Scarica Advanced Image Analysis e più Dispense in PDF di Elaborazione digitale delle immagini solo su Docsity!
ADVANCED^ IMAGE^ ANALYSIS
Index
- Imaging
- Digital Images
- Color Spaces
- Intensity transformations
- Spatial filtering
- Derivative
- Sharpening
- Binary Image
- Connected components
- Mathematical morphology
- Grayscale morphology
- Image Segmentation
- Image descriptors
- Optical flow
- Bibliography
1. Red-sensitive cones (long wavelengths).
2. Green-sensitive cones (medium wavelengths).
3. Blue-sensitive cones (short wavelengths).
The brain combines signals from these cones to produce the full spectrum of visible colors. This
trichromatic system allows humans to perceive millions of colors and adapt to a variety of lighting
conditions. Defects in the cone cells can lead to color blindness, affecting how certain colors are
distinguished.
The process of creating a digital image involves two key steps: image acquisition and image
representation. These steps rely on technology and principles to convert real-world scenes into
digital formats.
Digital cameras and scanners use a matrix sensor made of many tiny light-sensitive elements
(pixels) arranged in a grid. Each pixel measures the intensity of light falling on it, but capturing
color requires additional processing.
To separate colors, the sensor matrix applies three types of filters: red, green, and blue (RGB),
corresponding to the primary colors of light. These filters ensure that each pixel records the
intensity of just one color. Typically, a Bayer filter pattern is used, where two green, one red, and
one blue filter cover groups of four pixels, mimicking the human eye's higher sensitivity to green
light. This process generates a full-color image where each pixel contains red, green, and blue
intensity values, which together form the final image.
Once the light intensities are measured, the image is digitized through sampling and quantization:
1. Sampling refers to dividing the continuous visual scene into discrete elements (pixels). The
sampling rate determines the spatial resolution, which is the number of pixels in the image,
commonly expressed as width × height (e.g. 1920 × 1080 pixels). Higher spatial resolution
means finer details in the image.
2. Quantization involves assigning numerical values to each pixel's intensity or color. These
values are stored in a range of levels. The number of levels depends on the bit depth.
Fundamentals image parameters are:
1. Spatial resolution reflects the image's ability to resolve fine details. It's influenced by the
sensor's pixel density and the sampling rate. High spatial resolution means more pixels
represent the image, improving clarity and sharpness.
2. Intensity levels define the range of intensity values a pixel can represent in a grayscale
image. For example, a pixel value of 0 corresponds to black, and 255 corresponds to white in
an 8-bit grayscale image. In color images, each channel (R, G, B) has its range of levels, and
their combinations create the final perceived color.
Digital Images
Sensore
Digital images are stored in various formats, each optimized for specific use cases. The most
common formats include JPEG, GIF, PNG, and TIFF, which differ in compression, quality, and
supported features.
Compression can be:
- Lossless: compression that reduces file size without any loss of data. The original file can be
perfectly reconstructed from the compressed version.
- Lossy: compression that reduces file size by permanently discarding some data deemed less
important. It prioritizes small file size over perfect fidelity.
Different formats exist:
1. JPEG (Joint Photographic Experts Group): Uses lossy compression, which reduces file size
significantly by discarding less critical image data.
Advantages: Ideal for photographs and complex images with gradients. Small file size makes it
suitable for web use and sharing.
Disadvantages: Quality degrades with repeated saving due to cumulative compression loss. Not
ideal for images requiring sharp edges or transparency. Common Use Cases: Photography,
online images, and general-purpose storage.
2. GIF (Graphics Interchange Format): Uses lossless compression but supports only 256 colors
(8-bit color palette).
Advantages: Supports simple animations by storing multiple frames in a single file. Efficient for
small, simple graphics like icons and logos.
Disadvantages: Limited color range makes it unsuitable for detailed images like photographs.
Transparency: Supports binary transparency (a pixel is either fully transparent or opaque).
Common Use Cases: Animated images, simple graphics, and memes.
3. PNG (Portable Network Graphics): Lossless compression, ensuring no loss of quality.
Advantages: Supports millions of colors (24-bit or 32-bit with alpha channel for transparency).
Allows partial transparency, enabling smooth edges. Maintains quality even after multiple saves.
Disadvantages: Larger file sizes compared to JPEG for photographs. Common Use Cases: Web
graphics, logos, and images requiring transparency.
4. TIFF (Tagged Image File Format): Can use lossless or lossy compression, depending on
settings.
Advantages: Excellent for high-quality images and archival purposes. Supports multiple layers,
high bit-depth (e.g., 16-bit or 32-bit), and extensive metadata.
Disadvantages: Very large file sizes. Less commonly supported in consumer applications
compared to other formats. Common Use Cases: Professional photography, printing, and high-
quality image storage.
Formate
A color space is a system for representing colors in a structured way, defining how colors are
created, displayed, and interpreted. Different color spaces serve various purposes, from digital
screens to printing and image processing.
Images can be:
- Additive: by combining light of different colors.
- Subtractive: by removing (or subtracting) light.
RGB (Red, Green, Blue) : The RGB color space is based on the additive color model. It
combines red, green, and blue light to produce a wide range of colors. Each channel (R, G, B)
typically has a value range (e.g. 0–255 in 8-bit images). Thus (0, 0, 0) represents black, and (255,
255, 255) represents white.
Predominantly used for displays like monitors, TVs, and cameras. Suitable for digital images and
multimedia. Brightness increases as more light is added. Not ideal for printing as printers use a
subtractive model.
Color Spaces
Lab (Lightness, Green-Red, Blue-Yellow) : Lab color space is a perceptual model designed to
approximate human vision more closely than other color spaces like RGB or CMYK. It separates
color information into components that correspond to how we perceive lightness and color. It is
particularly useful in color correction and scientific applications. Components of Lab Color Space
are:
- L (Lightness): Represents the brightness of the color. Ranges from 0 (black) to 100 (white).
Independent of color or chromaticity, focusing solely on light intensity.
- a (Green–Red Axis): Represents the position of the color between green (negative values) and
red (positive values). Ranges typically between -128 and +127.
- b (Blue–Yellow Axis): Represents the position of the color between blue (negative values) and
yellow (positive values). Ranges typically between -128 and +127.
The Lab color space is used in Color Correction (adjusting brightness and removing color casts in
photography and editing), Color Matching (ensuring precise reproduction in printing, textiles, and
manufacturing) and Image Processing (separating lightness from color for sharpening,
segmentation, and enhancement).
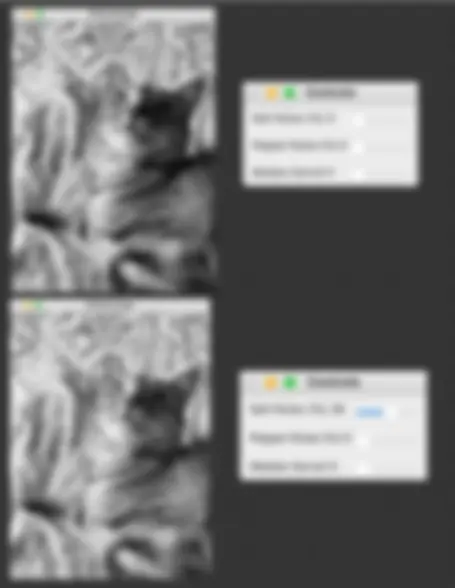
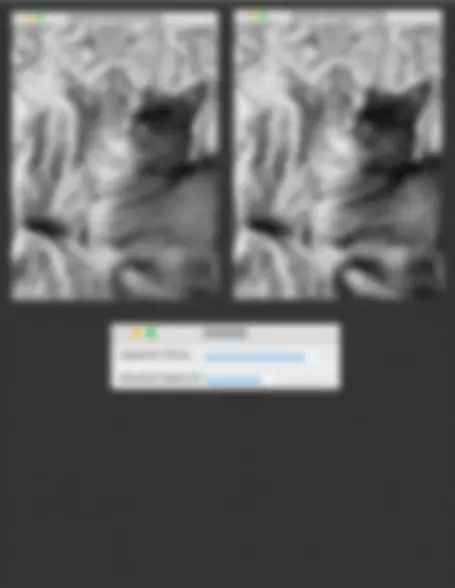
import cv import numpy as np
Callback function for sliders (no-op for interactive purpose)
def nothing(x): pass
Load the image
image_path = './cat.jpg' # Replace with your image path image = cv2.imread(image_path) image = cv2.resize(image, ( 500 , 500 )) # Resize for convenience
Convert to different color spaces
color_spaces = { "BGR": image, "GRAY": cv2.cvtColor(image, cv2.COLOR_BGR2GRAY), "HSV": cv2.cvtColor(image, cv2.COLOR_BGR2HSV), "LAB": cv2.cvtColor(image, cv2.COLOR_BGR2Lab) }
Create a window for each color space
for color_space in color_spaces.keys(): cv2.namedWindow(color_space) channels = 1 if color_space == "GRAY" else 3 for i in range(channels): cv2.createTrackbar(f'Channel {i}', color_space, 128 , 255 , nothing) while True: for space, img in color_spaces.items():
Clone the original image
modified_img = img.copy()
Process based on color space
if space == "GRAY": intensity = cv2.getTrackbarPos('Channel 0', space) modified_img = cv2.add(img, np.full(img.shape, intensity - 128 , dtype=np.uint8)) else:
Split channels and convert to a list for modification
channels = list(cv2.split(modified_img)) for i in range(len(channels)): value = cv2.getTrackbarPos(f'Channel {i}', space) channels[i] = cv2.add(channels[i], np.full(channels[i].shape, value - 128 , dtype=np.uint8)) modified_img = cv2.merge(channels)
Show modified image
cv2.imshow(space, modified_img)
Break loop on 'q'
if cv2.waitKey( 1 ) & 0xFF == ord('q'): break cv2.destroyAllWindows()
Images and Space Colors
An image histogram is a graphical representation of the distribution of pixel intensity values in an
image showing how many pixels have each intensity level:
- For a grayscale image the intensity levels (e.g. 0 for black, 255 for white in 8-bit images).
- For a color image, separate histograms can be computed for each channel (e.g. Red, Green,
and Blue in RGB images).
A histogram can be normalized to represent the probability density function (PDF) of intensity
levels.
The histogram can be interpreted in this way:
- Dark Images: Most pixels have low intensity values (histogram concentrated on the left).
- Bright Images: Most pixels have high intensity values (histogram concentrated on the right).
Image intensity transformations are operations that modify the pixel values of an image to enhance
its visual appearance or extract useful information. These techniques are applied pixel-by-pixel
(point processing). These techniques are used to enhance the visibility and the contrast quality of
the image.
Intensity (^) transformation Histogram
Linear stretching, also called contrast stretching, enhances an image's dynamic range by linearly
mapping its pixel intensity values from a narrow range to a broader, desired range. For instance, if
an image’s pixel values are concentrated between s1 and s2 , linear stretching transforms these
values to span t1 to t2 , often the full intensity range (e.g. 0–255 in an 8-bit image). This
transformation can be expressed mathematically as:
T(k) = (((k − s1)(t2 − t1)) / (s2 −s1)) + t
This is just a line that map the input value into an output value. More lines can be designed to
enhance different pixel value ranges.
- Inclination of the line > 45°: close input values are mapped far from each other (increase
contrast).
- Inclination of the line < 45°: close input values are mapped more close from each other
(decrease contrast).
- Inclination of the line = 45°: input values are not modified.
Linear stretching is particularly useful for images that appear washed out or lack contrast
because the intensity levels are confined to a limited range. By stretching the pixel values, the
image becomes visually sharper and more detailed. This method is simple yet effective for many
applications, especially when a rough enhancement is sufficient.
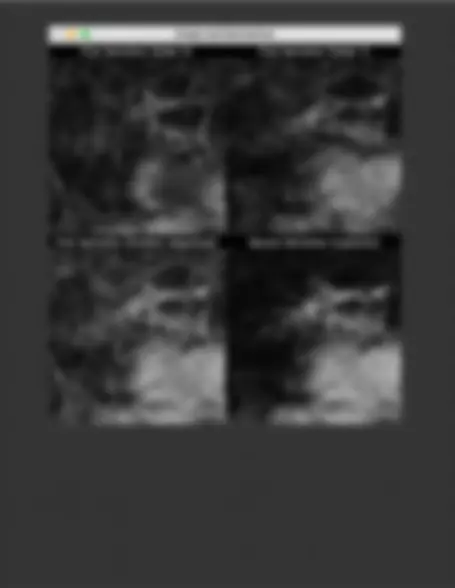
Examples:
Input:
Output:
Linear Stretching
import cv import numpy as np import matplotlib.pyplot as plt def linear_stretching(image, min_val, max_val): """ Perform linear stretching on a grayscale image with adjustable min and max values. Parameters:
- image: Grayscale input image (numpy array).
- min_val: Minimum intensity for stretching.
- max_val: Maximum intensity for stretching. Returns:
- Stretched image.
- Transformation function: Original intensity -> Stretched intensity. """
Ensure valid range
if max_val <= min_val: max_val = min_val + 1
Create transformation line
x = np.arange( 256 ) transformation_line = np.clip((x - min_val) / (max_val - min_val) * 255 , 0 , 255 ).astype(np.uint8)
Apply linear stretching
stretched_image = transformation_line[image] return stretched_image, transformation_line def update_transformation(val): """ Callback function to update the image transformation and plot based on slider values. """ global axes, transformation_ax # Access the Matplotlib axes globally
Get current slider positions
min_val = cv2.getTrackbarPos("Min", "Interactive Stretching") max_val = cv2.getTrackbarPos("Max", "Interactive Stretching")
Perform linear stretching
stretched_image, transformation_line = linear_stretching(image, min_val, max_val)
Update the displayed stretched image
cv2.imshow("Stretched Image", stretched_image)
Plot the transformation line and histograms
axes[ 0 ].cla() plot_histogram(image, "Original Image Histogram", axes[ 0 ]) axes[ 1 ].cla() plot_histogram(stretched_image, "Stretched Image Histogram", axes[ 1 ]) transformation_ax.cla() transformation_ax.plot(transformation_line, label="Transformation Line") transformation_ax.set_title("Transformation Function") transformation_ax.set_xlabel("Original Intensity") transformation_ax.set_ylabel("Transformed Intensity") transformation_ax.grid() transformation_ax.legend() plt.draw() def plot_histogram(image, title, ax): """ Plot the histogram of an image. Parameters:
- image: Grayscale image (numpy array).
- title: Title of the histogram.
- ax: Matplotlib axis to plot the histogram. """ ax.hist(image.ravel(), bins= 256 , range=( 0 , 255 ), color='gray', alpha=0.7) ax.set_title(title) ax.set_xlabel('Pixel Intensity') ax.set_ylabel('Frequency')
Linear Stretching
Logarithmic transformations are non-linear adjustments that map intensity values to a logarithmic
scale, enhancing low-intensity values while compressing high-intensity values. The transformation
is defined as:
T(k) = c⋅log(1+k)
where c is a scaling constant, typically chosen to preserve the original intensity range. This
technique is especially effective for enhancing details in dark images, where most of the pixel
values are concentrated in the lower intensity range. By expanding these values, subtle details
become more visible, while bright regions are prevented from oversaturating.
Logarithmic transformations are frequently used in applications such as medical imaging or
scientific visualization, where revealing fine details in low-intensity areas is crucial. However,
because they compress high-intensity values, these transformations are less suitable for images
requiring uniform contrast across the intensity range.
Examples:
Gamma transformation, also called gamma correction, is another non-linear technique that
adjusts an image’s intensity values based on a power-law function:
T(k)=c⋅kγ
Here, c is a scaling factor, and γ (gamma value) determines the nature of the transformation:
- γ<1: Brightens the image by amplifying low-intensity values.
- γ>1: Darkens the image by compressing high-intensity values.
- γ=1: Leaves the image unchanged.
Gamma transformation is widely used in correcting display outputs, as monitors and other
devices do not linearly represent intensity levels. It’s also valuable for preparing images for
specific visual tasks, like improving the brightness of underexposed photographs or reducing
glare in overexposed ones.
A key advantage of gamma correction is its flexibility, as different γ values can be applied to
achieve various effects. However, inappropriate γ selection may either wash out the image or
make details indistinguishable.
Log transform U (^) transform