



1
pROCESOS EN WINDOWS Y
lINUX
Ciclo de Grado Superior en Desarrollo de Aplicaciones
Multiplataforma. Módulo 6. Sistemas Informáticos. Unidad
Didáctica 4. Tarea 8.
Juan Alberto Peñalver Álvarez
TAREAS




















Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity

Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium

Prepara tus exámenes
Prepara tus exámenes y mejora tus resultados gracias a la gran cantidad de recursos disponibles en Docsity
Prepara tus exámenes con los documentos que comparten otros estudiantes como tú en Docsity
Encuentra los documentos específicos para los exámenes de tu universidad
Estudia con lecciones y exámenes resueltos basados en los programas académicos de las mejores universidades
Responde a preguntas de exámenes reales y pon a prueba tu preparación
Consigue puntos base para descargar
Gana puntos ayudando a otros estudiantes o consíguelos activando un Plan Premium
Comunidad
Pide ayuda a la comunidad y resuelve tus dudas de estudio
Ebooks gratuitos
Descarga nuestras guías gratuitas sobre técnicas de estudio, métodos para controlar la ansiedad y consejos para la tesis preparadas por los tutores de Docsity
En este documento se presentan tres comandos básicos para interactuar con procesos en un sistema operativo linux. Se explica la definición de un proceso, el mecanismo de división implícita y cómo mejorar el tiempo de respuesta del sistema ante eventos externos. Además, se detallan los conceptos de procesos competitivos y cooperativos, el papel del núcleo o kernel y el pcb (bloque de control de proceso). Finalmente, se presentan seis comandos linux para gestionar procesos, como ps, renice, nohup, jobs y top.
Tipo: Ejercicios
1 / 29

Esta página no es visible en la vista previa
¡No te pierdas las partes importantes!
Ciclo de Grado Superior en Desarrollo de Aplicaciones Multiplataforma. Módulo 6. Sistemas Informáticos. Unidad Didáctica 4. Tarea 8. Juan Alberto Peñalver Álvarez TAREAS
A. Define qué son los procesos. Investiga e indica al menos tres comandos Linux para trabajar con procesos. PROGRAMA INFORMÁTICO DEFINICIÓN.- Un programa informático es un conjunto ordenado de instrucciones, escritas en un lenguaje de programación, para realizar una tarea en particular dentro de una computadora. En palabras sencillas, es una secuencia de órdenes que le indican a una computadora qué hacer. Cómo ejemplo se podría poner que es similar a una receta de cocina ejecutada por una máquina o robot en lugar de un ama de casa o por Carlos Argüiñano o cualquier otro MasterChef. ¿Qué es una receta de cocina? Tiene ingredientes culinarios (datos) y útiles de cocina (herramientas, hardware) que usa y, además, existe un orden exacto de cómo se debe cocinar el plato elegido para degustar. Un programa es un guion de órdenes técnicas que el humano escribe en inglés simple y la máquina lo traduce a ceros y unos para funcionar. El programa para funcionar necesita de alguien para que le diga que se ponga en marcha. Es decir, el programa necesita que un usuario humano para poder ponerse en funcionamiento. PROCESO INFORMÁTICO DEFINICIÓN.- Un proceso informático simplemente es un programa en ejecución. Los procesos, además de la información propia del programa, contienen la información necesaria para que el programa interaccione con el sistema. Un proceso informático, también es un programa informático, pero no necesita del usuario humano para empezar a funcionar. Se pone en marcha cuando se enciende el ordenador. El programa necesita, además, que se invoque a su ejecución. Por lo tanto, un Sistema Operativo es un conjunto de procesos.
