


Costruzione di librerie
Vettori
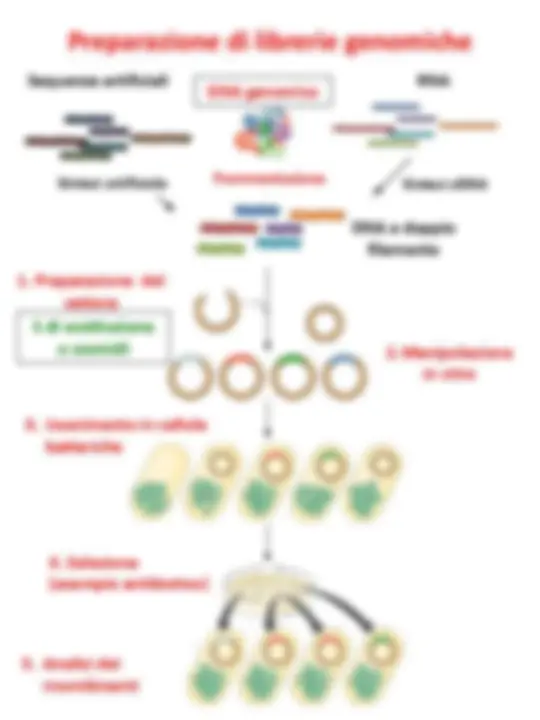
Librerie genomiche
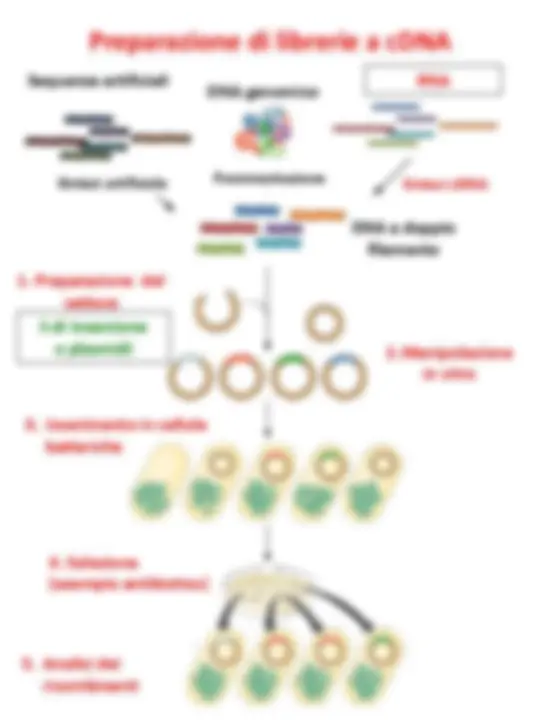
Librerie a cDNA
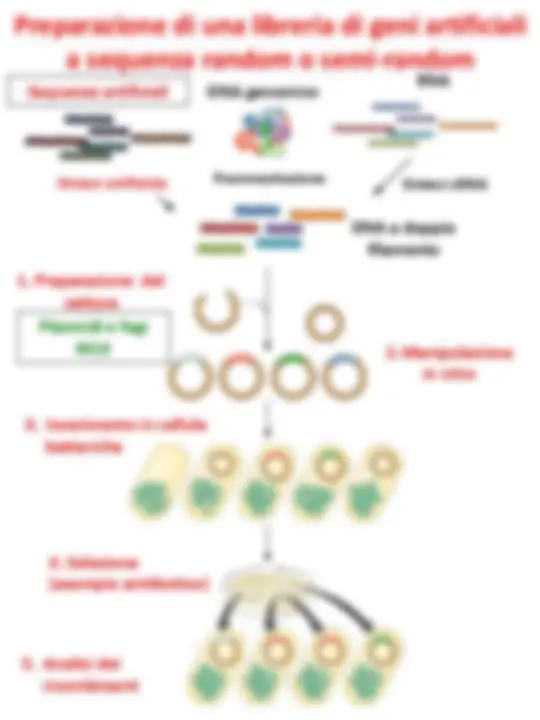
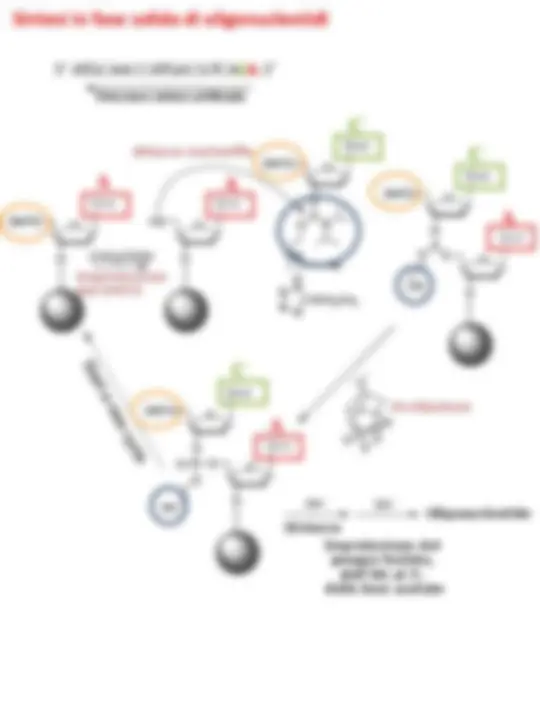
Librerie di geni artificiali a
sequenza random o semi-random
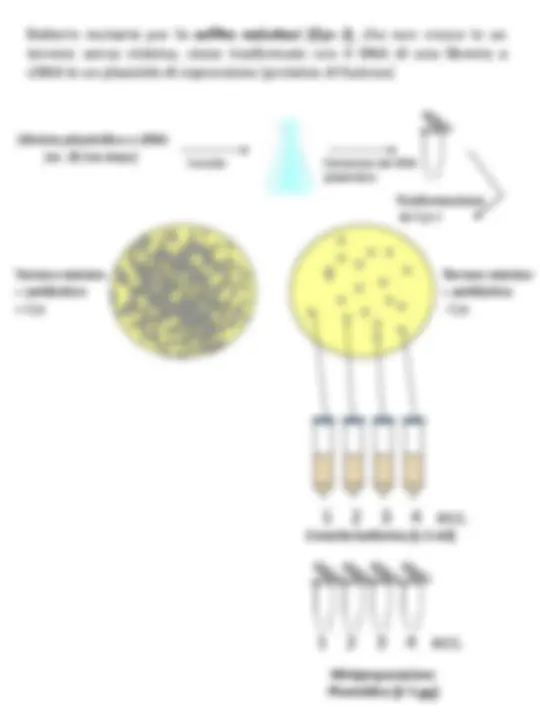
Analisi e screening di librerie






































Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
materiale per l'esame di tecnologie del dna ricombinante
Tipologia: Slide
1 / 53

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
2. Manipolazione in vitro 3. Inserimento in cellule batteriche
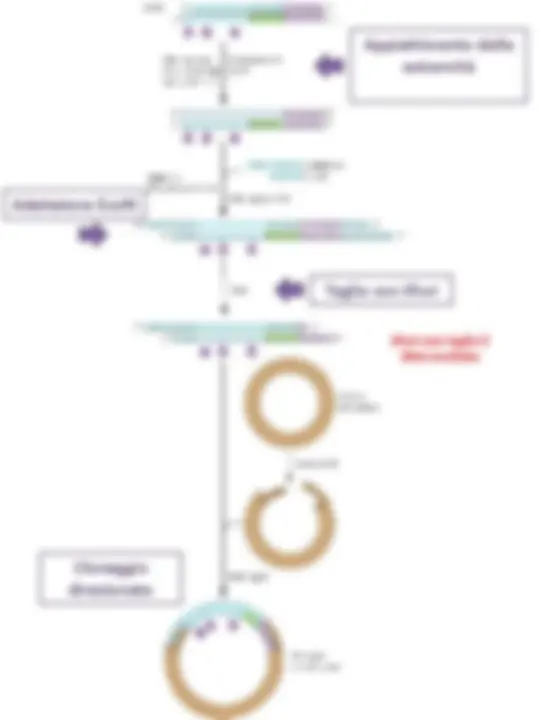
DNA genomico
Sequenze artificiali RNA
Sintesi cDNA
