¡Descarga Programación en Panda y más Guías, Proyectos, Investigaciones en PDF de Tecnología solo en Docsity!
pandas
#pandas
Tabla de contenido
- Acerca de
- Capítulo 1: Empezando con los pandas
- Observaciones
- Versiones
- Examples
- Instalación o configuración
- Instalar via anaconda
- Hola Mundo
- Estadísticas descriptivas
- Capítulo 2: Agrupar datos de series de tiempo
- Examples
- Generar series de tiempo de números aleatorios y luego abajo muestra
- Capítulo 3: Análisis: Reunirlo todo y tomar decisiones.
- Examples
- Análisis quintil: con datos aleatorios
- Que es un factor
- Inicialización
- pd.qcut - Crea cubos quintiles
- Análisis
- Devoluciones de parcela
- Visualizar la correlación del scatter_matrix con scatter_matrix
- Calcula y visualiza Máximo Draw Down
- Calcular estadísticas
- Capítulo 4: Anexando a DataFrame
- Examples
- Anexando una nueva fila a DataFrame
- Añadir un DataFrame a otro DataFrame
- Capítulo 5: Calendarios de vacaciones
- Examples
- Crear un calendario personalizado
- Usa un calendario personalizado
- Consigue las vacaciones entre dos fechas.
- Cuente el número de días laborables entre dos fechas.
- Capítulo 6: Creando marcos de datos
- Introducción
- Examples
- Crear un DataFrame de muestra
- Crea un DataFrame de muestra usando Numpy
- Cree un DataFrame de muestra a partir de múltiples colecciones usando el Diccionario
- Crear un DataFrame a partir de una lista de tuplas
- Crear un DataFrame de un diccionario de listas
- Crear un DataFrame de muestra con datetime
- Crear un DataFrame de muestra con MultiIndex
- Guardar y cargar un DataFrame en formato pickle (.plk)
- Crear un DataFrame a partir de una lista de diccionarios
- Capítulo 7: Datos categóricos
- Introducción
