Scarica Appunti Data Analysis e più Appunti in PDF di Management Analysis And Systems solo su Docsity!
Lezione n.
PROBABILITA’: è una misura della possibilità che un evento possa verificarsi:
(numero di casi favorevoli/ numero di prove) Rapporto tra numero di casi favorevoli e numero di prove che ho fatto, al crescer del numero delle prove il n di casi favorevoli / il n di conti diventa una stima della probabilità, quando i casi tendono all’infinito si ha la probabilità. 0 è quello che corrisponde al fatto in cui il numeratore è 0 e cioè nessuna delle prove ha dato positivo quindi è impossibile, 1 cioè tutte le prove sono andate bene. Se la somma delle probabilità di tutti gli eventi possibili è 1 allora. La probabilità è una misura che ci dice quanto è possibile che un evento accada. Esempio: se lanci una moneta, la probabilità di ottenere testa è 50%, cioè 0,5. Secondo l’approccio frequentista , la probabilità si calcola così: p=numero di casi favorevoli/ numero di prove
- Casi favorevoli : quante volte succede quello che ci interessa (es. esce testa). -Numero di prove : quante volte facciamo l’esperimento (es. numero di lanci). Importante: questo valore diventa stabile quando il numero di prove è molto grande (tende a infinito). Se lanci la moneta 2 volte puoi avere 2 teste di fila → sembra che la probabilità sia 1. Ma se la lanci 1000 volte, vedrai che si stabilizza vicino a 0,5. Intervallo della probabilità: 0 ≤ p ≤ 1 Se p=1 → l’evento è certo (accade sempre). Se p=0 → l’evento è impossibile (non accade mai). Se 0<p<1 → l’evento è possibile , con più o meno probabilità
Somma delle probabilità: La probabilità totale di tutti gli eventi possibili deve essere uguale a 1: (Se non so dove prendere i dati devo prendere i dati storici degli anni scorsi)
Distribuzioni di probabilità: DISTRIBUZIONE DI FREQUENZA vs
PROBABILITA’
-Distribuzioni di frequenza → sono quelle che ricavi dai dati reali che
hai osservato (quelli del tuo campione).
Esempio: chiedi a 1000 persone di dare un voto da 1 a 10 a un prodotto. Poi fai un grafico con quanti hanno risposto 1, quanti 2, quanti 3… e così via. Questo è basato su dati osservati.
-Distribuzioni di probabilità → sono i modelli teorici che usiamo per
descrivere o prevedere come si distribuiscono i dati.
Esempio: la famosa curva a campana (distribuzione normale) che descrive come molte cose reali tendono a distribuirsi (altezze, voti, preferenze…). A cosa servono? Esistono tantissimi tipi di distribuzioni, ognuna adatta a rappresentare fenomeni diversi. Alcune sono più adatte per contare eventi (tipo i dadi), altre per grandezze continue (come peso, tempo, altezza) Due tipi principali di distribuzioni: -Discrete → quando i valori che osservi sono “a scalini”, cioè contabili, interi (Esempio: numero di figli in una famiglia (0, 1, 2, 3…) -Continue → quando i valori sono su una scala continua, con infinite possibilità (Esempio: altezza di una persona (può essere 1,65 m, 1,651 m, 1,6512 m… e così via). Il grafico nella slide:
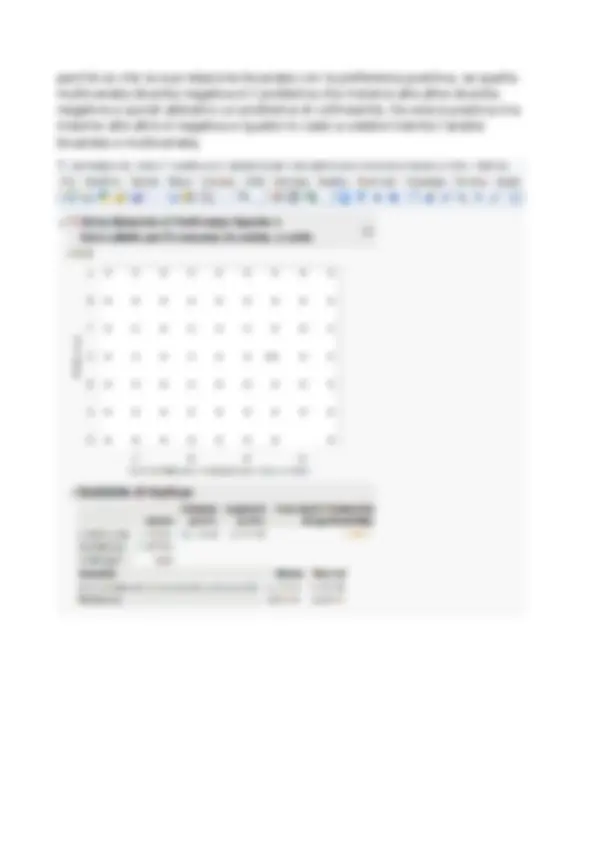
il massimo quando il dado blu vale 1 il massimo del rosso è 6 1 è un caso solo su 36 e quindi = 0,03, se la somma dei valori porta 1 allora è giusto Basta che uno dei due dadi sia 6 che si mangia i valori dell’altro. N è il conteggio dei valori, quante volte è presente 1 o 2 o 3 ecc nella tabella? -in Frequenza che sono l’associazione di tutti i possibili valori della variabile con la frequenza con cui si sono mostrati Le distribuzioni di prob sono i modelli teorici che generalizzano questo fenomeno I fenomeni causali possono essere presentati da probabilità diverse La distribuzione teorica descritta dalla linea nera presenta bene il modello teorico. La differenza tra continuo e discreto è cruciale: -variabile discreta sono variabili che possono descrivere solo variabili discrete (ad ese il lancuo di dati) -variabili continue (una cosa che può assumere qualunque valore)
DISCRETE : il lancio di un dado per esempio. Capire quali sono i valori che
possono venrie fuori quando lancio un dado e sono numeri interi da 1 a 7, poi associare ad ognuno di quetsi valori la coppia Per il lancio di un dado la distribuzione di prob è quella mostrata dal grafico in alto a destar e i valori sono quelli da 1 a 6, ogni faccia ha prob 1/ L’elenco di tutti i possibili valori e per ogni valore Se io aumento il n di prove quella distr di frequenza sperimenatle diventa di probabilità, il n di casi favorevoli su ciascuno dei casi possibili diventa sempre lo stesso e quindi le prob sono distribuite Siamo un call center che telefona delle persone per intervistarle : chiamiamo successo se riusciamo a prendere la linea e facciamo diversi tentativi indipendenti (che significa che ogni nostro tentativo è individuale e quindi non influenzato dal tentativo precedente), qual è la prob di chiamare n volte per provare a prendere la linea? Quante volte devo richimare se la prob individuale è 0,2 se voglio prendere la linea? DISTRIBUZIONE CONTINUE : la differenza è il modo in cui i due tipi rappresenatno la probabilità. Rapp la probabilità attravrso una curva continua che esprime la prob nel seguente modo. La prob di avere valori tra a e b è l’area sotto la curva
compresa tra a e b. Sarebbe l’area sotto la curva. La curva quindi non
indica proprio la prob perché la prob è l’area sotto. La prima conseguenza è che quindi l’area totale sotto la curva è una e quindi se è vero che l’area è la prob di avere valori tra a e b, l’area sotto rapp la prob di avere valori tra minimo e massimo, la somma delle prob discrete è 1 e quindi l’area totale sotto la curva è 1. LA seconda conseguenza è che la prob di un singolo punto è 0, x=a è 0. Facciamo scorree b verso a fino a che coincide con a, a quel punto otteniamo la prob di a ma a questo punto l’area non esiste più perché è area 0. L’area la ottengo stringendo fino al punto in cui i due punti coincidono ma a quel punto l’area è zero. Sul piano applicativo significa che nessuno ha 23 anni e nessuno ha qualcosa e quindi la prob è 0 e rimane tutto 0.
ci sono tanti account con pochi followers il punto esclamativo cosa indica? Il n di follower o di accessi giornalieri è un dato discreto (numero intero) ma è un nuemero talmente grande che poi diventa irrilevante e quindi si usa una approssimazione. Dobbiamo chiederci se è simmetrico o no, ha una coda da entrambe le parti o ne ha una sola? Nel secondo grafico abbiamo code da entrambe le parti ma diverse, una corta e una lunga.
Nel terzo grafico abbiamo la linea azzurra che è una distribuzione uniforme.
L’esempio di un fenomeno distribuito così, cioè in maniera uniforme è il tempo di attesa della metro ad esempio. MENO DI 0 minuti non si può aspettare. Gli unici valori diversi da 0 sono da 0 a 3. Se noi siamo fortunati che scegliamo di fare le scale e arriviamo in tempo abbiamo un tempo di attesa pari 0, se no facciamo in tempo a prenderlo abbiamo un tempo di attesa pari a 3 minuti. Questo è casuale però e quindi la distribuzione è uniforme, cioè che la prob di aspettare tra 0 e 1 minuto è uguale alla prob di aspettare tra 1 e 2 minuti, dipende da quando arrivo, che a sua volta è uguale tra aspettare tra 2 e 3 minuti. Ci si deve chiedere sempre se è simettrica o meno, se ha delle code o no, A cosa serve riconoscere una distribuzioen di prob di un fenomeno? Permette di rispondere a domande come: qual è la prob di avere valori tra a e b? qual è la prob di avere valori maggiori o minori di a? Esempio di applicazione della normale (N)
E quindi qual è l’area a destra della normale? (dobbiamo calcolare l’area blu) e questa si calcola via software Se ci sono più di 700 clienti al giorno è un problema Se invece che 100 la deviazione standard è più piccola, la prob aumenterà o diminuirà? La curva si stringe (variabnza minore), la coda esterna al 700 a sinistra diventa più piccola mentre la parte a destra diventa più grande Al variare del parametro, quando il valore diventa più grande la mia distribuzione diventa sempre più grande, con ottima approssimazione simmetrica Quando i parametri crescono tendono a diventare normali. Abbaimo visto che di normali ce ne sono un infinità al variare della varianza. Tra tutte le normali ne scegliamo una come criterio standard rispetto a tutte le altre. Dobbiamo scegliere i parametri più comodi
Per la media è 0 e varianza 1 (non scegliamo 0 perché in varianza 0 è
costante, non ci sarebbe area, non c’è distribuzione di probabilità e quindi non ci sarebbe niente) X= La variabile distribuita con media 0 e varianza 1 si chiama “z” per sottolinerae che ogni variabile x può essere trasformata in una normale standard. Formula per la standardizzazione: Ci dice che per ottenere Z dobbiamo fare queste operazioni. x-u significa prendere la curva e portarla a 0, fa scorrere la curva verso destra o sinistra per mettere apposto la media. Dividiamo tutto per sigma cioè per 2 e quindi stringiamo la curva sempre di più
dire su questo dato? C’è una relazione lineare? SI. È di tipo crescente e il coefficiente di relazine sarà positivo e la varianza sarà positiva. Nel pezzo in basso ci da la media, la deviazione standard, il valore della varianza, quante sono le unità statistiche e il coeff di Pierson. Tra vendite e pubb c’è una correlazione molto alta, varianza positiva e il coeff di correlazione è molto vicino a 1 e quindi è buono questo significa che i punto sono vicini nel creare una linea Di questa seconda relazione cosa possiamo dire? C’è correlazione negativa. All’inizio possiamo dire che non c’è una correlazione molto alta sembra quasi una correlazione non lineare di tipo parabolico (sembra una parabola piuttosto che una retta). Con le statiche di riepilogo possiamo dire che la correlazione è -0,2 vuol dire che c’è una bssa correlazione tra velocità di servizio e percentuale di prime palle. Secondo voi, questa correlazione che è molto bassa VEDERE CORRELAZIONE Cosa succede quando una o più variabili non sono quantitative? Abbiamo ad ese una variabile quantitativa (importo scontrino) e una non Importo scontrino è diverso in funzione della modalità di pagamento? Utilizzo la media, per ogni modalità di pagamento vado a vedere gli scontrini. Relazione tra due variabili categoriche: non sono quantitative ma posso dargli un ordine. Andiamo a vedere se c’è una relazione tra il grado di soddisfazione del lavoro e la produttività delle persone. L’ associazione è la relazione tra due variabili di tipo categorico. Per vedere se c’è relazione utilizzeremo le frequenze marginali (sono quelle colorate di rosso all’esterno della tabella che rapp le somme) e quelle interne alla tabella che si chiamano frequenze congiunte. Dobbiamo costruire prima di tutto la TABELLA DI INDIPENDENZA che riporta i dati all’interno della stessa come se le variabili fossero tra loro indipendenti. Adesso costruiamo quella che si chiama la tabella delle CONTINGENZE che è la differenza tra la bella di partenza e la tabella di indipendenza.
La tabella di indi è quella che ci dice questa è la situa se non c’è correlazione tra le variabili mentre quella delle contingenze è la differenza tra le prime due. Se due variabili sono indipendenti in teoria le frequenze osservate sono uguali a quelle teoriche, cioè quelle he sono state costruite sulle ipotesi di indipendenza. LA tab delle contingenze viene fuori per differenza delle prime due. Quella di indipendenza ci dice che sono c’è correlazione tra le due variabili dati verrebbero mostrati così. In questo caso le contingenze all’interno della tabella non sono uguali a 0, quindi possiamo dire che c’è ASSOCIAZIONE tra le due variabili e quindi non indipendenti. Se fossero state quantitative avremmo detto che c’è correlazione. Più le prime due tabelle sono diverse più ci sarà associazione tra le variabili, più le contingenze si avvicinano a 0 più si dice che c’è poca associazione. Se si avvicinano a 0 NON C’è ASSOCIAZIONE. Per misura l’intensità di questa associazione utilizziamo l’indice di Pearson (1999). Noi calcoliamo una nuova tabelal che è quella delle contingenze al quadrato (la tab delle contingenze è la differenz atra le prime due e la dobbiamo portare al quadrato). Al denominatore andiamo a mettere la tabella di indipendenza diviso i dati VALORI DELLA TABELLA DELLA CONTINGENZA / VALORI DELLA TABELLA DI INDIPENDENZA Il chi quadro di PEARSON serve a Più è grande il valore di x alla seconda, cioè, chi quadro più Se vogliamo fare un parallelo è come la covarianza, più è grande la co-varianza e più valore c’è. Il Chi quadro ha un limite, che cresce al crescere del collettivo. Più dati metto dentro e pi+ diventa grande e quindi Pearson dice che bisogna dividere i valore per N , cioè il chi quadro (x alla seconds) che viene fuori bisogna dividerlo pe N. Questo indice è uguale a 1 quando il n di righe o di colonne è uguale 2. CRAMER invece inventa un indice che risolve il problema. Si divide l’indice di Pearson per il minimo tra righe -1 e colonne -1. Quanto più l’associzione è perfetta se ci avviciniamo a 1 COSA BISOGNA SAPERE PER L’ESAME: Bisogna sapere cs’è una tabella di indipendenza, delle contingenze, cosa fa l’indice di Peasron (somma delle differenze tra le contingenze al quadrato rapportate alla tabella
- la stima intervallare (intervallo di confidenza) è la stima puntuale ampliata con l'errore campionario. es. stima puntuale: 34 errore: 3. intervallo di confidenza: (34 – 3.5; 34 + 3.5) → (30.5; 37.5) → conoscere la distribuzione campionaria serve a calcolare l'errore Aumentando la dimensione del campione mi avvicino alla media vera e sono più preciso ma aumentare la dimensione del campione costa. La legge dei grandi numeri ci dice che è prob della media dei campioni è sempre più vera
INTREVALLO DI CONFIDENZA DELLA MEDIA : La probabilità di trovare un
campione buono rispetto a uno sbagliato. (quello che bisogna sapere per l’esame è: campione probabilistico e cosa vuol dire calcolare la probabilità) Immagina di voler conoscere la media reale (vera, sconosciuta) di una popolazione — ad esempio: “Qual è la spesa media mensile degli studenti universitari?” Non puoi chiedere a tutti (la popolazione ), quindi prendi un campione (un
gruppo di persone rappresentativo) e calcoli la media campionaria x´. Ma
questa media del campione è solo una stima della media vera μ — e può
variare se scegli un altro campione. Quindi vogliamo sapere quanto possiamo fidarci di quella stima. L’ intervallo di confidenza (IC) serve proprio a esprimere un margine di incertezza intorno alla media campionaria. Invece di dire: “La media è 20” diremo: “Siamo fiduciosi al 95% che la vera media sia compresa tra 18,5 e 21,5” Questo intervallo si calcola così (quando conosciamo la varianza della popolazione
2 ):
Come si interpreta? Il valore 1,96 viene dalla distribuzione normale standard : indica che il 95% dei valori si trova entro ±1,96 deviazioni standard dalla media. Quindi, se ripetessimo il campionamento moltissime volte, il 95% degli intervalli costruiti in questo modo conterrebbe la vera media μ.
Non significa che c’è il 95% di probabilità che μ stia dentro
quell’intervallo, ma che la procedura ha il 95% di successo nel lungo periodo. Da cosa dipende l’ampiezza dell’intervallo? L’ampiezza (cioè quanto largo è l’intervallo) dipende da tre fattori:
- Distribuzione campionaria
La media campionaria x´ segue una distribuzione normale centrata su μ
con varianza σ 2 / n.
Più grande è n , più piccola è la varianza (e quindi l’intervallo si
restringe).
- Livello di confidenza scelto o 95% → coefficiente 1, o 99% → coefficiente 2, o 90% → coefficiente 1, → Maggiore è la confidenza , più ampio sarà l’intervallo (per essere più “sicuri”, allarghiamo il margine).
Parliamo di associazione quando i caratteri NON sono quantitativi. Il coeff di Pearson si usa solo per i caratteri quantitativi. Per caratteri categoriali usami il chi-quadro o il coeff di Kramer La differenza in media invece la usiamo per un caratt quantitativo e uno categoriale. Il reddito che tipo di variabile è? L’analisi Univariata lavora per un analisi alla volta, è adatta per esaminare la distribuzione di una singola variabile come l’età. Indice di Kramer Indice Peasron misura una relazione positiva e negativa mentre l’indice di Kramer varia tra 0 e 1 dove 0 indica nessuna associazione e 1 indica una forte associazione (non ha segno quindi) Il sondaggio serve per creare un campione stratificato probabilistio INSTAPOL: è QUANDO VIENE FUORI QUANDO SI CHIUDONO I SEGGi, si cheide alle persone di entrare inuna cabia e di ripetere il voto che ha fatto, anche qui dipende dalla sincerità del lettore Le proiezioni elettorali arrivao dopo due ore DEMOGRAFIA E SVILUPPO SOSTENIBILE: Recuperare lezione 6.
LEZIONE 7:
Parliamo di CORRELAZIONE. Per fare analisi bivariate bisogna cliccare su stima di x e y su Jmp. La corr è 0,78, è alta e significa che al crescere della variabile cresce anche l’altra. Sul piano interpretativo vuol dire che la freschezza è un attrivuto della qalità , che non si da qualità senza freschezza, le due vanno insieme MA TENDENZIALMENTE. Perché a volte cis ono casi anomali che è un caso drammatico, come l’ultimo punto che dice che sono molto freschi ma hanno una qualità bassissima (ultimo pallino). Possiamo ipotizzare che fare molte offerte sia una strategia per compensare la bassa qualità? (come si può vedere nell’ultimo pallino nello schema). Bisogna fare una correlazione tra qualità e promozioni. Se le promozioni si usano per compensare la bassa qualità, che corr ne uscirà fuori? Sarà negativa, se cresce la qualità diminuiscono le promozioni perché non ci sarà bisogna della pubblicità se la qualità si alza. La correlazione è positiva ma molto debolmente e significa che di promozioni ne fanno un po' tutti ma non dipende dalla qualità. Questi sono modi alternativi o complementari? Chi è orientato al mercato fa un po' di una e un po' dell’altra? O chi fa promozioni non fa pubblicità?
Se sono complementari viene fuori una
correlazione positiva.
è uscita che è complementare (0,33), la correlazione è positiva ma bassa (c’è comunque una preferenza ma tendenzialmente chi fa una ne fa un po' anche dell’altra) e quindi è complementare e non sono alternativi.
È significativo, cioè c’è una media che vale più delle altre, una che è diversa dalle altre,. Se non è significativo significa che sono tutte uguali le medie e quindi ci serve a poco. Qua bisogna andare a vedere quali sono quelle più alte o basse perché fanno la differenza nel nostro mercato. Dobbiamo guardare le medie e il grafico. C’è una media quella riguardante i prodotti locali che è nettamente più alta delle altre I prodotti locali sono di un livello più alto ma la significatività dell’Anova è tutta da attribuire ai prodotti locali o c’è una differenza anche in altre medie? Le altre mantengono delle differenze tra loro o no? Anche tra gli altri ci sono differenze anche se piccole ma ci sono e questo lo capiamo togliendo “prodotti locali” e andando a vedere il filtro sui dati locali. È significativo, cioè, che le marche escluse non sono tutte uguali tra loro (cioè Labirt) e il valore del chi-quadrato. L’INDIPENDENZA , significa che le march si distribuiscono allo stesso modo in tutte le aree mentre se sono dipendente (c’è una relazione) vuol dire che la distribuzione nelle aree non è la stessa e
Granarolo come si distribuisce nelle aree? 72% al nord e pochi al centro e sud, mentre gli altri in modo uniforme mentre Boiano Como e Francia sono le marche di Roma e quindi si distribuiscono meglio al centro, infine, i prodotti locali sono prettamente del sud. Questa cosa si vedeva molto bene anche nel grafico. Questo test è super significativo e questo lo capiamo andando a vedere il chi quadrato. Dentro a Granarolo Nord ho trova to molti casi e quindi c’è un’alta concentrazione di Granarolo nel nord.
Questo test non è significativo, questo significa
che non c’è correlazione VARIANZA (concentrazione all’interno di un gruppo) ENTRO I GRUPPI E TRA I GRUPPI : Come ragiona l’analisi della varianza?