Este tema se desarrolla en el contexto de sistemas multiprogramados. La multiprogramación es la multiplexación (compartición) temporal de los recursos hardware del sistema (procesador, memoria y dispositivos de E/S) entre una serie de programas activos (en ejecución), así como también mecanismo de protección y control del acceso concurrente de unos frente a otros. Beneficios potenciales de la multiprogramación y de la ejecución concurrente de programas:
Desde el punto de vista del programador Un PROCESO es un fragmento o instancia de un programa en ejecución. Está compuesto de tres elementos: (proceso estático)
Un programa se fragmenta, se divide, en varios procesos. Para conseguir la división de programas en procesos vamos a tener dos mecanismos: 1) División implícita (definida y realizada por el SO): o Para cada programa que se va a ejecutar se crea un proceso. o La relación de los procesos creados es de competencia por los recursos hardware del sistema. o Las asignaciones iniciales de atributos las crea el SO. El SO se encarga de eliminar los atributos asociados a la ejecución del proceso. o Se explota la concurrencia entre distintos programas o aplicaciones.
Ofrecer espacios comunes de direcciones para la compartición de información (variables globales).
El núcleo o Kernel se encarga de seguir la pista a los procesos del sistema. Esto es debido a que los procesos pueden tener diferentes estados. Para ver en que estados puede estar un proceso, consideramos el siguiente DIAGRAMA DE TRANSICIÓN :
Clasificamos los procesos en los siguientes estados: 1) Estado Inactivo: un proceso está en estado inactivo si no está gestionado aun por el SO. El proceso inactivo pasa a estado preparado (este paso se llama creación). 2) Estado Preparado: un proceso está preparado si posee todos los recursos que necesita para su ejecución excepto la CPU. Es el planificador el que se encarga de decidir que proceso se ejecuta (a esta transición se la denomina despacho). 3) Estado de Ejecución: un proceso está en ejecución si posee todos los recursos que necesita, incluida la CPU. El proceso pasa de ejecución a inactivo, es decir, finaliza, mediante una llamada al SO. 4) Estado Suspendido: un proceso está suspendido si además de la CPU le falta otro recurso (hardware o software) para continuar su ejecución. Un proceso permanece
suspendido hasta que la causa de suspensión desaparezca; en ese momento pasa a preparado. La transición de expropiación se produce cuando un proceso en ejecución pasa a preparado sin que él lo quiera, expropiándole la CPU. NOTA 1: Los 4 estados anteriores son los más importantes del sistema. Los procesos, para estos 4 estados, se llaman ACTIVOS, pues residen en memoria principal. En contraposición, en memoria secundaria, tenemos procesos RETIRADOS: Nota: windows = c:\pagefile.sys y Linux con una partición SWAP. 5) Estado Retirado Preparado: un proceso está retirado preparado si está preparado y no reside en memoria principal (estará en disco duro, memoria virtual). 6) Estado Retirado Suspendido : un proceso está retirado suspendido si está suspendido y no está en memoria principal (estará en disco duro, memoria virtual). NOTA 2: Un proceso nunca pasa de retirado preparado a ejecución, porque primero necesita estar en memoria para ejecutarlo (debe pasar por preparado).
El SO guarda información relativa a los procesos y su gestión en el PCB ( BLOQUE DE CONTROL DE PROCESO ), que es una estructura de datos (un registro) donde el SO almacena toda la información necesaria para gestionar los procesos. Hay un PCB para cada proceso, y cada proceso tiene un solo PCB. Los procesos inactivos no tienen PCB (es en la transición de “Creación” donde se crea un PCB). Las informaciones que suele incluir un PCB son:
La PLANIFICACIÓN es el conjunto de políticas y mecanismos incorporados en el SO que gobiernan el orden en que se completan los trabajos (procesos) en el sistema (multiprogramado). Son distintas filosofías que nos sirven para elegir el siguiente proceso a ejecutar. Desde el punto de vista del SO, un proceso puede definirse como la unidad mínima susceptible de ser planificada por un SO multiprogramado. El objetivo de la planificación es optimizar el rendimiento del SO (en especial de la CPU) de acuerdo a los criterios más importantes considerados por el diseñador. Al planificador se le pide: o Imparcialidad. o Predecibilidad. o Repetibilidad (ante carga de trabajo similar, comportamiento similar, aunque siempre va a haber algo de aleatoriedad).
3.2.1 Planificador a Largo Plazo (PLP).
Es el planificador que trabaja con la lista de lotes, encargándose de decidir cual es el siguiente trabajo o lote de la lista de lotes que pasa a la lista de preparados. El objetivo es realizar una mezcla equilibrada de procesos limitados por CPU y procesos limitados por E/S. Los trabajos candidatos son los que tienen poca interacción con el usuario y las simulaciones. Se invoca cada vez que termina un trabajo. La frecuencia de invocación es baja. En los sistemas reales, este planificador no está incorporado en el núcleo del SO sino aparte (es el caso de los sistemas NQS y NQE en estaciones comerciales de UNIX). 3.2.2 Planificador a Medio Plazo (PMP). Es el planificador que trabaja con las listas de procesos retirados (en almacenamiento secundario) y decide cuales de estos procesos pasan a preparado (en memoria principal). El objetivo es maximizar el uso eficiente de la memoria principal. Se invoca cada vez que se libera memoria. Se invocan un poco más a menudo que el PLP. Son puramente teóricos y no lo tienen todos los sistemas. 3.2.3 Planificador a Corto Plazo (PMP) Es el más importante y lo tienen todos los sistemas. Es el planificador que trabaja con la lista de procesos preparados y es el que elige el siguiente proceso que va a utilizar la CPU (hace el paso de preparado a ejecución). El objetivo es optimizar el rendimiento de la CPU o sistema según el criterio de rendimiento elegido. Se invoca cada vez que hay un evento que puede cambiar el estado global del sistema. Este tipo de planificadores son de corto plazo porque se invocan muy a menudo.
Estudiamos distintos mecanismos de planificación que pueden ser utilizados por un planificador a corto plazo (PCP o también llamado distribuidor ). Una clasificación de estos algoritmos es: A) Algoritmos Expropiativos: Son todos aquellos algoritmos que permiten que el proceso que está en ejecución pueda ser reemplazado (conmutado) sin su consentimiento por otro proceso preparado (expropiándole la CPU), siempre que se detecte un evento que cambie el estado global del sistema. Características: o Producen mayor conmutación de procesos, por lo que el rendimiento del trabajo útil disminuye. o Requieren que existan bastantes procesos en memoria principal (que estén activos). o Son poco predecibles (pues dependen de eventos). Ventaja: los tiempos de respuesta son bastante mejores. Los sistemas de tiempo real y compartido poseen este tipo de algoritmos expropiativos. Desventaja: va a haber bastante recargo, pues si se deja de ejecutar cada vez que se produce un evento, el algoritmo va a tener que estar ejecutándose bastantes veces. B) Algoritmos No Expropiativos: Son aquellos algoritmos para los que, todo proceso en ejecución permanece en ejecución hasta que el proceso decida voluntariamente pasar a suspendido, es decir, es el propio proceso el que decide que no se siga ejecutando. Características: Los algoritmos no expropiativos son predecibles y su rendimiento depende de la carga de trabajo y no de eventos. Ventaja: no recargan el sistema, pues es el propio proceso el que deja la CPU. Desventaja: estos algoritmos no dan buenos tiempos de respuesta, debido a que retrasan el tiempo de respuesta a cualquier cosa. Los SO por lotes y las políticas de expropiación a largo plazo suelen tener algoritmos no expropiativos.
En este tipo de algoritmos, la carga de trabajo (los procesos), se realiza en el orden en el que van llegando a la cola de procesos preparados, sin que se adelante uno a otro. El primer proceso en llegar a la cola es el primero en ser atendido: las ráfagas de CPU se realizan en el orden en que llegan los procesos a la cola de preparados.
Son algoritmos no expropiativos y se usan para sistemas por lotes. Ventajas: son algoritmos muy sencillos y con un recargo mínimo del sistema. Desventajas: el rendimiento es bajo, el tiempo de respuesta pobre y la productividad del sistema no es predecible. Para los procesos pequeños, los tiempos de respuesta y de envío a retorno se van a deteriorar bastante. Ante cargas similares de trabajo, el comportamiento no es similar, sino que hay variaciones significativas (el planificador no es equitativo ni repetitivo).
En este tipo de algoritmos, la carga de trabajo se realiza ejecutando primero el que le queda menos tiempo para terminar. Se distinguen dos categorías: o Si el algoritmo es expropiativo , es entonces cuando se habla propiamente de SRTN. Siempre que entra un nuevo proceso, se chequea si le queda menos tiempo que el que se está ejecutando. Si es así, se expropia el que está en ejecución. o Si el algoritmo no es expropiativo , se habla de SJF ( SHORTEST JOB FIRST ), para el cual se ejecuta primero el trabajo al que le quede menos tiempo. Las características de estas 2 familias de algoritmos son: o Tiempos de espera mínimos. o Buenos tiempos de respuesta. o La productividad es predecible. o El rendimiento depende del grado de fiabilidad. Problemas de este tipo de algoritmos: o En sistemas de tiempo compartido, nadie predice el comportamiento, por lo que no sirven. o Con la versión expropiativa, se favorece a los procesos pequeños, pero perjudica claramente a los procesos con tiempos largos. El rendimiento de este planificador depende de la fiabilidad de la estimación del tiempo de lo que queda por ejecutar: o Si el sistema es por lotes , el usuario puede proporcionar una estimación del tiempo que dura. o En sistemas de producción , se puede hacer una estimación de cuanto es el tiempo que se va a tardar, pues siempre se están ejecutando cargas de trabajo similares.
Planificación de margen mínimo: se ejecuta primero aquel proceso para el cual la diferencia entre el tiempo tope de plazo y el tiempo en que se tarda en atender ese servicio es menor ( plazo - TSERVICIO ).
En este tipo de planificación más compleja, tenemos varios planificadores en el mismo sistema, con el fin de dar la mejor respuesta a cada cola de procesos preparados. Vamos a dividir y a clasificar los procesos en distintas categorías. Para cada una de ellas vamos a tener una cola de procesos preparados. Cada cola tiene un algoritmo de planificación distinto. Es necesario un mecanismo de planificación entre colas. Este algoritmo suele ser de prioridad absoluta. También se suelen usar quantos para el reparto proporcional del tiempo. Las ventajas potenciales de MLQ se emplean en los sistemas primario / subordinado (foreground / background).
La evolución de la planificación MLQ consiste en usar colas multinivel con realimentación , es decir, la planificación MLFQ. En este tipo de planificación, en lugar de tener categorías fijas de procesos asignados a colas específicas, se sigue la idea de hacer que un proceso pueda pasar de una cola a otra dependiendo de su comportamiento en tiempo de ejecución.
