Scarica Guida Python pacchetto pandas e più Slide in PDF di Programmazione Avanzata solo su Docsity!
pandas
#pandas
Sommario
- Di
- Capitolo 1: Iniziare con i panda
- Osservazioni
- Versioni
- Examples
- Installazione o configurazione
- Installa via anaconda
- Ciao mondo
- Statistiche descrittive
- Capitolo 2: Aggiunta a DataFrame
- Examples
- Aggiunta di una nuova riga a DataFrame
- Aggiungi un DataFrame ad un altro DataFrame
- Capitolo 3: Analisi: riunire tutto e prendere decisioni
- Examples
- Analisi quintile: con dati casuali
- Qual è un fattore
- Inizializzazione
- pd.qcut - Crea pd.qcut
- Analisi
- Riporta il grafico
- Visualizza la correlazione scatter_matrix con scatter_matrix
- Calcola e visualizza Maximum Draw Down
- Calcola statistiche
- Capitolo 4: Calendari delle festività
- Examples
- Crea un calendario personalizzato
- Usa un calendario personalizzato
- Ricevi le vacanze tra due date
- Contare il numero di giorni lavorativi tra due date
- Capitolo 5: Creazione di DataFrames
- introduzione
- Examples
- Creare un campione DataFrame
- Crea un campione DataFrame usando Numpy
- Crea un campione DataFrame da più raccolte utilizzando Dizionario
- Crea un DataFrame da un elenco di tuple
- Crea un DataFrame da un dizionario di liste
- Creare un campione DataFrame con datetime
- Creare un campione DataFrame con MultiIndex
- Salva e carica un DataFrame nel formato pickle (.plk)
- Crea un DataFrame da un elenco di dizionari
- Capitolo 6: Dati categoriali
- introduzione
- Examples
- Creazione di oggetti
- Creazione di set di dati casuali di grandi dimensioni
- Capitolo 7: Dati duplicati
- Examples
- Seleziona duplicato
- Eliminato duplicato
- Conta e ottieni elementi unici
- Ottieni valori unici da una colonna.
- Capitolo 8: Dati mancanti
- Osservazioni
- Examples
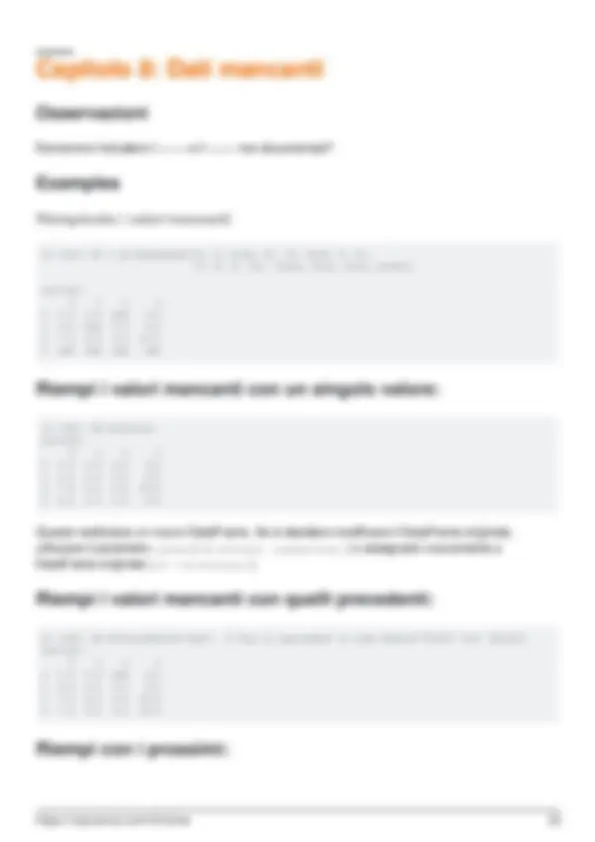
- Riempiendo i valori mancanti
- Riempi i valori mancanti con un singolo valore:
- Riempi i valori mancanti con quelli precedenti:
- Riempi con i prossimi:
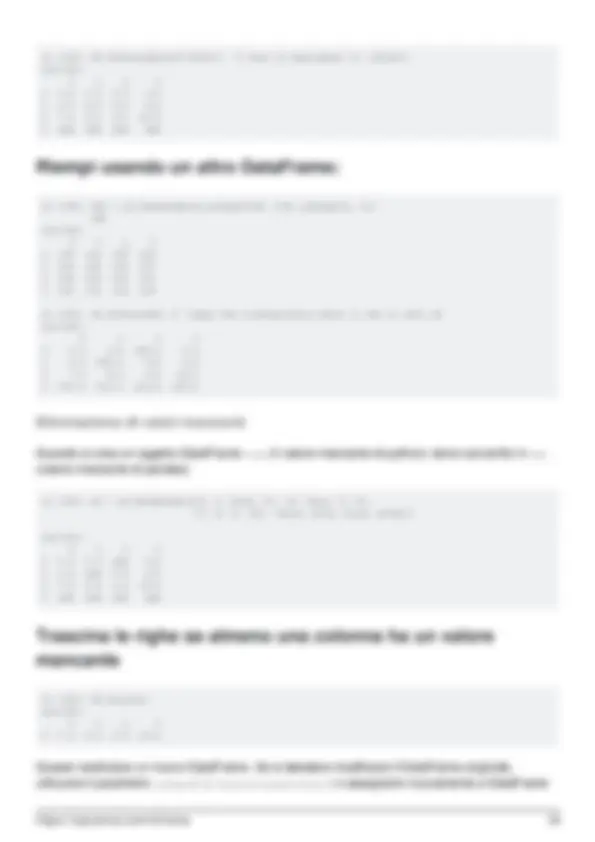
- Riempi usando un altro DataFrame:
- Eliminazione di valori mancanti
- Trascina le righe se almeno una colonna ha un valore mancante
- Trascina le righe se mancano tutti i valori in quella riga
- Rilascia colonne che non hanno almeno 3 valori non mancanti
- interpolazione
- Verifica dei valori mancanti
- Capitolo 9: Gotchas di panda
- Osservazioni
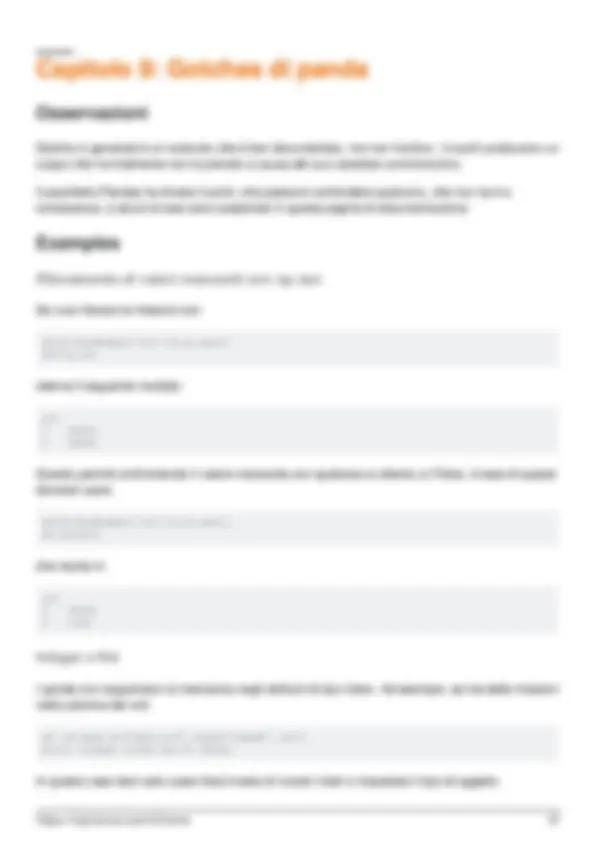
- Examples
- Rilevamento di valori mancanti con np.nan
- Integer e NA
- Allineamento automatico dei dati (comportamento basato sull'indice)
- Capitolo 10: Grafici e visualizzazioni
- Examples
- Grafici dati di base
- Disegnare la trama
- Tracciare su un asse matplotlib esistente
- Capitolo 11: Indicizzazione booleana dei dataframes
- introduzione
- Examples
- Accesso a un DataFrame con un indice booleano
- Applicazione di una maschera booleana ad un dataframe
- Mascheramento dei dati in base al valore della colonna
- Mascherare i dati in base al valore dell'indice
- Capitolo 12: Indicizzazione e selezione dei dati
- Examples
- Seleziona colonna per etichetta
- Seleziona per posizione
- Affettare con etichette
- Posizione mista e selezione basata sull'etichetta
- Indicizzazione booleana
- Filtraggio delle colonne (selezionando "interessante", non necessario, utilizzando RegEx,
- genera campione DF
- mostra colonne contenenti la lettera 'a'
- Mostra colonne utilizzando il filtro RegEx (b|c|d) - b o c o d :
- mostra tutte le colonne tranne quelle che iniziano con a (in altre parole rimuovi / rimuov
- Filtrare / selezionare le righe usando il metodo .query ()
- generare DF casuale
- selezionare le righe in cui i valori nella colonna A > 2 e i valori nella colonna B <
- usando il metodo .query() con le variabili per il filtraggio
- Affettatura dipendente dal percorso
- Ottieni la prima / ultima n file di un dataframe
- Seleziona righe distinte su dataframe
- Filtra le righe con dati mancanti (NaN, None, NaT)
- Capitolo 13: IO per Google BigQuery
- Examples
- Lettura dei dati da BigQuery con le credenziali dell'account utente
- Lettura dei dati da BigQuery con le credenziali dell'account di servizio
- Capitolo 14: JSON
- può passare una stringa di JSON, o un percorso di file in un file con JSON valido
- Dataframe in JSON annidato come nei file flare.js utilizzati in D3.js
- Leggi JSON dal file
- Capitolo 15: Lavorare con Time Series
- Examples
- Creazione di serie temporali
- Indicizzazione parziale delle stringhe
- Ottenere dati
- subsetting
- Capitolo 16: Leggi MySQL su DataFrame
- Examples
- Utilizzando sqlalchemy e PyMySQL
- Per leggere mysql in dataframe, in caso di grandi quantità di dati
- Capitolo 17: Leggi SQL Server su Dataframe
- Examples
- Utilizzando pyodbc
- Utilizzando pyodbc con loop di connessione
- Capitolo 18: Lettura dei file in DataFrame panda
- Examples
- Leggi la tabella in DataFrame
- File di tabella con intestazione, piè di pagina, nomi di riga e colonna indice:
- File tabella senza nomi di riga o indice:
- Dati con intestazione, separati da punti e virgola anziché virgole
- Tabella senza nomi di riga o indice e virgole come separatori
- Raccogli i dati del foglio di calcolo google in dataframe panda
- Capitolo 19: Manipolazione delle stringhe
- Examples
- Espressioni regolari
- Affettare le corde
- Verifica del contenuto di una stringa
- Capitalizzazione di stringhe
- Capitolo 20: Meta: linee guida per la documentazione
- Osservazioni
- Examples
- Visualizzazione di frammenti di codice e output
- stile
- Supporto per la versione di Pandas
- stampare dichiarazioni
- Preferisco supportare python 2 e 3:
- Capitolo 21: MultiIndex
- Examples
- Seleziona da MultiIndex per livello
- Iterare su DataFrame con MultiIndex
- Impostazione e ordinamento di un MultiIndex
- Come modificare le colonne MultiIndex in colonne standard
- Come cambiare le colonne standard in MultiIndex
- Colonne MultiIndex
- Visualizzazione di tutti gli elementi nell'indice
- Capitolo 22: Ottenere informazioni su DataFrames
- Examples
- Ottieni informazioni su DataFrame e utilizzo della memoria
- Elenca i nomi delle colonne DataFrame
- Le varie statistiche di riepilogo di Dataframe.
- Capitolo 23: Pandas Datareader
- Osservazioni
- Examples
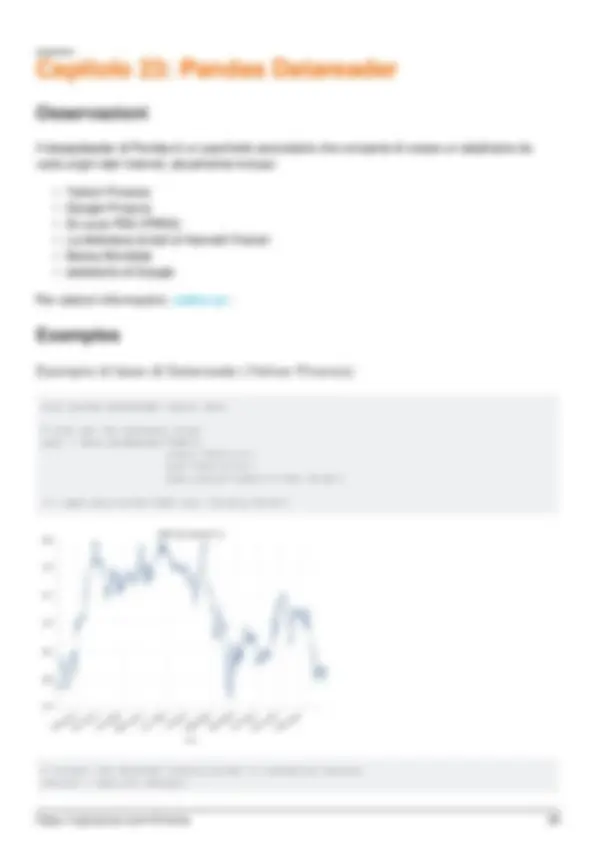
- Esempio di base di Datareader (Yahoo Finance)
- Lettura di dati finanziari (per più ticker) nel pannello pandas - demo
- Capitolo 24: pd.DataFrame.apply
- Examples
- pandas.DataFrame.apply Uso di base
- Capitolo 25: Raggruppamento di dati
- Examples
- Raggruppamento di base
- Raggruppa per una colonna
- Raggruppa per colonne multiple
- Raggruppamento di numeri
- Selezione della colonna di un gruppo
- Aggregazione per dimensione in base al conteggio
- Gruppi aggreganti
- Esporta gruppi in diversi file
- utilizzando la trasformazione per ottenere statistiche a livello di gruppo preservando il
- Capitolo 26: Raggruppamento di dati di serie temporali
- Examples
- Genera serie temporali di numeri casuali e poi giù campione
- Capitolo 27: Rendere i panda divertenti con i tipi di dati nativi di Python
- Examples
- Spostamento dei dati da panda nelle strutture native di Python e Numpy Data
- Capitolo 28: ricampionamento
- Examples
- Downsampling e upsampling
- Capitolo 29: Rimodellamento e rotazione
- Examples
- Semplice rotazione
- Facendo perno con l'aggregazione
- Impilabile e disimpilabile
- Tabulazione incrociata
- I panda si sciolgono per andare da larghi a lunghi
- Dividi (risagoma) le stringhe CSV in colonne in più righe, con un elemento per riga
- Capitolo 30: Salva pandas dataframe in un file csv
- Parametri
- Examples
- Crea un DataFrame casuale e scrivi in .csv
- Salva Pandas DataFrame da elenco a dicts a csv senza indice e con codifica dei dati
- Capitolo 31: Semplice manipolazione di DataFrames
- Examples
- Elimina una colonna in un DataFrame
- Rinominare una colonna
- Aggiungere una nuova colonna
- Assegna direttamente
- Aggiungi una colonna costante
- Colonna come espressione in altre colonne
- Crealo al volo
- aggiungi più colonne
- aggiungi più colonne al volo
- Individua e sostituisci i dati in una colonna
- Aggiunta di una nuova riga a DataFrame
- Elimina / elimina righe da DataFrame
- Riordina colonne
- Capitolo 32: Serie
- Examples
- Esempi di creazione di serie semplici
- Serie con datetime
- Alcuni suggerimenti rapidi su Series in Pandas
- Applicazione di una funzione a una serie
- Capitolo 33: Sezioni trasversali di diversi assi con MultiIndex
- Examples
- Selezione delle sezioni trasversali usando .xs
- Utilizzando .loc e affettatrici
- Capitolo 34: Spostamento e ritardo dei dati
- Examples
- Spostando o ritardando i valori in un dataframe
- Capitolo 35: Strumenti computazionali
- Examples
- Trova la correlazione tra le colonne
- Capitolo 36: Strumenti IO di Pandas (lettura e salvataggio di set di dati)
- Osservazioni
- Examples
- Lettura file CSV in DataFrame
- File:
- Codice:
- Produzione:
- Alcuni argomenti utili:
- Salvataggio di base in un file CSV
- Date di analisi durante la lettura da CSV
- Foglio di calcolo a dettare di DataFrames
- Leggi un foglio specifico
- Testare read_csv
- Comprensione delle liste
- Leggi in blocchi
- Salva nel file CSV
- Parsing date columns with read_csv
- Leggi e unisci più file CSV (con la stessa struttura) in un unico DF
- Leggendo il file cvs in un frame di dati panda quando non c'è una riga di intestazione
- Utilizzando HDFStore
- genera DF di esempio con vari tipi di dtype
- fare un DF più grande (10 * 100.000 = 1.000.000 di righe)
- creare (o aprire un file HDFStore esistente)
- salva il nostro frame di dati nel file h5 (HDFStore), indicizzando le colonne [int32, int6
- mostra dettagli HDFStore
- mostra colonne indicizzate
- chiudere (flush su disco) il nostro file di archivio
- Leggi il log di accesso di Nginx (più quotechar)
- Capitolo 37: Tipi di dati
- Osservazioni
- Examples
- Verifica dei tipi di colonne
- Cambiare i dtypes
- Cambiando il tipo in numerico
- Modifica del tipo in data / ora
- Cambiando il tipo in timedelta
- Selezione delle colonne in base al dtype
- Riassumendo i dtypes
- Capitolo 38: Trattare con variabili categoriali
- Examples
- Codifica unica con get_dummies ()
- Capitolo 39: Unisci, unisciti e concatena
- Sintassi
- Parametri
- Examples
- fondersi
- Unione di due DataFrames
- Join interno:
- Join esterno:
- Unire a sinistra:
- Giusto Iscriviti
- Unione / concatenazione / unione di più frame di dati (orizzontalmente e verticalmente)
- Unisci, Unisci e Concat
- Qual è la differenza tra join e merging
- Capitolo 40: Utilizzando .ix, .iloc, .loc, .at e .iat per accedere a un DataFrame
- Examples
- Utilizzando .iloc
- Utilizzando .loc
- Capitolo 41: Valori Mappa
- Titoli di coda
Capitolo 1: Iniziare con i panda
Osservazioni
Pandas è un pacchetto Python che fornisce strutture di dati veloci, flessibili ed espressive
progettate per rendere il lavoro con dati "relazionali" o "etichettati" sia facile che intuitivo. Mira ad
essere il blocco fondamentale di alto livello per fare analisi pratiche dei dati reali in Python.
La documentazione ufficiale di Pandas può essere trovata qui.
Versioni
Pandas
Versione Data di rilascio
https://riptutorial.com/it/home 2
Versione Data di rilascio
Examples Installazione o configurazione
Istruzioni dettagliate su come installare o installare i panda possono essere trovate qui nella
documentazione ufficiale.
Installazione di panda con Anaconda
Installare panda e il resto dello stack NumPy e SciPy può essere un po 'difficile per gli utenti
inesperti.
Il modo più semplice per installare non solo i panda, ma Python e i pacchetti più popolari che
compongono lo stack SciPy (IPython, NumPy, Matplotlib, ...) è con Anaconda , una piattaforma
multipiattaforma (Linux, Mac OS X, Windows) Distribuzione Python per analisi dei dati e calcolo
scientifico.
Dopo aver eseguito un semplice programma di installazione, l'utente avrà accesso ai panda e al
resto dello stack SciPy senza bisogno di installare altro e senza dover attendere la compilazione
di alcun software.
Le istruzioni di installazione per Anaconda possono essere trovate qui.
Un elenco completo dei pacchetti disponibili come parte della distribuzione di Anaconda può
essere trovato qui.
Un ulteriore vantaggio dell'installazione con Anaconda è che non è necessario disporre dei diritti di
amministratore per installarlo, verrà installato nella home directory dell'utente e ciò rende inoltre
banale l'eliminazione di Anaconda in un secondo momento (basta eliminare tale cartella).
Installazione dei panda con Miniconda
La sezione precedente delineava come ottenere i panda installati come parte della distribuzione di
Anaconda. Tuttavia, questo approccio implica l'installazione di oltre un centinaio di pacchetti e
comporta il download del programma di installazione di poche centinaia di megabyte.
Se vuoi avere più controllo su quali pacchetti, o avere una larghezza di banda internet limitata,
installare dei panda con Miniconda potrebbe essere una soluzione migliore.
Conda è il gestore di pacchetti su cui è costruita la distribuzione di Anaconda. È un gestore di
pacchetti che è indipendente dalla piattaforma e dalla lingua (può giocare un ruolo simile a una
combinazione pip e virtualenv).
Miniconda consente di creare un'installazione Python autonoma e minimale, quindi utilizzare il
comando Conda per installare pacchetti aggiuntivi.
https://riptutorial.com/it/home 3
un compilatore per compilare i bit di codice richiesti e può richiedere alcuni minuti per essere
completato.
Installa via anaconda
Per prima cosa scarica anaconda dal sito Continuum. Tramite il programma di installazione grafico
(Windows / OSX) o eseguendo uno script di shell (OSX / Linux). Questo include i panda!
Se non vuoi che i 150 pacchetti siano comodamente raggruppati in anaconda, puoi installare
miniconda. Tramite il programma di installazione grafico (Windows) o lo script di shell (OSX /
Linux).
Installa i panda su miniconda usando:
conda install pandas
Per aggiornare i panda all'ultima versione in anaconda o miniconda usare:
conda update pandas Ciao mondo
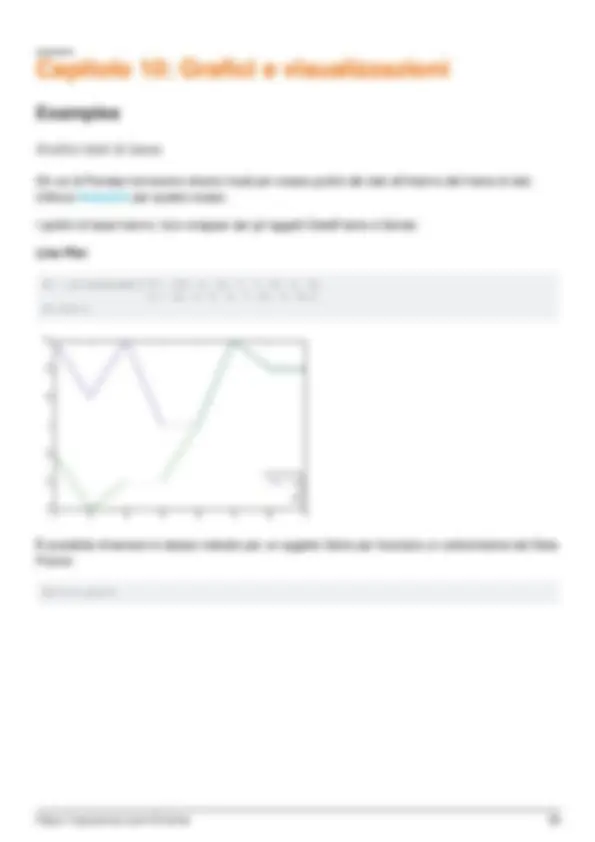
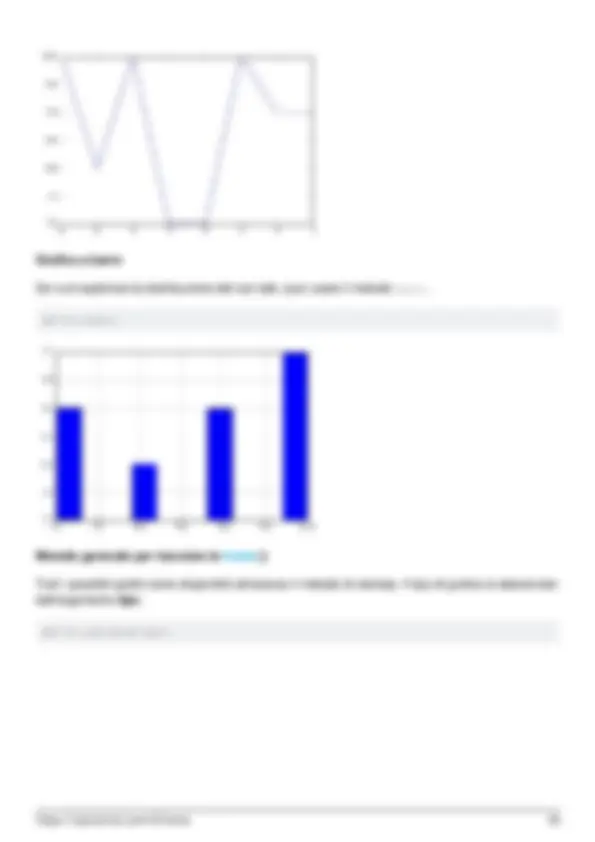
Una volta installato Pandas, è possibile verificare se funziona correttamente creando un set di dati
con valori distribuiti casualmente e tracciando il proprio istogramma.
import pandas as pd # This is always assumed but is included here as an introduction. import numpy as np import matplotlib.pyplot as plt np.random.seed(0) values = np.random.randn(100) # array of normally distributed random numbers s = pd.Series(values) # generate a pandas series s.plot(kind='hist', title='Normally distributed random values') # hist computes distribution plt.show()
https://riptutorial.com/it/home 5
Controlla alcune delle statistiche dei dati (media, deviazione standard, ecc.)
s.describe()
Output: count 100.
mean 0.
std 1.
min -2.
25% -0.
50% 0.
75% 0.
max 2.
dtype: float
Statistiche descrittive
Le statistiche descrittive (media, deviazione standard, numero di osservazioni, minimo, massimo e
quartili) di colonne numeriche possono essere calcolate utilizzando il metodo .describe() , che
restituisce un dataframe panda di statistiche descrittive.
In [1]: df = pd.DataFrame({'A': [1, 2, 1, 4, 3, 5, 2, 3, 4, 1], 'B': [12, 14, 11, 16, 18, 18, 22, 13, 21, 17], 'C': ['a', 'a', 'b', 'a', 'b', 'c', 'b', 'a', 'b', 'a']}) In [2]: df Out[2]: A B C 0 1 12 a
https://riptutorial.com/it/home 6
Capitolo 2: Aggiunta a DataFrame
Examples Aggiunta di una nuova riga a DataFrame In [1]: import pandas as pd In [2]: df = pd.DataFrame(columns = ['A', 'B', 'C']) In [3]: df Out[3]: Empty DataFrame Columns: [A, B, C] Index: []
Aggiunta di una riga per un singolo valore di colonna:
In [4]: df.loc[0, 'A'] = 1 In [5]: df Out[5]: A B C 0 1 NaN NaN
Aggiunta di una riga, dato un elenco di valori:
In [6]: df.loc[1] = [2, 3, 4] In [7]: df Out[7]: A B C 0 1 NaN NaN 1 2 3 4
Aggiunta di una riga a un dizionario:
In [8]: df.loc[2] = {'A': 3, 'C': 9, 'B': 9} In [9]: df Out[9]: A B C 0 1 NaN NaN 1 2 3 4 2 3 9 9
Il primo input in .loc [] è l'indice. Se si utilizza un indice esistente, si sovrascriveranno i valori in tale
riga:
In [17]: df.loc[1] = [5, 6, 7]
https://riptutorial.com/it/home 8
In [18]: df Out[18]: A B C 0 1 NaN NaN 1 5 6 7 2 3 9 9 In [19]: df.loc[0, 'B'] = 8 In [20]: df Out[20]: A B C 0 1 8 NaN 1 5 6 7 2 3 9 9 Aggiungi un DataFrame ad un altro DataFrame
Supponiamo di avere i seguenti due DataFram:
In [7]: df Out[7]: A B 0 a1 b 1 a2 b In [8]: df Out[8]: B C 0 b1 c
Non è necessario che i due DataFrames abbiano lo stesso set di colonne. Il metodo append non
modifica nessuno dei DataFrames originali. Invece, restituisce un nuovo DataFrame aggiungendo
i due originali. Aggiungere un DataFrame a un altro è abbastanza semplice:
In [9]: df1.append(df2) Out[9]: A B C 0 a1 b1 NaN 1 a2 b2 NaN 0 NaN b1 c
Come puoi vedere, è possibile avere indici duplicati (0 in questo esempio). Per evitare questo
problema, puoi chiedere a Panda di reindicizzare il nuovo DataFrame per te:
In [10]: df1.append(df2, ignore_index = True) Out[10]: A B C 0 a1 b1 NaN 1 a2 b2 NaN 2 NaN b1 c
Leggi Aggiunta a DataFrame online: https://riptutorial.com/it/pandas/topic/6456/aggiunta-a-
https://riptutorial.com/it/home 9