DNA a doppio filamento
1. Preparazione del **vettore
Sintesi artificiale
Frammentazione
2. Manipolazione in vitro 3. Inserimento in cellule batteriche
DNA genomico Sequenze artificiali RNA
Frammentazione (^) Sintesi cDNA
DNA a doppio filamento
1. Preparazione del **vettore
λ di sostituzione o cosmidi
Sintesi artificiale
E E
E E
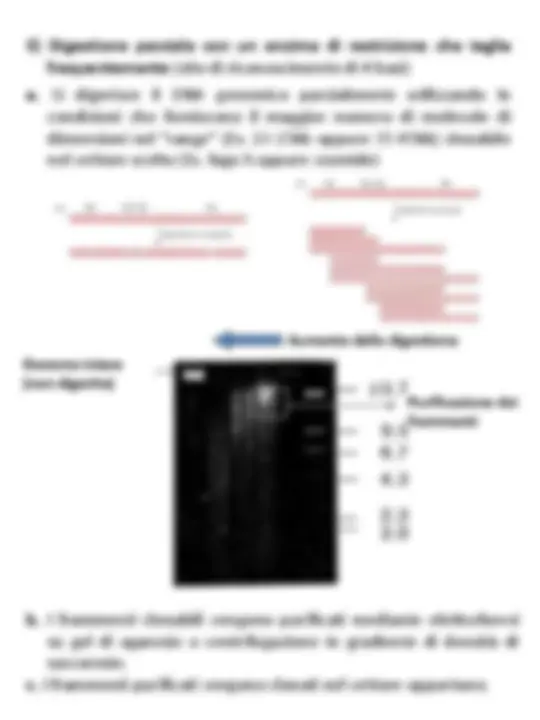
2) Frammentazione meccanica (“mechanical shearing”) E’ una frammentazione veramente casuale, ma il DNA così ottenuto viene sottoposto a diversi passaggi prima del clonaggio, riducendo l’efficienza di clonazione (a volte insufficiente per ottenere librerie rappresentative dell’intero genoma). I frammenti vanno convertiti in DNA con estremità compatibili con il vettore, e questo richiede molti passaggi
1. Sonicazione 3. Appiattimento delle estremità 2. Purificazione dei frammenti della dimensione desiderata 35-45kb
4a. Ligazione di adaptor
4b.1. Metilazione (es. metilasi Eco RI)
4b.2. Ligazione di linker (es linker Eco RI) 4b.3.^ Restrizione (es. Eco RI)
Defosforilazione inserti 5’P 5’P
Bam HI Sau 3AI o MBo I
Defosforilazione inserti 5’P 5’P
Nel caso della costruzione di librerie genomiche la defosforilazione degli inserti impedisce di clonare due frammenti genomici nello stesso vettore. Se questo succedesse, si avrebbero delle mappature genomiche scorrette
Domanda : Quanti cloni devo produrre (e analizzare) per avere la certezza di isolare qualunque gene o frammento di DNA? Ovvero quale deve essere la complessità della mia libreria?
