas como sujetos, tantas columnas como
variables)
3) Limpieza de datos:
- Detección de valores erróneos y atípicos,
- Datos faltantes
Procedimientos de detección de valores atípicos :
1. Ver los valores máximos y mínimos (y analizar si se salen del rango
media más/menos 2 desviaciones típicas).
SPSS: Analizar > Estadísticos descriptivos > Descriptivos > opciones
2. Distribución de frecuencias.
SPSS: Analizar > Estadísticos descriptivos > Frecuencias
3. Gráficos de caja.
SPSS: Analizar > Estadísticos descriptivos > Explorar > Gráficos
4. Comparar los estadísticos robustos (M estimadores; p.e. Huber) con
los no robustos (medias).
SPSS: Analizar > Estadísticos descriptivos > Explorar > Estadísticos
Valores faltantes (missing)
Los valores faltantes se pueden introducir en el SPSS sin poner nada en la celdilla (queda visible un punto) o bien reservando un número especial para referirse a ellos (p.e. el 999 y definirlo en “perdidos” y "valores” en la vista de variables) Pueden haber varias causas (registro defectuoso, falta de respuesta total o parcial,…). Si una variable tiene muchos valores faltantes (p.e. >25%) quizás es mejor eliminarla. Soluciones: a) Supresión de datos (las más usual): Sólo analizar los sujetos que tengan los datos completos en las variables necesarias para un análisis. Si falta un valor en una variable que no está siendo utilizada en un cálculo, el sujeto sí que es tenido en cuenta en el análisis. P.e: Sí que utilizaríamos los datos de un sujeto del que no sabemos la edad si lo que queremos analizar es la relación entre “sueldo” y “satisfacción laboral”. b) Imputación de datos: Proceso de estimación de los valores ausentes basado en valores válidos de otras variables o casos de la muestra. Por ejemplo: i. Sustitución por la media. ii. Sustitución por la mediana. P.e: En un test hay 5 ítems que miden autoestima. Para obtener la puntuación total tenemos que sumar los puntos de las respuestas que un sujeto ha dado a los 5 ítems. Si no ha contestado uno de ellos debemos imputar el valor ausente para que la puntuación no se quede en la suma de 4 ítems puesto que no se podría comparar con las puntuaciones totales correspondientes a la suma de 5 ítems.
IMPUTAR no quiere decir INVENTAR datos
Frecuencia relativa o proporción (p
i
): Fracción de elementos de una muestra que
tienen un determinado valor de una variable.
Se calcula dividiendo el número de veces que se repite un valor de una variable por
el número total de elementos n de la muestra. La suma de todas las frecuencias
relativas ha de ser igual a 1.
Frecuencia relativa acumulada o proporción acumulada (pa
i
): Suma de las
frecuencias relativas o proporciones de una variable hasta la última categoría. Nos
indica la proporción de elementos muestrales con valores inferiores o iguales a una
categoría determinada.
Porcentaje (Pi) y Porcentaje acumulado (Pai): Lo mismo que la proporción y la
proporción acumulada pero multiplicado por 100.
o Frecuencia absoluta (n
i
) : Número de elementos de una muestra que tienen un
determinado valor de una variable. La suma de todas las frecuencias absolutas ha de
ser igual al n de la muestra.
o Frecuencia absoluta acumulada (na
i
): Suma de las frecuencias absolutas de una
variable hasta la última categoría. Nos indica la cantidad de elementos muestrales
con valores inferiores o iguales a una categoría determinada.
n
i
p
i
P
i
1 Mujer 76 0.55 55
2 Hombre 61 0.45 45
Distribución de frecuencias para variables cualitativas:
No tiene sentido acumular observaciones porque al no presentar la
relación de orden, la disposición de las categorías es arbitraria.
Ejemplo: Género
¿Como se interpreta? El 55 % de la muestra es mujer
SPSS
Ejemplo:
Estudios de
la madre
n
i
na
i
p
i
pa
i
P
i
Pa
i 6 Licenciatura o similar 25 137 0.182 1.000 18.2 100. 5 Diplomatura o similar 11 112 0.080 0.818 8.0 81. 4 Bachillerato superior 22 101 0.161 0.738 16.1 73. 3 Bachillerato elemental 23 79 0.168 0.577 16.8 57. 2 Estudios primarios 47 56 0.343 0.409 34.3 40. 1 Sin estudios 9 9 0.066 0.066 6.6 6.
SPSS
Distribución de frecuencias para variables cuantitativas:
Se pueden acumular datos.
Ejemplo: Edad (en años) de una muestra de adolescentes
n
i
na
i
p
i
pa
i
P
i
Pa
i 17 6 54 0.111 0.999 11.1 99. 16 8 48 0.148 0.888 14.8 88. 15 16 40 0.296 0.740 29.6 74. 14 12 24 0.222 0.444 22.2 44. 13 10 12 0.185 0.222 18.5 22. 12 2 2 0.037 0.037 3.7 3. 54 0.999 99.
Como se interpreta P 13? El 18.5% de los adolescentes tienen 13 años.
Como se interpreta na 16? 48 adolescentes tienen 16 o menos de 16 años.^11
Tablas con intervalos
agrupados
Cuando una variable
presenta muchas
categorías, se pueden
agrupar en modalidades
llamadas intervalos no
unitarios o de amplitud
superior a la unidad.
Ejemplo: Edad
Edad n
i
P
i
Pa
i
42 o + 1 0.7 100.
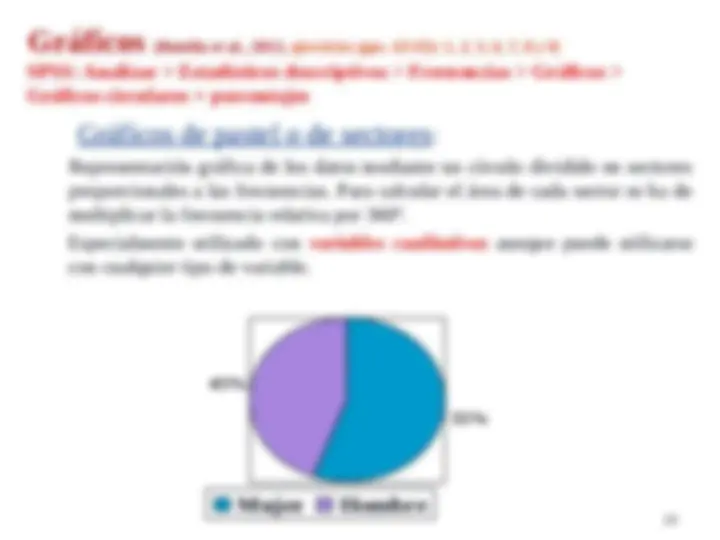
Gráficos (Botella et al. , 2012, ejercicios (pps. 63-65): 1, 2, 5, 6, 7, 8 y 9)
SPSS: Analizar > Estadísticos descriptivos > Frecuencias > Gráficos >
Gráficos circulares + porcentajes
Gráficos de pastel o de sectores:
Representación gráfica de los datos mediante un círculo dividido en sectores
proporcionales a las frecuencias. Para calcular el área de cada sector se ha de
multiplicar la frecuencia relativa por 360º.
Especialmente utilizado con variables cualitativas aunque puede utilizarse
con cualquier tipo de variable.
Mujer Hombre
Histogramas:
Representación gráfica para variables cuantitativas continuas.
Esta representación se puede hacer también con los datos acumulados.
A diferencia del diagrama de barras, los rectángulos están juntos para
indicar continuidad.
SPSS: Analizar > Estadísticos descriptivos > Frecuencias > Gráficos >
Histogramas + porcentajes
Polígono de frecuencias
Se utiliza con variables cuantitativas, tanto discretas como continuas.
Especialmente útil para ver la forma de la distribución.
Se dibuja uniendo por medio de una línea el punto central de cada rectángulo del
diagrama de barras o histograma, eliminando posteriormente los rectángulos.
Polígono de Frecuencias
¿Cómo se construye o dibuja?
1) Separamos cada OBSERVACIÓN (dato) en TALLO
(primera parte del dato) y la HOJA (segunda parte del dato).
Por ejemplo el 5.3 5 (tallo) y 3 (hoja)
2) Se listan verticalmente en orden creciente todos los tallos y
se coloca una raya vertical a su derecha.
3) Se colocan las hojas horizontalmente, con lo que tenemos
como un diagrama de barras, pero que conserva todas las
puntuaciones originales, y sabemos, por ejemplo, que el
dato 6.7 se repite en 4 ocasiones.
Una posible manera de representar los datos:
Otra posible manera de representar los mismos datos: