TALLER 4- 2P
Mineria de Datos
Ing Estevan Gomez, MSc PhD(c)
Taller7- 2P
Regresión lineal en Python
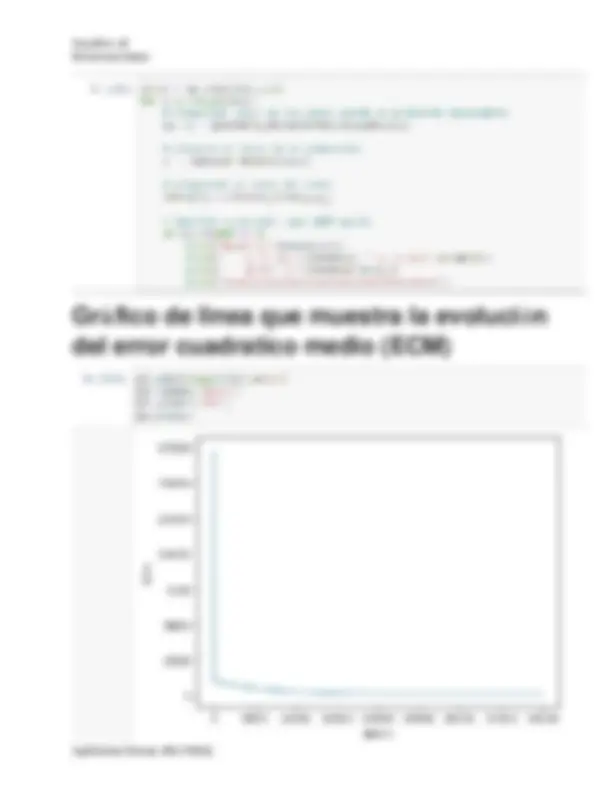
El algoritmo de Regresión Lineal Este algoritmo permite encontrar de forma
automática los parámetros de la línea recta que mejor se ajusta a un set de
datos. Si quieres entender en qúe consiste este algoritmo, te sugiero revisar
el artículo en donde explico la Regresión Lineal en detalle.
El set de datos Los datos a usar en este tutorial corresponden a la medición
de la presión sanguínea sistólica (medida en mm de Mercurio) para 29
sujetos de diferentes edades.
En este set de datos la variable independiente (x) corresponde a la edad de
cada sujeto, mientras que la variable dependiente (y) es precisamente la
presión sanguínea.
Librerías requeridas Para la implementación de este algoritmo se requieren
tres librerías:
Pandas: que permite leer el set de datos, almacenado en formato .csv
(comma separated values) Numpy: usado para almacenar los datos x y y, así
como para implementar de manera sencilla las funciones para el cálculo del
error y el gradiente descendente. Matplotlib: para graficar los resultados del
algoritmo. Estas librerías se pueden importar en Python usando las
siguientes líneas de código:
cruzada.
MATERIA
Minería de Datos
NRC
10060
TRABAJO
No.
07
CARRERA
Tecnologías de la Información
Docente
Ing. Estevan Gomez
PERIODO
ACADÉMICO
PREGRADO S-I MAYO-SEPT
23
FECHA
06/07/2023
TÍTULO
Taller 7-2P
ESTUDIANTE(S)
Bryan Azuero