Dimensione del genoma 2.8 10^9 bp n = = = 1.4 10^5 Dimensione media dei frammenti 20 ˙000 bp
Poiché nel clonaggio si esegue una sorta di campionamento (alcuni frammenti si clonano più volte, mentre altri raramente), il numero N di cloni ricombinanti che è necessario produrre per avere la probabilità P di includere nella libreria ogni particolare sequenza, è data dalla formula: ln (1 - P) N = ln (1 – 1/n)
Es. Se P = 95%, allora per una libreria genomica umana con inserti da 20 kb si dovrà produrre:
Es. Se P = 99% :
ln (1-0.95) N = = 4.2 10^5 cloni ln (1 – 1/ 1.4 10^5 )
ln (1-0.99) N = = 6.5 10^5 cloni ln (1 – 1/ 1.4 10^5 )
n aumenta se si vogliono cloni sovrapposti
Per il DNA genomico umano (2.8 10^9 bp), se i frammenti (di dimensione media di 20kb) fossero indipendenti il numero n di cloni da produrre sarebbe:
Organism
Approximate DNA content of haploid genome (bp)
N for 20 kb inserts (λ vector)
N for 45 kb inserts (cosmid)
Escherichia coli 4,2 x 10^6 9,2 x 10^2 4,3 x 10^2 (bacterium) Saccharomyces cerevisiae 1,4 x 10^7 3,2 x 10^3 1,4 x 10^3 (yeast) Drosophila melanogaster 1,4 x 10^8 3,2 x 10^4 1,4 x 10^4 (fruit fly) Stronglyocentrotus purpuratus 8,6 x 10^8 2,0 x 10^5 8,8 x 10^4 (sea urchin) Homo sapiens 3,3 x 10^9 7,6 x 10^5 3,4 x 10^5 (man) Triricum aestivum 1,7 x 10^10 3,9 x 10^6 1,7 x 10^6 (hexaploid wheat)
The Number (N) of independent recombinant DNA molecules that must be recovered in either a Lambda Replacement Vector, or a Cosmid, in order to have a 99% probability of having cloned a particular DNA Sequence
A seconda della dimensione del genoma iniziale e del tipo di vettore utilizzato, le librerie genomiche hanno una complessità che va da centinaia a milioni di cloni
Una collana da 100 perle di colore differente. Quante perle N devo prelevare dal sacco per avere la probabilità P di ricostruire la collana?
Es. Se P = 95%,
Es. Se P = 99.99% :
ln (1 - 0.95) N = = 392 perle ln (1 – 1/ 100)
ln (1 - 0.9999) N = = 916 perle ln (1 – 1/ 100)
Repetitive DNA 52%
Exons 1%
Introns 24%
Intergenic DNA 23%
Human genome
ACACATCCGCACCGCATTTTCTTAAACGGCCGACAAGTGACGGGCATCAT TGCCCATTAAGGCAGGTTACAATCCGTGATGATGGGATAGTATATCACAT AACCGCTCTGGGAGGAAGAGGGGAAACATCGTGGTTCATGTCAAGTGTGT GTGTGTGTGTGGTGTGTGTTTGACTCGTCGATCGACACCTTACATGCTAA CTTCGACGTCGAGAGCCCGCACAGAGAGAGGGAAGGGGGGGGGGGGGGGG GGGGGGGGGGGGGGGGAGAGGCACCGAGAAGGGAGGTATAAGGACCGGGC CGTCTGGCCCAGTTGAGAATAAAAGGAATCCTTCTCTTCTATGTGCCAGC ACTTCAGCAATCCACGGTTCTACCTGGTTCCTCATCTTCATCTACCATCA AGATGAAGTTCTTCTCTGCCCTCGCCCTCTCCTCTCTCCTGCCGACGGCC GCATGGGCCTGGACCGGCAGCGAAAGCGACAGTACCGGCGCCGACTCCCT CTTCCGCCGCGCCGAAACCATCCAGCAGACGACGGACCGATACCTTTTTA GGATCACGCTCCCGCAATTTACTGCCTATCGCAACGCCAGAAGCCCGGCG ACACTGGACTGGTCCTCAGACAGCTGCAGCTACTCGCCCGATAACCCGTT GGGATTCCCCTTTTCGCCTGCTTGCAATCGTCATGATTTCGGGTATCGCA ACTACAAGGCTCAGTCGAGGTTTACGGATAATAATAAGTTGAAGATTGAT GGAAACTTTAAGAGTGAGTATGTCCCTTTTTTTTTTTCTCTCTCTTTCTC TCTCTCTCTCTTTTCCTCCCTCGTTTTATTCCTCTTGTCTCATCCTTCCC CTTGCTTACCTACCTACCCTTCTCCCTTTTTACCCGTCAACGGTCTCCAT CTCTCTTCACATCCTCCTCCGTGAGTAGATTTGATAAAACAGATAGCTAA TCCAACCCTCAACCAACTACATAGTCTCTACTACCAGTGCGACACCCACG GCTACGGCTCCACCTGCCACGCTCTCGCCAACGTCTACTACGCCGCCGTC CGCGAATTTGGTCGCACCAAGGGCGAGCTCCAGGAGGAATACGATCTGCT GCTGGCTCACTACAACGAGCTCGTGGCCGAGGCTATTGCCAAGGGCGAGG ATCCGTTGTATTATTAGTTAATTCAACTGGAAAGGGTGACGAAAGGCCGC TCTCTATCCTCATTATAGACACAGACAACGCTCACCTACGGGTACACTTC ACACACGAGTTTCTCCCTACAAACTTTGTCTTACGTTCATTTTCTCATCA ATCCACAATGCTGTCCCGTTTCATGGGCCATGCCATTTTACATTGCACTT TTGGCTGGTAACAATGACTGGCGCTTGTCCGCAAACGATCAAGTTCCTCA CTTCATCCTCCCAGGGTCAAAGTCAGTCGGCGCTTTAATTTCGCCGCCGC TTCAATCCAAACACCTCCATTCAGAAGACACTCAAAGTGCTGATTAGATT GCAGCATATGTGTGGCTTGGTTTCAGAGCATCGCCATTGCTTGTACATAA CGACATGATCTTTCCACCGCCACTAGAGGCGGTTCTCTGATACTTGGTCT ACCGGCGTGGTATCTTGCAGTCCGCGAACAGAACTCGGCTTGATTTATCC ATCGTCAAGTATCCATCACCCGTCACCCGACCAACCCCACAGATATACCT ACCGCTTATGTTGTAACCGGCACAACTCAACAATTCTTCCGGCCTCCTCT CCTACCTTACCCACCAGTAACGGCTGGTCCTATCCCAGTCCAAGCAAGTT CCCAACGTCTTGGCTCTTGAATCACCGGGAATGTAACCCCATCTTGCTGA AAGAGGATCGACTGTGGATGCCAAGACGTGATGAAACCTACGTGCCTTGC ATGGATACTGTAGTAGTAACTAGTATCCGTTCGCAGTTTCTTTCTGTTCT
Esone 1
Esone 2
Introne
ACACATCCGCACCGCATTTTCTTAAACGGCCGACAAGTGACGGGCATCAT TGCCCATTAAGGCAGGTTACAATCCGTGATGATGGGATAGTATATCACAT AACCGCTCTGGGAGGAAGAGGGGAAACATCGTGGTTCATGTCAAGTGTGT GTGTGTGTGTGGTGTGTGTTTGACTCGTCGATCGACACCTTACATGCTAA CTTCGACGTCGAGAGCCCGCACAGAGAGAGGGAAGGGGGGGGGGGGGGGG GGGGGGGGGGGGGGGGAGAGGCACCGAGAAGGGAGGTATAAGGACCGGGC CGTCTGGCCCAGTTGAGAATAAAAGGAATCCTTCTCTTCTATGTGCCAGC ACTTCAGCAATCCACGGTTCTACCTGGTTCCTCATCTTCATCTACCATCA AGATGAAGTTCTTCTCTGCCCTCGCCCTCTCCTCTCTCCTGCCGACGGCC GCATGGGCCTGGACCGGCAGCGAAAGCGACAGTACCGGCGCCGACTCCCT CTTCCGCCGCGCCGAAACCATCCAGCAGACGACGGACCGATACCTTTTTA GGATCACGCTCCCGCAATTTACTGCCTATCGCAACGCCAGAAGCCCGGCG ACACTGGACTGGTCCTCAGACAGCTGCAGCTACTCGCCCGATAACCCGTT GGGATTCCCCTTTTCGCCTGCTTGCAATCGTCATGATTTCGGGTATCGCA ACTACAAGGCTCAGTCGAGGTTTACGGATAATAATAAGTTGAAGATTGAT GGAAACTTTAAGAGTGAGTATGTCCCTTTTTTTTTTTCTCTCTCTTTCTC TCTCTCTCTCTTTTCCTCCCTCGTTTTATTCCTCTTGTCTCATCCTTCCC CTTGCTTACCTACCTACCCTTCTCCCTTTTTACCCGTCAACGGTCTCCAT CTCTCTTCACATCCTCCTCCGTGAGTAGATTTGATAAAACAGATAGCTAA TCCAACCCTCAACCAACTACATAGTCTCTACTACCAGTGCGACACCCACG GCTACGGCTCCACCTGCCACGCTCTCGCCAACGTCTACTACGCCGCCGTC CGCGAATTTGGTCGCACCAAGGGCGAGCTCCAGGAGGAATACGATCTGCT GCTGGCTCACTACAACGAGCTCGTGGCCGAGGCTATTGCCAAGGGCGAGG ATCCGTTGTATTATTAGTTAATTCAACTGGAAAGGGTGACGAAAGGCCGC TCTCTATCCTCATTATAGACACAGACAACGCTCACCTACGGGTACACTTC ACACACGAGTTTCTCCCTACAAACTTTGTCTTACGTTCATTTTCTCATCA ATCCACAATGCTGTCCCGTTTCATGGGCCATGCCATTTTACATTGCACTT TTGGCTGGTAACAATGACTGGCGCTTGTCCGCAAACGATCAAGTTCCTCA CTTCATCCTCCCAGGGTCAAAGTCAGTCGGCGCTTTAATTTCGCCGCCGC TTCAATCCAAACACCTCCATTCAGAAGACACTCAAAGTGCTGATTAGATT GCAGCATATGTGTGGCTTGGTTTCAGAGCATCGCCATTGCTTGTACATAA CGACATGATCTTTCCACCGCCACTAGAGGCGGTTCTCTGATACTTGGTCT ACCGGCGTGGTATCTTGCAGTCCGCGAACAGAACTCGGCTTGATTTATCC ATCGTCAAGTATCCATCACCCGTCACCCGACCAACCCCACAGATATACCT ACCGCTTATGTTGTAACCGGCACAACTCAACAATTCTTCCGGCCTCCTCT CCTACCTTACCCACCAGTAACGGCTGGTCCTATCCCAGTCCAAGCAAGTT CCCAACGTCTTGGCTCTTGAATCACCGGGAATGTAACCCCATCTTGCTGA AAGAGGATCGACTGTGGATGCCAAGACGTGATGAAACCTACGTGCCTTGC ATGGATACTGTAGTAGTAACTAGTATCCGTTCGCAGTTTCTTTCTGTTCT
Regione contenente il promotore
Regione contenente il terminatore (sito di poliadenilazione)
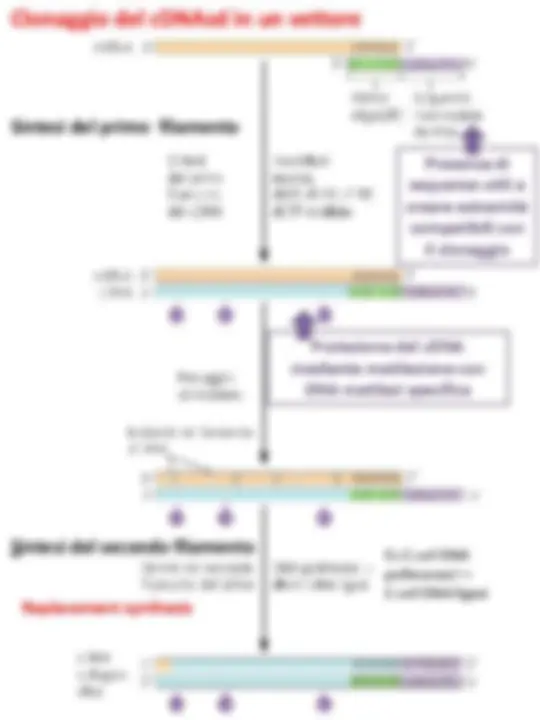
La sintesi del cDNA a doppio filamento avviene in due fasi:
Esistono due trascrittasi inverse che possono essere utilizzate:
Il cDNA può quindi essere inserito in un vettore opportuno (plasmide o fago λ).
Preparazione del cDNA