- Examples
- Creación de objetos
- Creando grandes conjuntos de datos al azar
- Capítulo 8: Datos de agrupación
- Examples
- Agrupacion basica
- Agrupar por una columna
- Agrupar por columnas múltiples
- Números de agrupación
- Columna de selección de un grupo.
- Agregando por tamaño versus por cuenta
- Agregando grupos
- Exportar grupos en diferentes archivos.
- usar la transformación para obtener estadísticas a nivel de grupo mientras se preserva el
- Capítulo 9: Datos duplicados
- Examples
- Seleccione duplicado
- Drop duplicado
- Contando y consiguiendo elementos únicos.
- Obtener valores únicos de una columna.
- Capítulo 10: Datos perdidos
- Observaciones
- Examples
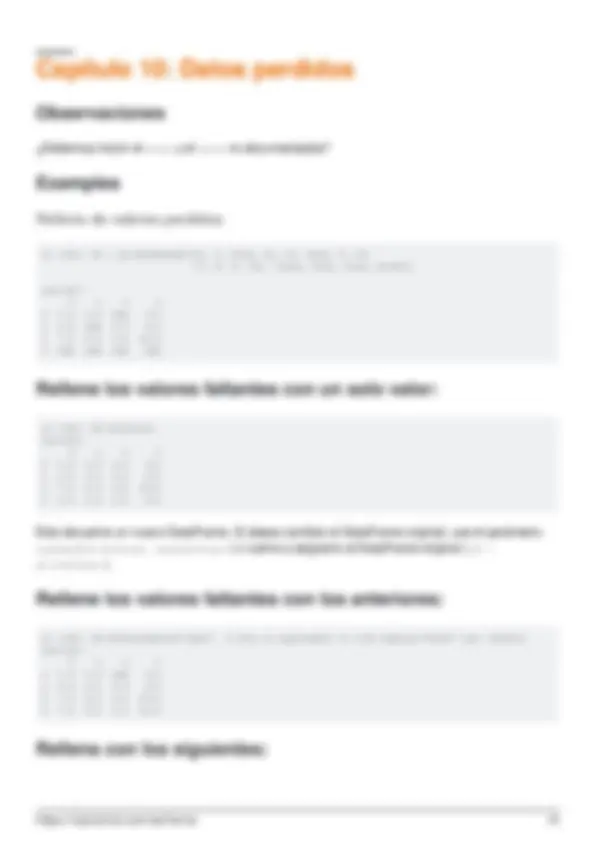
- Relleno de valores perdidos
- Rellene los valores faltantes con un solo valor:
- Rellene los valores faltantes con los anteriores:
- Rellena con los siguientes:
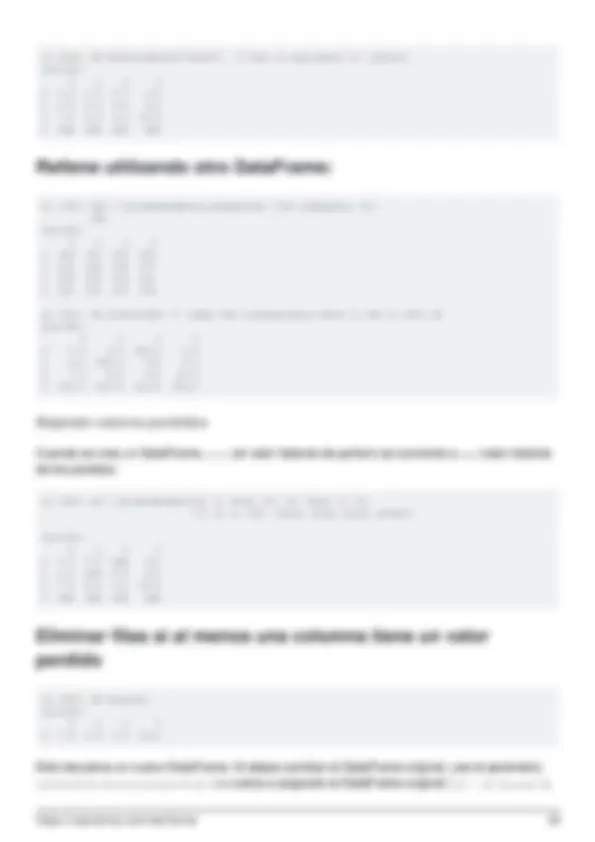
- Rellene utilizando otro DataFrame:
- Eliminar filas si al menos una columna tiene un valor perdido
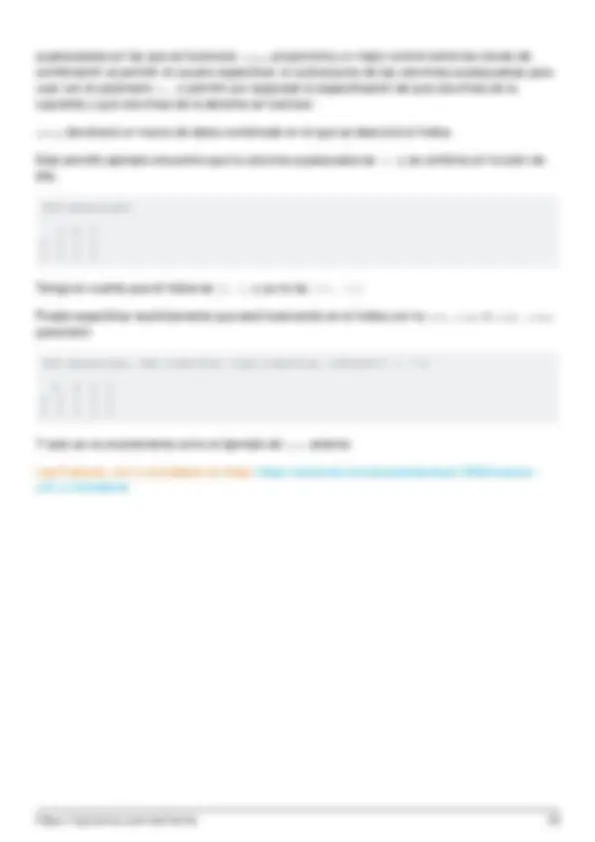
- Eliminar filas si faltan todos los valores de esa fila
- Eliminar columnas que no tengan al menos 3 valores no perdidos
- Interpolación
- Comprobación de valores perdidos
- Capítulo 11: Desplazamiento y desplazamiento de datos
- Examples
- Desplazar o retrasar valores en un marco de datos
- Capítulo 12: Fusionar, unir y concatenar
- Sintaxis
- Parámetros
- Examples
- Unir
- Fusionando dos DataFrames
- Unir internamente:
- Unión externa:
- Unirse a la izquierda:
- Unirse a la derecha
- Fusionar / concatenar / unir múltiples marcos de datos (horizontal y verticalmente)
- Fusionar, Unir y Concat
- ¿Cuál es la diferencia entre unirse y fusionarse?
- Capítulo 13: Gotchas de pandas
- Observaciones
- Examples
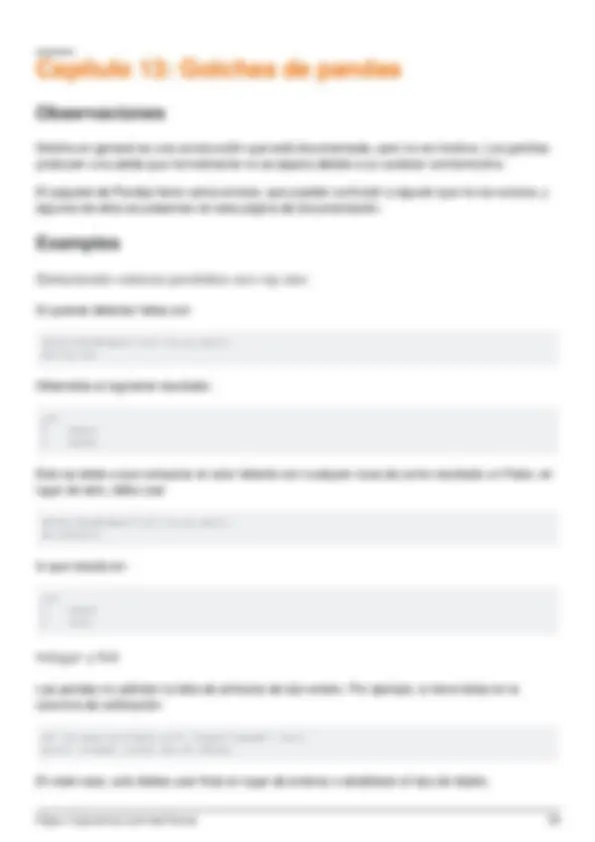
- Detectando valores perdidos con np.nan
- Integer y NA
- Alineación automática de datos (comportamiento indexado)
- Capítulo 14: Gráficos y visualizaciones
- Examples
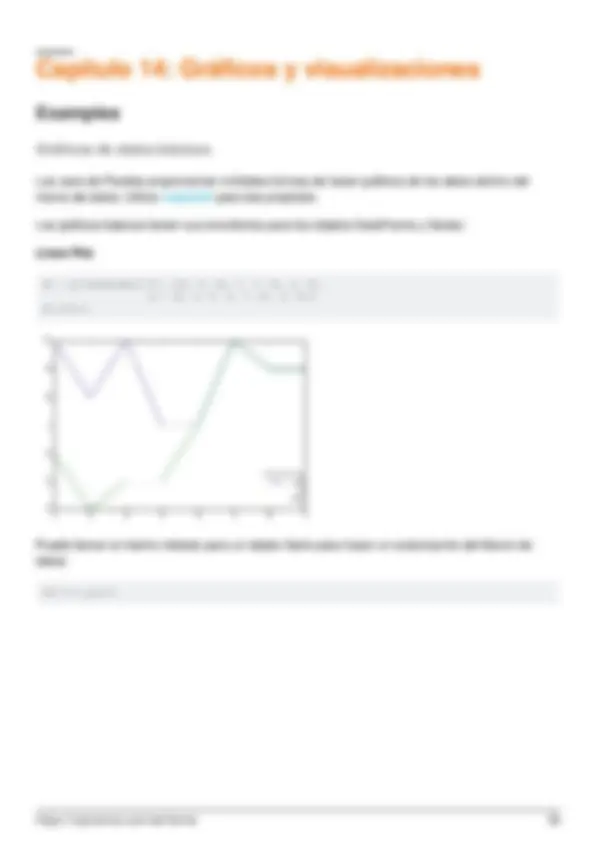
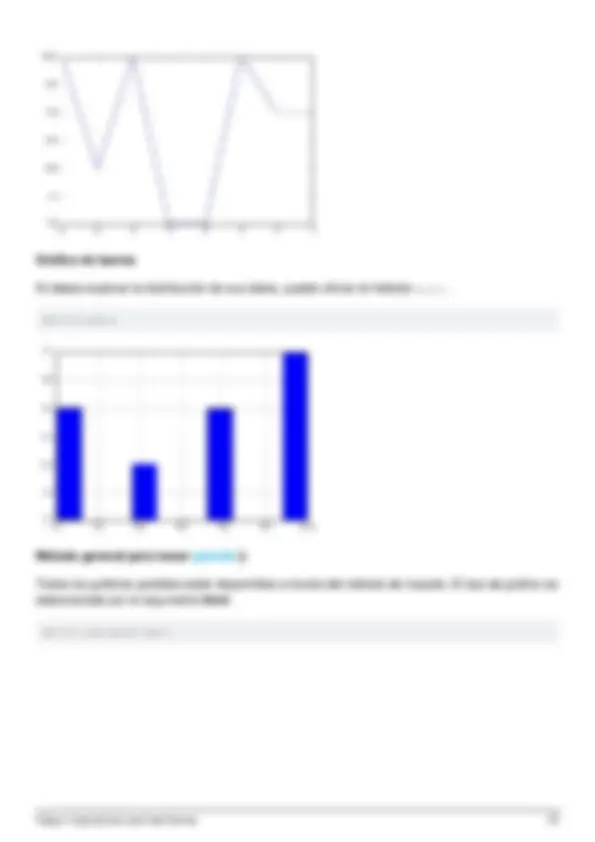
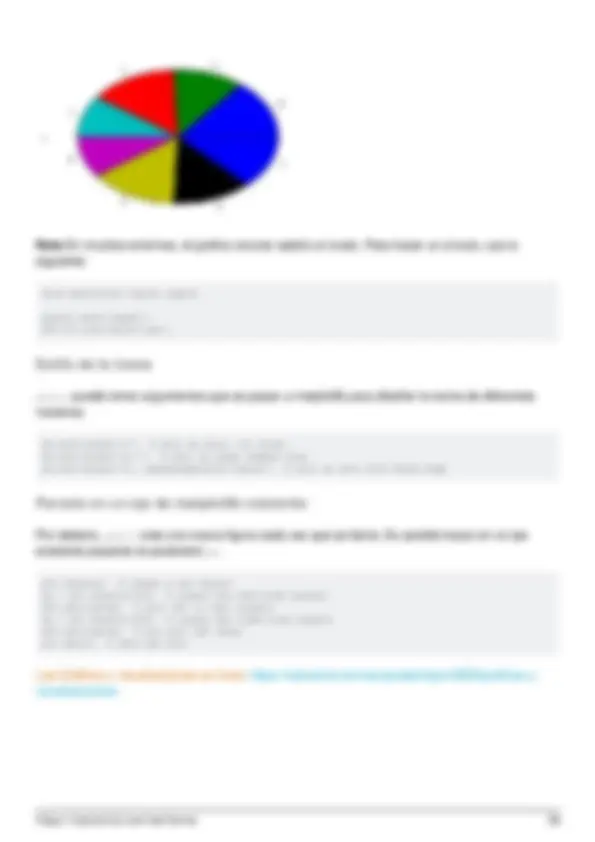
- Gráficos de datos básicos
- Estilo de la trama
- Parcela en un eje de matplotlib existente
- Capítulo 15: Guardar pandas dataframe en un archivo csv
- Parámetros
- Examples
- Crear un marco de datos aleatorio y escribir en .csv
- Guarde Pandas DataFrame de la lista a los dictados a CSV sin índice y con codificación de
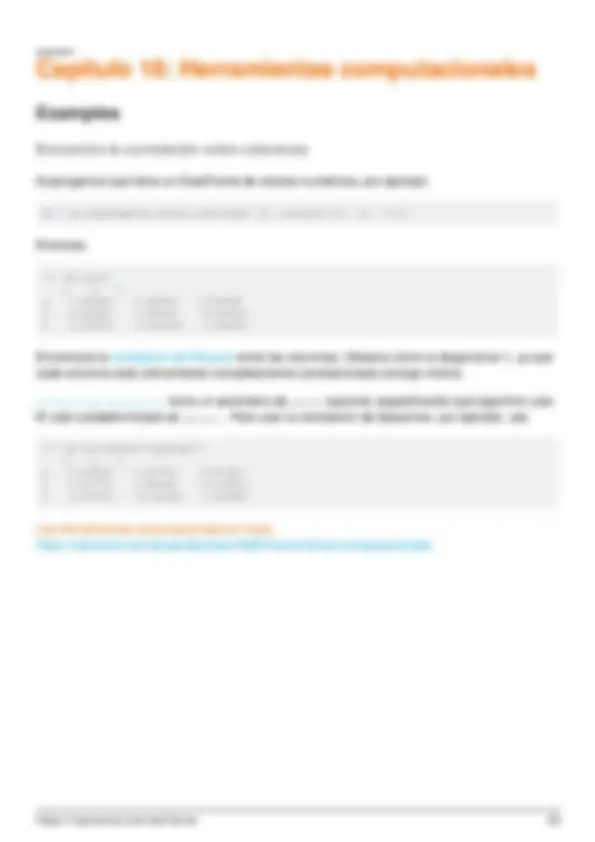
- Capítulo 16: Herramientas computacionales
- Examples
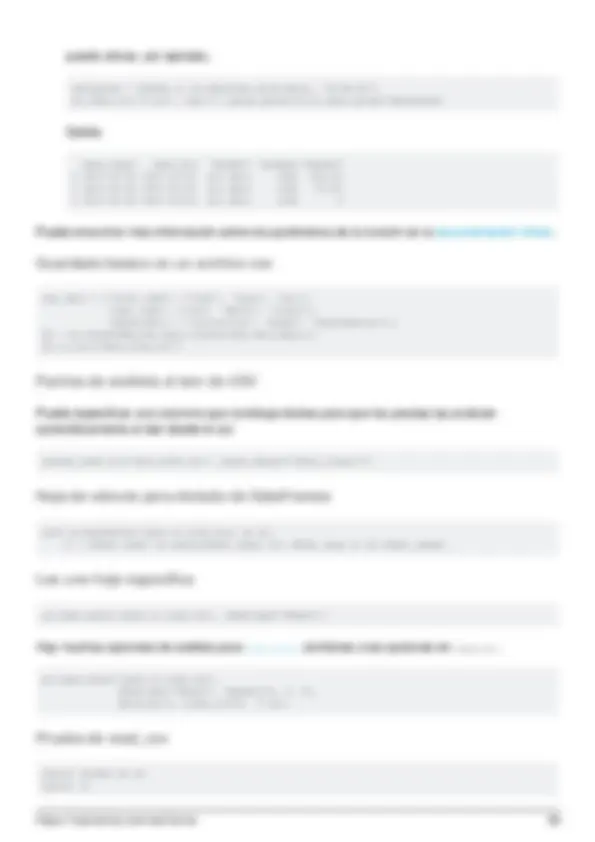
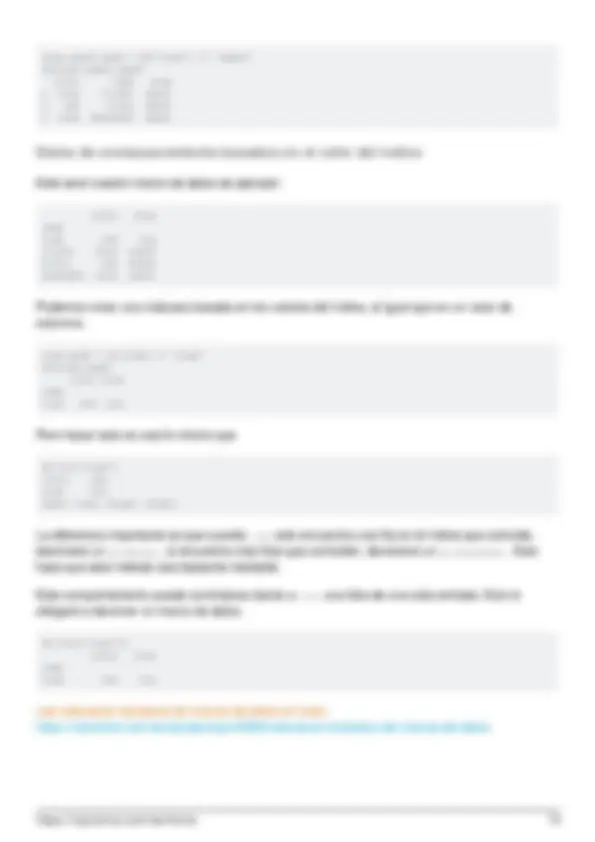
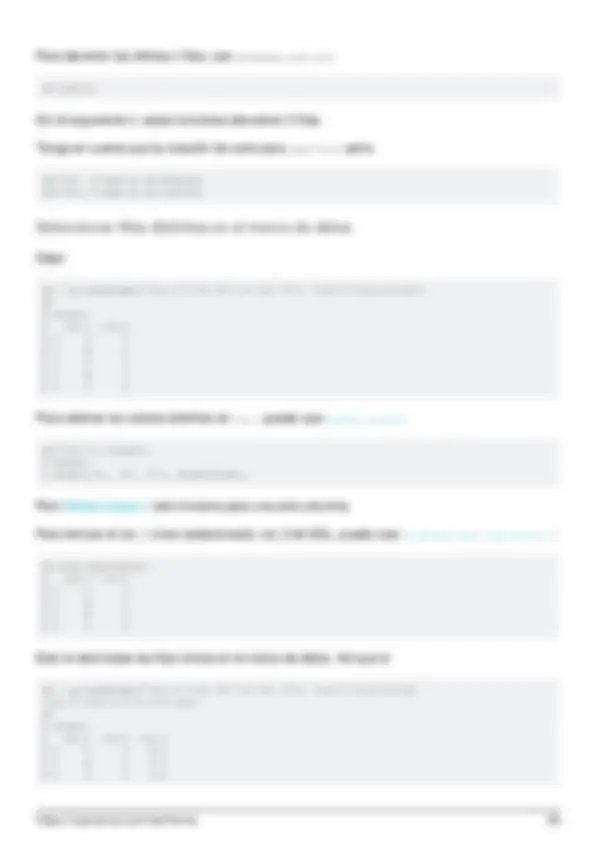
- Encuentra la correlación entre columnas
- Capítulo 17: Herramientas de Pandas IO (leer y guardar conjuntos de datos)
- Observaciones
- Examples
- Leyendo el archivo csv en DataFrame
- Expediente:
- Código:
- Salida:
- Algunos argumentos útiles:
- Guardado básico en un archivo csv
- Fechas de análisis al leer de CSV
- Hoja de cálculo para dictado de DataFrames
- Lee una hoja específica
- Prueba de read_csv
- Lista de comprensión
- Leer en trozos
- Guardar en archivo CSV
- Análisis de columnas de fecha con read_csv
- Lea y combine varios archivos CSV (con la misma estructura) en un DF
- Leyendo el archivo cvs en un marco de datos pandas cuando no hay una fila de encabezado
- Usando HDFStore
- Generar muestra DF con diversos tipos.
- hacer un DF más grande (10 * 100.000 = 1.000.000 filas)
- crear (o abrir un archivo HDFStore existente)
- guarde nuestro marco de datos en el archivo h5 (HDFStore), indexando [int32, int64, string
- Mostrar detalles de HDFStore
- mostrar columnas indexadas
- cerrar (vaciar al disco) nuestro archivo de tienda
- Lea el registro de acceso de Nginx (varias cotillas)
- Capítulo 18: Indexación booleana de marcos de datos
- Introducción
- Examples
- Accediendo a un DataFrame con un índice booleano
- Aplicar una máscara booleana a un marco de datos
- Datos de enmascaramiento basados en el valor de la columna
- Datos de enmascaramiento basados en el valor del índice
- Capítulo 19: Indexación y selección de datos.
- Examples
- Seleccionar columna por etiqueta
- Seleccionar por posición
- Rebanar con etiquetas
- Posición mixta y selección basada en etiqueta
- Indexación booleana
- Filtrado de columnas (selección de "interesante", eliminación innecesaria, uso de RegEx, e
- generar muestra DF
- mostrar columnas que contengan la letra 'a'
- muestre las columnas usando el filtro RegEx (b|c|d) - b o c o d :
- mostrar todas las columnas excepto los que empiezan por a (en otras palabras remove / deja
- Filtrar / seleccionar filas usando el método .query ()
- generar DF aleatorio
- seleccione las filas donde los valores en la columna A > 2 y los valores en la columna B <
- utilizando el método .query() con variables para filtrar
- Rebanado Dependiente del Camino
- Obtener las primeras / últimas n filas de un marco de datos
- Seleccionar filas distintas en el marco de datos
- Filtrar las filas con datos faltantes (NaN, Ninguno, NaT)
- Capítulo 20: IO para Google BigQuery
- Examples
- Lectura de datos de BigQuery con credenciales de cuenta de usuario
- Lectura de datos de BigQuery con credenciales de cuenta de servicio
- Capítulo 21: JSON
- puede pasar la cadena del json o una ruta de archivo a un archivo con json válido
- Marco de datos en JSON anidado como en los archivos flare.js utilizados en D3.js
- Lee JSON del archivo
- Capítulo 22: Leer MySQL a DataFrame
- Examples
- Usando sqlalchemy y PyMySQL
- Para leer mysql a dataframe, en caso de gran cantidad de datos
- Capítulo 23: Leer SQL Server a Dataframe
- Examples
- Utilizando pyodbc
- Usando pyodbc con bucle de conexión
- Capítulo 24: Leyendo archivos en pandas DataFrame
- Examples
- Leer la tabla en DataFrame
- Archivo de tabla con encabezado, pie de página, nombres de fila y columna de índice:
- Archivo de tabla sin nombres de fila o índice:
- Datos con encabezado, separados por punto y coma en lugar de comas.
- Tabla sin nombres de filas o índice y comas como separadores
- Recopila datos de la hoja de cálculo de Google en el marco de datos de pandas
- Capítulo 25: Making Pandas Play Nice con tipos de datos nativos de Python
- Examples
- Mover datos de pandas a estructuras nativas Python y Numpy
- Capítulo 26: Manipulación de cuerdas
- Examples
- Expresiones regulares
- Rebanar cuerdas
- Comprobando el contenido de una cadena
- Capitalización de cuerdas
- Capítulo 27: Manipulación sencilla de DataFrames.
- Examples
- Eliminar una columna en un DataFrame
- Renombrar una columna
- Añadiendo una nueva columna
- Asignar directamente
- Añadir una columna constante
- Columna como expresión en otras columnas.
- Crealo sobre la marcha
- agregar columnas múltiples
- añadir múltiples columnas sobre la marcha
- Localice y reemplace los datos en una columna
- Añadiendo una nueva fila a DataFrame
- Eliminar / eliminar filas de DataFrame
- Reordenar columnas
- Capítulo 28: Meta: Pautas de documentación.
- Observaciones
- Examples
- Mostrando fragmentos de código y salida
- estilo
- Compatibilidad con la versión pandas
- imprimir declaraciones
- Prefiero el apoyo de python 2 y 3:
- Capítulo 29: Multiindex
- Examples
- Seleccione de MultiIndex por Nivel
- Iterar sobre DataFrame con MultiIndex
- Configuración y clasificación de un MultiIndex
- Cómo cambiar columnas MultiIndex a columnas estándar
- Cómo cambiar columnas estándar a MultiIndex
- Columnas multiindex
- Visualización de todos los elementos en el índice.
- Capítulo 30: Obteniendo información sobre DataFrames
- Examples
- Obtener información de DataFrame y el uso de la memoria
- Lista de nombres de columna de DataFrame
- Las diversas estadísticas de resumen de Dataframe.
- Capítulo 31: Pandas Datareader
- Observaciones
- Examples
- Ejemplo básico de Datareader (Yahoo Finance)
- Lectura de datos financieros (para múltiples tickers) en el panel de pandas - demostración
- Capítulo 32: pd.DataFrame.apply
- Examples
- pandas.DataFrame.apply Uso Básico
- Capítulo 33: Remodelación y pivotamiento
- Examples
- Simple pivotante
- Pivotando con la agregación.
- Apilamiento y desapilamiento.
- Tabulación cruzada
- Las pandas se derriten para ir de lo ancho a lo largo.
- Dividir (remodelar) cadenas CSV en columnas en varias filas, con un elemento por fila
- Capítulo 34: Remuestreo
- Capítulo 35: Secciones transversales de diferentes ejes con MultiIndex.
- Examples
- Selección de secciones utilizando .xs.
- Usando .loc y slicers
- Capítulo 36: Serie
- Examples
- Ejemplos de creación de series simples
- Series con fecha y hora
- Algunos consejos rápidos sobre Series in Pandas
- Aplicando una función a una serie
- Capítulo 37: Tipos de datos
- Observaciones
- Examples
- Comprobando los tipos de columnas
- Cambiando dtypes
- Cambiando el tipo a numérico
- Cambiando el tipo a datetime
- Cambiando el tipo a timedelta
- Seleccionando columnas basadas en dtype
- Resumiendo dtypes
- Capítulo 38: Trabajando con series de tiempo
- Examples
- Creación de series de tiempo
- Indización parcial de cuerdas
- Obteniendo datos
- Subconjunto
- Capítulo 39: Tratar variables categóricas
- Examples
- Codificación instantánea con get_dummies ()
- Capítulo 40: Uso de .ix, .iloc, .loc, .at y .iat para acceder a un DataFrame
- Examples
- Utilizando .iloc
- Utilizando .loc
- Capítulo 41: Valores del mapa
- Creditos
Capítulo 1: Empezando con los pandas
Observaciones
Pandas es un paquete de Python que proporciona estructuras de datos rápidas, flexibles y
expresivas diseñadas para hacer que el trabajo con datos "relacionales" o "etiquetados" sea fácil
e intuitivo. Pretende ser el elemento fundamental de alto nivel para realizar análisis de datos
prácticos y del mundo real en Python.
La documentación oficial de Pandas se puede encontrar aquí.
Versiones
Pandas
Versión Fecha de lanzamiento
https://riptutorial.com/es/home 2
Versión Fecha de lanzamiento
Examples Instalación o configuración
Las instrucciones detalladas para configurar o instalar pandas se pueden encontrar aquí en la
documentación oficial.
Instalando pandas con anaconda
Instalar pandas y el resto de la pila NumPy y SciPy puede ser un poco difícil para los usuarios
inexpertos.
La forma más sencilla de instalar no solo pandas, sino Python y los paquetes más populares que
forman la pila SciPy (IPython, NumPy, Matplotlib, ...) es con Anaconda , una multiplataforma
(Linux, Mac OS X, Windows) Distribución en Python para análisis de datos y computación
científica.
Después de ejecutar un instalador simple, el usuario tendrá acceso a los pandas y al resto de la
pila SciPy sin necesidad de instalar nada más, y sin tener que esperar a que se compile ningún
software.
Las instrucciones de instalación de Anaconda se pueden encontrar aquí.
Una lista completa de los paquetes disponibles como parte de la distribución de Anaconda se
puede encontrar aquí.
Una ventaja adicional de la instalación con Anaconda es que no requiere derechos de
administrador para instalarlo, se instalará en el directorio de inicio del usuario, y esto también
hace que sea trivial eliminar Anaconda en una fecha posterior (solo elimine esa carpeta).
Instalando pandas con miniconda
La sección anterior describía cómo instalar pandas como parte de la distribución de Anaconda.
Sin embargo, este enfoque significa que instalará más de cien paquetes e implica descargar el
instalador, que tiene un tamaño de unos pocos cientos de megabytes.
Si desea tener más control sobre qué paquetes, o tiene un ancho de banda de Internet limitado,
entonces instalar pandas con Miniconda puede ser una mejor solución.
Conda es el gestor de paquetes sobre el que se basa la distribución de Anaconda. Es un gestor
de paquetes que es multiplataforma y es independiente del lenguaje (puede desempeñar un papel
similar al de una combinación pip y virtualenv).
Miniconda le permite crear una instalación de Python mínima e independiente, y luego usar el
comando Conda para instalar paquetes adicionales.
https://riptutorial.com/es/home 3
requerirá un compilador para compilar los bits de código requeridos, y puede tardar unos minutos
en completarse.
Instalar via anaconda
Primera descarga de anaconda desde el sitio de Continuum. Ya sea a través del instalador gráfico
(Windows / OSX) o ejecutando un script de shell (OSX / Linux). Esto incluye pandas!
Si no desea que los 150 paquetes estén convenientemente agrupados en anaconda, puede
instalar miniconda. Ya sea a través del instalador gráfico (Windows) o shell script (OSX / Linux).
Instala pandas en miniconda usando:
conda install pandas
Para actualizar pandas a la última versión en anaconda o miniconda use:
conda update pandas Hola Mundo
Una vez que se haya instalado Pandas, puede verificar si está funcionando correctamente
creando un conjunto de datos de valores distribuidos aleatoriamente y trazando su histograma.
import pandas as pd # This is always assumed but is included here as an introduction. import numpy as np import matplotlib.pyplot as plt np.random.seed(0) values = np.random.randn(100) # array of normally distributed random numbers s = pd.Series(values) # generate a pandas series s.plot(kind='hist', title='Normally distributed random values') # hist computes distribution plt.show()
https://riptutorial.com/es/home 5
Compruebe algunas de las estadísticas de los datos (media, desviación estándar, etc.)
s.describe()
Output: count 100.
mean 0.
std 1.
min -2.
25% -0.
50% 0.
75% 0.
max 2.
dtype: float
Estadísticas descriptivas
Las estadísticas descriptivas (media, desviación estándar, número de observaciones, mínimo,
máximo y cuartiles) de las columnas numéricas se pueden calcular utilizando el método
.describe() , que devuelve un marco de datos de pandas de estadísticas descriptivas.
In [1]: df = pd.DataFrame({'A': [1, 2, 1, 4, 3, 5, 2, 3, 4, 1], 'B': [12, 14, 11, 16, 18, 18, 22, 13, 21, 17], 'C': ['a', 'a', 'b', 'a', 'b', 'c', 'b', 'a', 'b', 'a']}) In [2]: df Out[2]: A B C 0 1 12 a
https://riptutorial.com/es/home 6
Capítulo 2: Agrupar datos de series de
tiempo
Examples Generar series de tiempo de números aleatorios y luego abajo muestra import pandas as pd import numpy as np import matplotlib.pyplot as plt
I want 7 days of 24 hours with 60 minutes each
periods = 7 * 24 * 60 tidx = pd.date_range('2016-07-01', periods=periods, freq='T')
^ ^
| |
Start Date Frequency Code for Minute
This should get me 7 Days worth of minutes in a datetimeindex
Generate random data with numpy. We'll seed the random
number generator so that others can see the same results.
Otherwise, you don't have to seed it.
np.random.seed([3,1415])
This will pick a number of normally distributed random numbers
where the number is specified by periods
data = np.random.randn(periods) ts = pd.Series(data=data, index=tidx, name='HelloTimeSeries') ts.describe() count 10080. mean -0. std 0. min -3. 25% -0. 50% 0. 75% 0. max 3. Name: HelloTimeSeries, dtype: float
Tomemos estos 7 días de datos por minuto y tomamos muestras cada 15 minutos. Todos los
códigos de frecuencia se pueden encontrar aquí.
resample says to group by every 15 minutes. But now we need
to specify what to do within those 15 minute chunks.
We could take the last value.
ts.resample('15T').last()
O cualquier otra cosa que podamos hacer a un groupby objeto, documentación.
https://riptutorial.com/es/home 8
Incluso podemos agregar varias cosas útiles. Vamos a trazar el min , el mean y el max de estos
datos de resample('15M').
ts.resample('15T').agg(['min', 'mean', 'max']).plot()
Volvamos a muestrear sobre '15T' (15 minutos), '30T' (media hora) y '1H' (1 hora) para ver cómo
nuestros datos se vuelven más suaves.
fig, axes = plt.subplots(1, 3, figsize=(12, 4)) for i, freq in enumerate(['15T', '30T', '1H']): ts.resample(freq).agg(['max', 'mean', 'min']).plot(ax=axes[i], title=freq)
Lea Agrupar datos de series de tiempo en línea:
https://riptutorial.com/es/pandas/topic/4747/agrupar-datos-de-series-de-tiempo
https://riptutorial.com/es/home 9