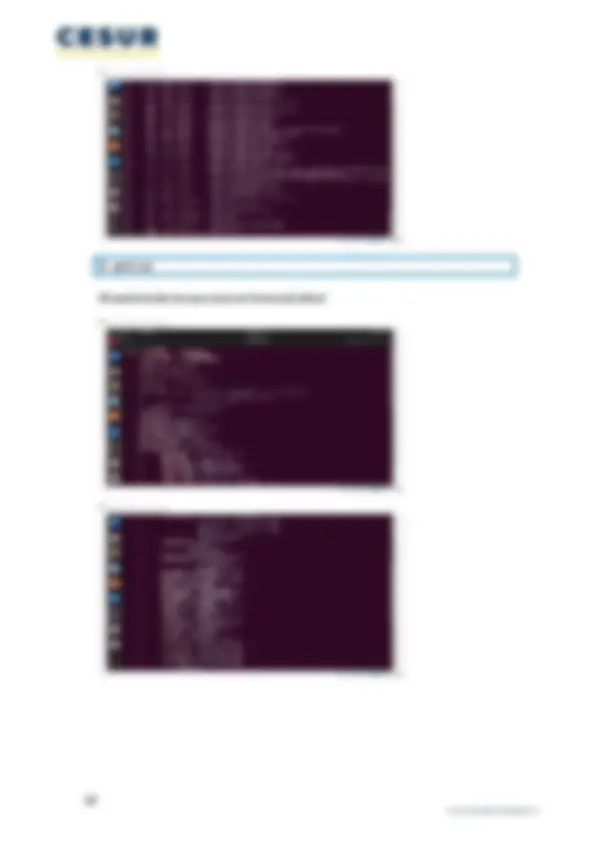
Cada cola tiene asignado un quanto de tiempo y posee un mecanismo de planificación propio. Listado de comandos Linux para procesos: ps Permite informar sobre el estado de los procesos. pstree Muestra los procesos en forma de árbol. kill Permite enviar señales ( signals ) a los procesos, indicando su PID , y la señal por defecto sería la que los mata. killall Igual que el comando kill pero indicando el nombre del programa en lugar de su PID , siendo afectados todos los procesos que tengan dicho nombre. nice Permite cambiar la prioridad de un proceso. renice Permite alterar la prioridad de un proceso en tiempo real. nohup y & Estos dos comandos que permiten ejecutar procesos en segundo plano ( background ), aunque realizan una función similar, no son lo mismo jobs Lista los procesos actuales en ejecución después de haber ejecutado los anteriores comandos ( nohup o & ) y poder controlar estos cuando se alargan en el tiempo y sólo se dispone de un terminal. top Utilizada para el monitoreo en tiempo real de los procesos y de otras variables del sistema. B. Pon un ejemplo de uso de cada uno de los comandos que conozcas. ¿Con cuál puedes ver los procesos que se están ejecutando en un sistema operativo Windows? ¿Y en Linux? $ ps -A Este comando muestra todos los procesos (los de todos los usuarios):
$ pstree Muestra todos los procesos en forma de árbol:
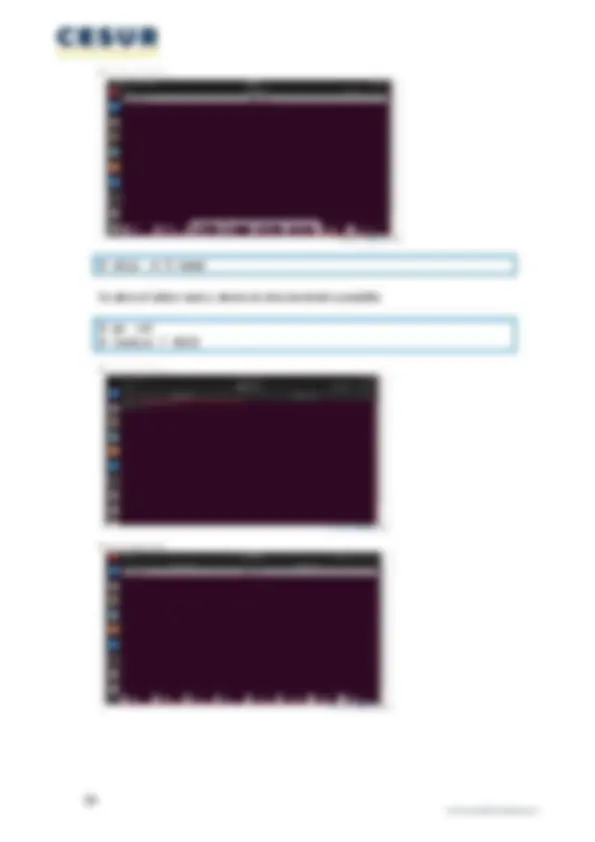
$ pstree -AGu Usado con la opción -A y -G muestra un árbol con líneas estilo ASCII y de terminal VT100 respectivamente, y se añade también -u para mostrar entre paréntesis al usuario propietario del proceso: