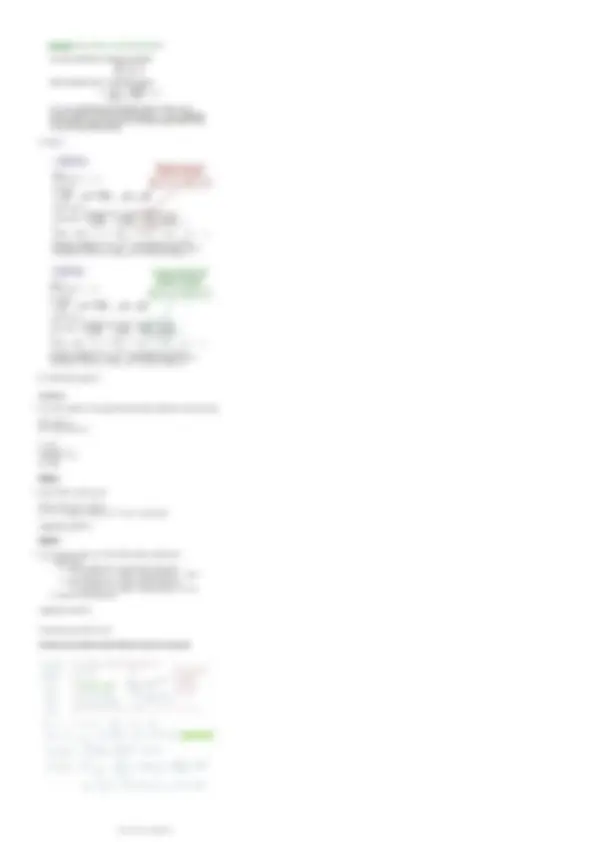
Scarica Statistica - Esame intero e più Dispense in PDF di Statistica solo su Docsity!
STATISTICA DESCRITTIVA UNIVARIATA
- Studio di 1 carattere alla volta (ci interessa 1 sola variabile/carattere)
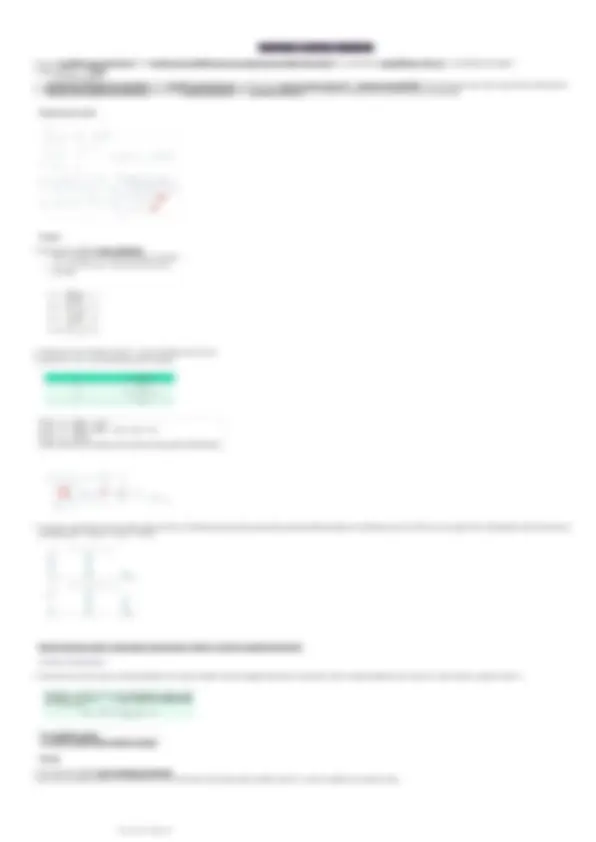
MATRICE DEI DATI
Dati
- La statistica tratta i dati e qualsiasi analisi statistica presuppone che i dati siano organizzati in modo che i risultati non siano influenzati dalla cattiva costruzione del database.
Le regole fondamentali sono:
○ verifica delle fonti
verifica della qualità dei dati
▪ alcuni dati possono essere trascritti a mano e possono esserci quindi errori di trascrizione
○ creazione della matrice dei dati
Database (base di dati) = matrice dei dati
Tabella formata dalle osservazioni di tutti i dati rilevati per ogni elemento oggetto dell'indagine
○ tabella formata dalle modalità di tutti i caratteri rilevati per unità statistica
- Modo per organizzare i dati
- Unità statistiche (osservazioni) = righe
- Variabili = colonne
Esempio
- Eurisko: i bilancio delle famiglie italiane nel 1998 questionario capofamiglia
Indagine fornita dalla banca d'italia
Informazioni riguardanti:
○ struttura famiglia
○ occupazione e redditi
○ strumenti di pagamento e forme di risparmio
○ abitazioni e altri beni immobiliari
○ consumi e spese familiari
○ forme assicurative
Righe = famiglie
○ unità statistiche (soggetto indagine)
Colonne = struttura famiglia ecc.. (informazioni scritte sopra)
○ variabili d'interesse
Colonna request (numero che identifica le unità statistiche) = c'è in vari database
altre colonne sono altre variabili d'interesse (numeri con virgola o interi dipende dalla variabile, parole)
variabili qualitative = titolo studio e stato civile
Terminologia
Unità statistiche o sperimentali = oggetto indagine (righe della matrici dati)
○ supporto fisico/materiale su cui si manifesta il fenomeno
○ spesso sono persone o volte in cui ripeto un esperimento
Caratteri (colonne della matrice di dati e sono variabili d'interesse)
misurazione di alcune proprietà dell’unità sperimentale
▪ qualitativi = qualità
▪ quantitativi = numeri
Modalità del carattere = modi di manifestazione del carattere, ovvero i diversi valori di quel determinato carattere
attributi = caratteri qualitativi
▪ operaio, dirigente, insegnate sono attributi del carattere lavoro
misure = caratteri quantitativi
▪ ore totali lavorative
- Caratteri = colonne
- Unità statistiche = righe
- Modalità/osservazioni = dentro della matrice dei dati
Caratteri
Qualitativi/categorici
STATISTICA
venerdì 21 marzo 2025 21:
Quantitative/metrici
Caratteri qualitativi
Modalità = attributi del carattere (parole molto spesso e descrivono una caratteristica dell'unità statistica misurabile)
Sconnessi (scala nominale): non sono ordinabili e misurabili (non c'è un unico modo per ordinare le modalità del carattere)
○ binario (SI/NO, D’ACCORDO/NON D’ACCORDO…)
○ tipo di operatore telefonico (TIM, VODAFONE…)
○ comune di residenza
Ordinati (scala ordinale): si possono ordinare in modo univoco le modalità del carattere e non sono misurabili
titolo studio
▪ non posso avere la laurea triennale senza prima aver fatto il liceo
○ grado di vendibilità (scarto, difettoso, idoneo)
○ risultato di un esame (insuff, suff, buono, ottimo)
Devo pensare al significato del carattere (caratteristica qualitativa) e non alla sua codifica
Osservazione
Non ha senso confrontare distanze tra modalità (anche se codificate con valori numerici e c'è un ordinamento) quando ho caratteri qualitativi, ma sono diverse risposte ordinate che do a un questionario. Questo è
importante in quanto molti degli indici statistici che vengono definiti per caratteri quantitativi (media, varianza) sono definiti a partire dalle distanze e non avrà senso calcolare una media tra questo tipo di valori
Caratteri quantitativi
Numeri reali che descrivono una proprietà oggettiva dell’unità statistica
discreti
insieme di modalità = finito (numeri interi)
▪ nr. componenti famiglia
continui
insieme di modalità = infinito (numeri reali)
▪ altezza in cm/m di una persona
Non devo fermarmi a vedere se c'è la virgola o no per stabilire se il carattere è continuo o discreto
Reddito = anche se è un numero intero è un carattere continuo (ci può essere un numero con la virgola, non necessariamente avrò uno stipendio netto)
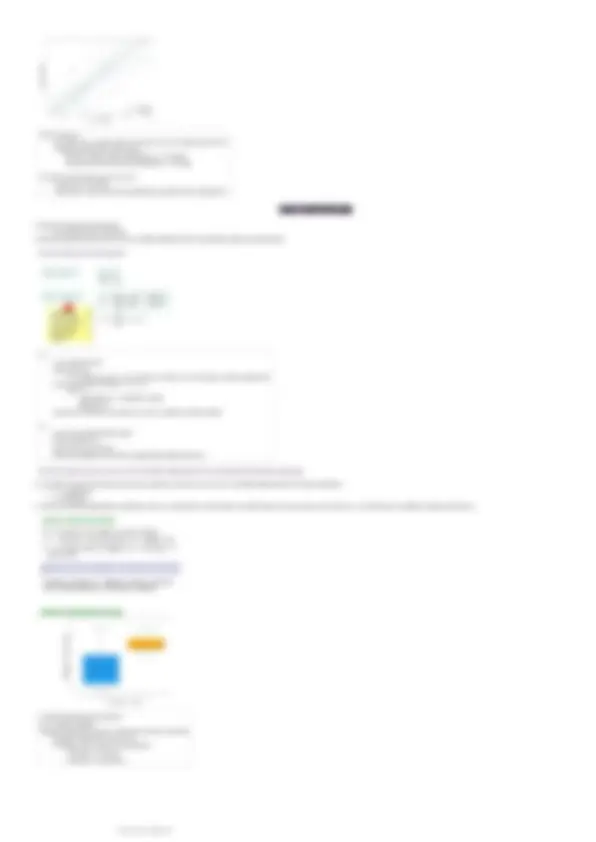
La statistica descrittiva univariata si occupa di tutti gli strumenti descrittivi per l’analisi di un solo carattere estrattodalla matrice dei dati (una colonna alla volta nella matrice dei dati). Nel seguito vedremo:
- distribuzioni o tabelle di frequenza
- grafici
- indici di posizione
- indici di variabilità/mutabilità
DISTRIBUZIONI DI FREQUENZA E GRAFICI
Distribuzioni di frequenza
Modo per organizzare in modo più sintetico i dati elementari di una tabella in prospetti sintetici delle osservazioni e per farlo è utile costruire una distribuzione o tabella utilizzando la nozione fondamentale di frequenza, la
quale è il numero di volte in cui osservo una modalità nella matrice dati.
Indicheremo con:
○ n = numero totale di unità statistiche (nr. righe della matrice di dati)
x 1
, x 2
... x k
○ = modalità distinte (crescente se esiste un ordine crescente) del carattere
ni = frequenza assolute (i = 1,2.... k)
▪ i = indice che va da 1 a k
▪ k = numero di modalità differenti del carattere
▪ n e k sono solitamente diversi tra loro, per questo è utile la tabella di frequenza
Tipi di frequenza
Frequenza assoluta : numero di unità statistiche che presentano una data modalità (ni)
- ni = numeri interi
- somma su tutte le diverse modalità distinte = n
Ni = somma frequenze assolute cumulate di modalità </> rispetto a i
○ 1° frequenza cumulata = frequenza non cumulata
ultima frequenza cumulata = somma di tutte le frequenze
Fi = somma fj con j < 1
○ la prima combacia sempre con la frequenza relativa
○ l'ultima sarà sempre uguale a 1
○ j ha lo stesso valore di i
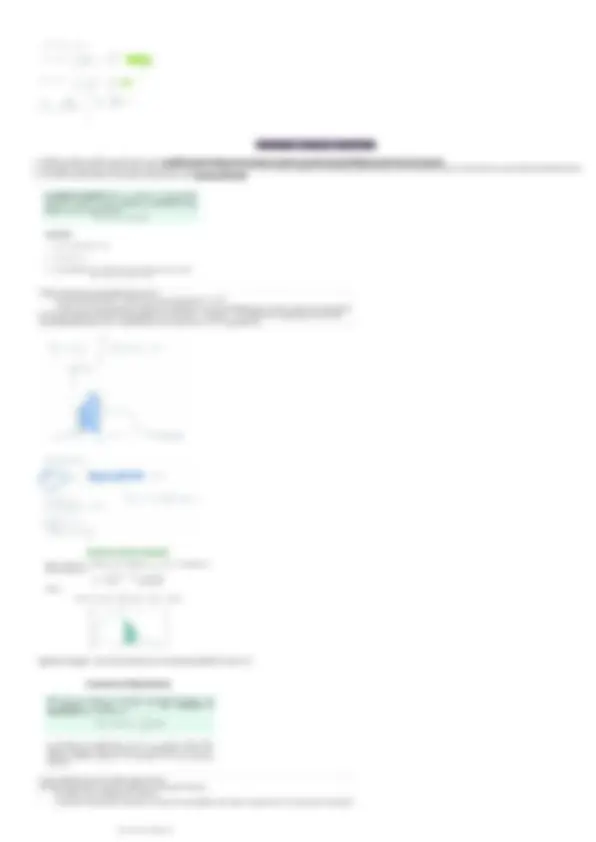
- Nr componenti famiglia (xi) = carattere ordinato e discreto
Per trovare ni, conto quante famiglie hanno ad esempio 1 componente
○ vedendo la tabella sopra delle famiglie, 2 famiglie sono formate da 1 sola componente e cosi via
- xi = 5 perchè vedendo la tabella, il numero massimo di componenti per famiglia è 5
Ni
○ la prima sempre uguale (ultima = al numero di unità statistiche)
○ seconda = somma delle prime 2 frequenze assolute
Nr. componenti famiglia = diverse modalità distinte del carattere (5)
- carattere ordinato e discreto
fi
Fi
- 1° = sempre uguale alla prima fi
- 0.067 + 0.133 = 0.2 (oppure 6/30)
- 0.2 + 0.233 = 0.433 (oppure 13/30)
- 0.433 + 0.467 = 0.9 (oppure 27/30)
- 0.9 + 0.1 = 1 (oppure 30/30)
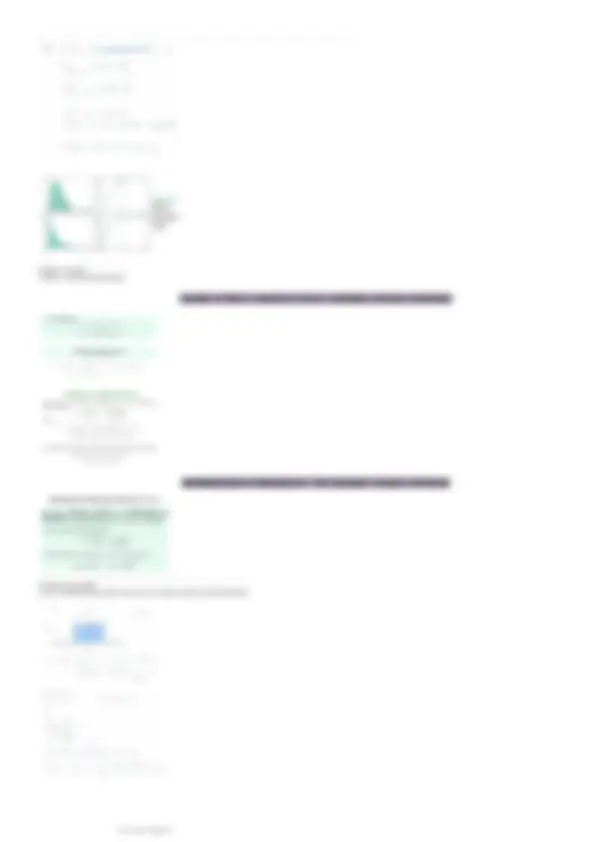
Suddivisione in classe di caratteri quantitativi
- Carattere quantitativo e discreto
- xi = età del primo lavoro (scrivo tutte le età in ordine e le reperisco dalla tabella sopra)
ni = conto (vedendo la tabella) ad esempio quante persone hanno iniziato a lavorare a lavorare a 15 anni (faccio lo stesso ragionamento per le
altre età)
Se il carattere quantitativo presenta molte modalità distinte, può essere conveniente accorpare le modalità in classi (quandoil carattere è quantitativo)
raggruppamento in classi (raggruppamento di diverse modalità di un carattere): costruzione di intervalli di valori chiusi o aperti
▪ da...escluso
▪ a....escluso
ho/h1 = valori che uso per definire la prima classe
|_________|_______|______|__________________|______
ho h1 h2 h3 hk
h o
= 1° classe
h 1
= 2° classe
h 2 - h 3 = 3° classe
h 3 - hk = 4° classe
Classi o intervalli:
○ devono essere disgiunte (senza sovrapposizioni)
○ devono essere esaustive (devono contenere il minimo ed il massimo osservati)
solitamente si intendono chiuse a destra
(hk- 1 , hk] = hk- 1 non è contenuto nella classe (parantesi tonda)
Classe 1 = contiene 15,16,17,18 (18 è incluso e escludo 14)
14 mai osservato nei dati
○14 mai osservato nei dati
○ 7+4+6 + 0 = 17 (vedi tabella sopra)
Classe 2 = contiene 19,20,21,22 (22 è incluso e escludo 18)
○ 18 lo avevo già incluso nella 1° classe, non ha senso contarlo 2 volte (non ci possono essere sovrapposizioni)
○ 1+5+3+0 = 9 (vedi tabella sopra)
Classe 3 = contiene 23,24,25,26 (26 è incluso e escludo 22)
○ 22 mai osservato nei dati
○ 0+1+1+2 = 4 (vedi tabella sopra)
- Sto facendo una sintesi dei miei dati e sto tralasciando delle informazioni quindi non avrei modo di ricostruire la tabella di partenza
Qui l'ampiezza è costante (non è detto che lo sia sempre), ovvero tutte hanno lo stesso numero di modalità distinte (4 classi di numeri)
- 5 classi con stessa ampiezza (10 anni)
a 1
= h 1
- a 2 = h 2 - h 1 (56 - 46 = 10)
e così via..
- Non ha senso calcolare la somma delle densità di frequenza, che mi servono quando ho ampiezze NON costanti
Densità di frequenza (di) : frequenza assoluta (o relativa) rapportata all'ampiezza dell'intervallo di = ni/ai oppure fi/ai con:
○ ai = ampiezza classe i-esima = hi - hi- 1
Ampiezza non costante (ai)
- classe 1 = 16 - 14 = 2
- classe 2 = 18 - 16 = 2
- classe 3 = 21 - 18 = 3
- classe 4 = 26 - 21 = 5
n i
- = le recupero dalla tabella
d i
= n i
/a i
- Classe più grande è la 1 (densità = 5,5)
5 classi con ampiezza non costante (ai)
○ classe 1 = 20 - 0 = 20
○ classe 2 = 30 - 20 = 10
○ classe 3 = 40 - 30 = 10
○ classe 4 = 80 - 40 = 40
○ classe 5 = 100 - 80 = 20
n i
- = le recupero dalla tabella
d i
= n i
/a i
- Classe con ni più grande = 4 (ampiezza = 40) ma la densità di frequenza più alta c'è l'ha la classe 3 (5,4)
L'insieme delle coppie modalità + frequenze X = (x i,
n i
); i = 1,2....k è detto:
○ mutabile statistica se il carattere è qualitativo
○ variabile statistica se il carattere è quantitativo (discreto o continuo)
Per i caratteri quantitativi continui e discreti, non ha senso fare la tabella di frequenza in cui vengono elencate le modalità distinte
○(0,1000), quindi nella tabella andrò a contare quanti valori nella colonna prodotto A sono compresi fra 1 e 1000
Prodotto B
x i
n i
a i
f i
(ni/n)
In questo caso, lo 0 era compreso nella tabella quindi lo includo ma escludendo 100
○ [0, 100), quindi nella tabella andrò a contare quanti valori nella colonna prodotto A sono compresi fra 0 e 99
Fatturato
Carattere continuo e quantitativo = ripartizione in classi
0 - 10 --> n i
○ = 1 (6.76 unico valore compreso fra 0 e 10. Faccio lo stesso ragionamento per le altre classi)
10 - 20 --> n i
○ 20 - 30 --> ni = 4
30 - 40 --> n i
40 - 50 --> n i
- ni totali = 20 (che deve sempre corrispondere al totale delle unità statistiche)
a i
○ classe 1 = 10 - 0 = 10
○ classe 2 = 20 - 10 = 10
○ classe 3 = 40 - 20 = 20
○ classe 5 = 55 - 40 = 15
Dalla lettura delle frequenze si possono trarre alcune osservazioni:
○ il 50% dei clienti dell’azienda sono grossisti (0.5), il 30% dettaglianti (0.3) ed il restante 20% della grande distribuzione (0.2)
○ per il 35% sono italiani (0.35), tra il 15% - 20% francesi, svizzeri e tedeschi
○ per la maggior parte hanno fatturato tra 10 e 20 (9)
○ per il prodotto C il numero di pezzi maggiormente acquistati è 5 (per i prodotti A e B????)
Tabella a doppia entrata
- Tabella di frequenza e si riferisce a 2 fenomeni che hanno in comune delle frequenze
Siamo ad esempio interessati al fatturato e al prodotto C
○ righe = caratteri (prodotto c = discreto)
colonne = fatturato (continuo)
▪ è indifferente cosa mettere nelle righe e nelle colonne
Fatturato (x i
x i
del prodotto C 0 - 10 10 - 20 20 - 30 30 - 40 40 - 50 (n i
del prodotto C)
(n i
fatturato) 1 2 + 3 + 4 = 9 0 + 2 + 2 = 4 1 + 2 + 0 = 3 0 + 2 + 1 = 3
Prodotto C
Cosa metto sotto 0 - 10, 10 - 20 ecc? Ad esempio sotto 0 - 10 metto in corrispondenza del 3, metto quanti fatturati compresi fra 0 - 10 sono stati generati acquistando 3 unità del prodotto C e tale dato lo posso trovare dalla
matrice dati iniziale
○ (lo stesso ragionamento lo applico per le altre casistiche)
- Ci sono diverse variabili singole
- Posso calcolare direttamente le tabelle di frequenza che abbiamo fatto singolarmente sulla colonna fatturato e prodotto C
- Le frequenze assolute sono le stesse
Devo sempre trovare lo stesso numero di unità statistiche
Rappresentazioni grafiche (grafici)
Rappresentazioni delle distribuzioni di frequenza univariate
caratteri qualitativi
▪ diagrammi a torta
▪ diagrammi a rettangoli separati
caratteri quantitativi discreti
▪ diagrammi a bastoncini (canne d’organo)
caratteri quantitativi continui
▪ istogrammi
Grafici su coordinate cartesiane in cui:
○ asse ascisse = modalità
asse ordinate = frequenze:
▪ assolute
▪ relative
▪ densità
▪densità
Caratteri qualitativi
Diagrammi torta (caratteri sconnessi)
- In corrispondenza ad ogni modalità si disegna un settore circolare il cui angolo al centro è proporzionale alla frequenza.
Frequenze assolute equivalgono alle percentuali (solo in questo caso, in quanto n = 100), in quanto la % = frequenza relativa* 100
Diagrammi a rettangoli separati (caratteri sconnessi e ordinati)
Ordinati
- In corrispondenza ad ogni modalità si disegna un rettangolo con altezza proporzionale alla frequenza
- Asse x = modalità
- Asse y = barrette proporzionali alle frequenze assolute o relative (è indifferente)
Non va confuso con l'istogramma, in quanto esso si usa per caratteri quantitativi
- Titolo studio = carattere qualitativo ordinato
- Grafico = rettangoli separati
Sconnessi (con numerose modalità distinte)
Una alternativa al diagramma a torta per i caratteri qualitativi sconnessi (soprattutto quando le modalità distinte sono numerose) può essere il diagramma a rettangoli separati (vedi grafico sotto) in cui le frequenze
stanno sull’asse delle ascisse
Caratteri quantitativi discreti
Diagrammi a bastoncini
In corrispondenza ad ogni modalità si disegna un segmento con altezza proporzionale alla frequenza
○ modalità = asse x
○ frequenze (assolute o relative) = asse y
Caratteri quantitativi continui (o discreti con modalità in classi)
Istogramma
- In corrispondenza ad ogni classe si disegna un rettangolo con base proporzionale all’ampiezza della classe e altezza proporzionale alla frequenza (o alla densità se le classi sono di diversa ampiezza)
Lo uso ogni volta che la tabella di frequenza è divisa in classi
○ caratteri quantitativi continui
○ caratteri quantitativi discreti
Carattere quantitativo discreto
- Carattere discreto = grafico a gradini (dove il gradino è alto quanto la frequenza cumulata in questo caso relativa)
Funzione di ripartizione = uguale al grafico di prima ma ho una linea spezzata che sale gradualmente (servono le frequenze cumulate per fare questa funzione)
INDICI DI POSIZIONE
- Valori sintetici che evidenziano le caratteristiche essenziali della distribuzione del carattere
- Riassumono i dati attraverso un numero
Attraverso gli indici di posizione è possibile confrontare variabili statistiche con valori che rappresentano i livelli/valori tipici di due diverse distribuzioni
○ esempio --> altezza media degli italiani
Definizione
Date n osservazioni (che possono essere di ogni tipo) v 1 ,v 2 ,…,vn o la variabile statistica X definita da {xi ,ni } (i=1,…,k), un indice di posizione è una funzione dei dati --> a(v 1 ,v 2 ,…,vn)= a(xi ,ni ) = a(X) e gode di importanti
proprietà
N osservazioni
Variabile statistica X
Proprietà generali
Internalità (condizione di Cauchy)
○ l’indice di posizione deve essere compreso tra il minimo ed il massimo dei dati osservati (interno ai miei dati)
Monotonicità
se due variabili statistiche hanno modalità minori o uguali una dell’altra allora la stessa relazione vale per i rispettivi indici di posizione
▪ x < y --> anche l'indice di posizione di x sarà < rispetto all'indice di y
Moltiplicatività (cambiamento di unità di misura)
○ se le modalità di una variabile statistica sono moltiplicate per una costante, allora anche il valore dell’indice di posizione viene moltiplicato per la stessa costante
Osservazioni
- La proprietà 1) di Cauchy è irrinunciabile
- Se valgono tutte l’indice di posizione si dice in senso stretto
- Se non valgono 2) o 3) l’indice di posizione si dice in senso lato
Indici tipici
Indice non analitico --> funzione alfa = non analitica
la moda non è una funzione analitica dei dati e non si calcola prendendo i dati e applicando una funzione matematica
○la moda non è una funzione analitica dei dati e non si calcola prendendo i dati e applicando una funzione matematica
- Indice analitico --> c'è la formula per calcolare la media
Indici non analitici
Moda
- Modalità del carattere/valore di massima frequenza (assoluta o relativa)
A seconda della tipologia del carattere vi sono modi differenti per identificarla
caratteri qualitativi/ quantitativi discreti , la moda è la modalità/xj tale per cui la frequenza assoluta è uguale al massimo fra tutte le frequenze assolute (lo stesso vale se la frequenza è relativa
Mo(X) = {x j
: n j
= max n i
j = modalità con frequenza massima (moda)
La moda la posso anche calcolare per caratteri qualitativi sconnessi ○
- Una fra le modalità osservate del carattere
- Moda = idoneo
- 19 = frequenza più alta
Nei caratteri qualitativi soddisfare la proprietà di internalità non è come per i caratteri quantitativi: la moda è sempre una tra le modalità
osservate del carattere quindi soddisfa l'internalità in questo esempio perchè "idoneo" è la moda ed è una delle modalità che io ho osservato
- Non ha senso parlare di monoticità e moltiplicatività nei caratteri qualitativi, ma vale solo l'internalità
Per trovare la moda, devo andare a vedere la modalità corrispondente alla frequenza più alta, e non direttamente la frequenzapiù alta
La moda in questo caso è 7 ed è compresa fra 5 e 10, quindi soddisfa la proprietà di internalità
Caratteri quantitativi continui definiti da classi di medesima ampiezza --> classe modale
Mo(X) = {xc : n j
= max n i
○ (valore centrale classe di max frequenza)
Operativamente
- 1° passo: individuare la classe modale (con massima frequenza)
- 2° passo: moda= valore centrale della classe modale e ha la frequenza più alta
Classe modale = quella che va da 11 a 13 avendo la frequenza massima
Caratteri quantitativi continui definiti da classi di differente ampiezza
○ Mo(X) = {xc : nj/aj = max ni/ai}
○ (valore centrale classe di max densità di frequenza )
Operativamente
- 1° passo: individuare la classe modale (con massima densità)
- 2° passo: moda= valore centrale della classe modale
Classe modale = quella che va da 11.5 a 15.5 essendo quella con densità massima
Osservazione 1
- La moda è indice di posizione in senso lato cadendo la monotonicità (sempre interna ai miei dati)
Modalità di y (4,4) sono > delle modalità di x (3,4) = ho valori più alti di y rispetto a x, ma comunque entrambi hanno una moda diversa (la moda di y NON è > della moda di x, anzi in questo caso è <)
Osservazione 2
La moda può non essere unica (la distribuzione è plurimodale o senza moda)
- distribuzione plurimodale = avere più di una moda
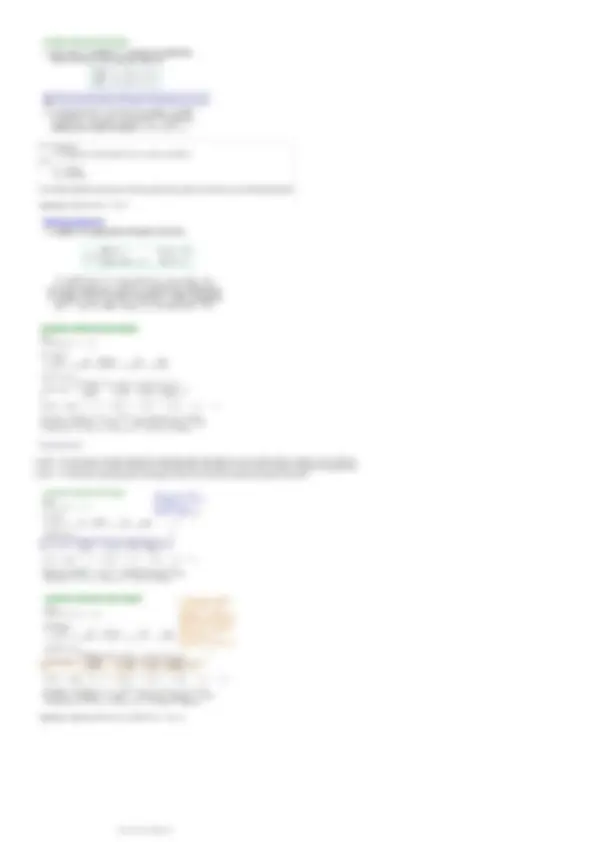
- Se il carattere è suddiviso in classi, tramite le frequenze cumulate relative si ottiene la classe mediana (m). Il valore approssimato della mediana si trova tramite la formula:
Formula che trova esattamente il punto mediano.
Dove L inf (m)
è il limite inferiore della classe mediana; a m
è l’ampiezza; F m
e F m - 1
sono le frequenze cumulate della classe mediana e della classe precedente a quella mediana. Si assume implicitamente l’ipotesi che nella classe
mediana le unità siano distribuite uniformemente. Si assume implicitamente l’ipotesi che nella classe mediana le unità siano distribuite uniformemente.
14.829 (mediana) è compreso nella classe 11.5 - | 15.
La mediana è sempre contenuta nella classe mediana (non può mai essere al suo esterno)
Osservazione
La mediana non è influenzata dai valori estremi della distribuzione. Si dice infatti che essa è robusta rispetto a variazioni dei valori minimo o massimo della distribuzione di frequenza. La mediana è la stessa anche se le due
distribuzioni sulle code si comportano molto diversamente.
- A volte è un indice di posizione migliore della media aritmetica ed è la scelta giusta se nei nostri dati, ci sono tanti valori anomali in quanto in presenza di valori anomali la mediana rimane la stessa
Se tengo i valori centrali uguali, la mediana non cambia perchè dipende dall'ordinamento e dalla posizione centrale dei dati
Indici analitici
Media aritmetica
- Data la variabile statistica ( carattere quantitativo e non per quelli qualitativi) X la media aritmetica è data dalla seguente formula:
Le 2 formule si equivalgono.
1° Modo
Un altro modo per trovare la media, era sommare tutte le modalità osservate ma esce comunque lo stesso risultato
○ esempio: 1 osservato 3 volte posso scrivere 3*1 anzichè 1+1+
2° modo
x i
n i
Media --> (181) + (211) + (251) + (261) + (271) + (281) / 6 = 24.
- Nel caso di una distribuzione di frequenze di un carattere quantitativo continuo o discreto suddiviso in classi , si utilizzano i valori centrali delle classi
1° modo
Calcolo punto centrale classe:
○ valore centrale classe 1 = 7.5 + 9,5/2 = 8,5 (lo stesso vale per le altre classi)
- Media = (8.5 * 40) + (10.5 * 25) + (13.5 * 120) + (18.5 * 145) / 330 = 14.
2° modo
Aggiungo x i
- per ogni classe, faccio la somma e divido per 330
Proprietà della media aritmetica (per cui vale l'internalità, la monoticità e la moltiplicatività)
Per la media aritmetica, che è l’indice di posizione più utilizzato, tante sono le proprietà. Nel seguito ne vedremo alcune tra le più importanti e utili:
Operatore media aritmetica
assegna ad ogni X la sua media aritmetica
simbolo sintetico, utile quando la media aritmetica compare in formule matematiche più complesse
Con le seguenti proprietà:
M(c) = M(costante) = c
▪ la media sarà sempre la costante
M(cX) = c M(X)
▪ la media di una costante * variabile statistica = costante * media
M(X±Y) = M(X) ± M(Y )
▪ la media della somma di 2 variabili statistiche è la somma delle medie (lo stesso vale se avessi avuto una differenza)
M(X) è un operatore lineare
▪ cioè se Y = aX + b --> M(Y) = aM(X) + b
1° proprietà
○ La media aritmetica rende nulla la somma (media) degli scarti di ogni valore da un indice di posizione
- xi - α --> scarti della media
(xi - α) * M = 0
○ ci saranno degli scarti della media che sono positivi, altri negativi ma comunque la loro somma sarà = a 0 e la media sarà sempre in mezzo ai dati
Esempio
Scarti dalla media = lunghezze dei segmenti
○ x 1 - μ
○ x 2 - μ
x 3
○ - μ
○ x 4 - μ
○ x 5 - μ
Da x 1
- μ a x 3 - μ, avremo scarti negativi, invece da x 3
- in poi avremo scarti positivi e la loro somma, darà 0
2° proprietà (o proprietà di minimo)
La media aritmetica minimizza la somma (media) dei quadrati degli scarti di ogni valore da un indice di posizione: se trovo la somma degli scarti al quadrato e trovo α
che lo rende minimo, tale α
è uguale alla media
aritmetica
- A prescindere dal carattere, tutti gli indici di variabilità devono soddisfare le seguenti proprietà generali:
Non negatività : v(X)≥0 è sempre maggiore o uguale a 0. In particolare è nullo (v(X)=0) se e solo se tutte le modalità della distribuzione sono uguali. E’ il caso della distribuzione degenere: tutte le unità statistiche
presentano la stessa modalità del carattere.
Tutti gli indici di variabilità devono essere positivi
Monotonicità (da non confondere con quella delle medie) : assume valori tanto più grandi quanto maggiore è la diversità tra le modalità della distribuzione.
modalità più vicine/simili = indice di variabilità sarà piccolo
modalità tanto diverse = indice di variabilità sarà grande
Invarianza per traslazione (caratteri numerici) : v(X+b) = v(X) non cambia se a ciascun termine della distribuzione si aggiunge una quantità costante, negativa o positiva.
se prendo un carattere numerico con tutte le sue modalità e aggiungo una costante, la variabilità non deve cambiare (e questo non va confuso con quanto detto per la media): la variabilità di x + una costante sarà
uguale alla variabilità di x
Mutabilità e indice di Gini
- Indice che serve per misurare la mutabilità o eterogeneità di un carattere (serve per caratteri qualitativi )
- Lo studio della mutabilità si basa sulla definizione di indici che, data la natura dei caratteri che non presentano modalità numeriche, vengono calcolati sui valori delle frequenze relative
Nel gruppo 2 le percentuali sono le stesse, ma non è la variabilità delle frequenze che stiamo studiando ma la variabilità del carattere: avere le frequenze tutte uguali, vuol dire che 1/3 ha i capelli neri, 1/3 ha i capelli
castani e 1/3 ha i capelli biondi e il carattere "colore di capelli" è equamente diviso fra le persone e quindi il gruppo 2 è l'esempio in cui mi aspetto una più grande variabilità.
Nel gruppo 3 cambiano tanto le frequenze fra di loro ma devo sempre guardare la variabilità del carattere/modalità:
○ 70% = capelli neri (avremo tante famiglie con capelli neri e un pò con capelli castani e biondi)
Se ipoteticamente avessi un G4 con:
○ nero = 1
○ castano = 0
○ biondo = 0
altro = 0
avrei che il 100% ha i capelli neri, quindi non avrei una variabilità e mi troverei in una situazione di minima variabilità ( frequenze molto diverse)
Indice di eterogeneità di Gini
- Tra i tanti indici di mutabilità presenti in letteratura, uno dei più utilizzati è l’indice di eterogeneità di Gini, così definito (usato per lo studio della concentrazione industriale o di mercato):
Somma su tutte le diverse modalità del carattere delle frequenze relative (f i
) * 1 - f i
○ questo si può anche calcolare facendo 1 - la somma delle frequenze relative al quadrato
- Il gruppo G2 ha l'indice di Gini più alto, in quanto in questo gruppo il carattere "colore capelli" è più eterogeneo.
- Il gruppo G3 ha l'indice di Gini che varia di meno, in quanto in questo gruppo il carattere "colore capelli" è meno eterogeneo.
Quindi
- Se ho le stesse modalità di un carattere, posso calcolare l'indice di Gini nelle varie casistiche e per capire che cosa è piùo meno eterogeneo confrontare i vari indici (e questo lo posso fare sempre)
- Qui ho solo le frequenze assolute, e vanno calcolate le frequenze relative per trovare l'indice di Gini
Nel primo caso osservo solo 2 modalità (genere) invece nel secondo 5 (colore di capelli)
il secondo caso ha l'indice di Gini più alto ma non possiamo dire che il carattere è più mutabile in quanto la mutabilità più alta può essere data solo dal fatto che il nr. di tipi è più alto perchè magari sto osservando il
colore dei capelli anzichè il genere, quindi ho tanti tipi diversi
E' scorretto dire quale dei due caratteri è più mutabile perchè la differenza fra questi 2 indici può essere anche data dal fatto che come in questo caso ho 2 modalità da una parte e 5 dall'altra. Per arrivare a una riposta,
dobbiamo calcolare gli indici normalizzati (in quanto il nr. di modalità è diverso).
Per rendere confrontabili tra di loro alcuni aspetti come la mutabilità (o variabilità) di caratteri diversi (pensate, ad esempio, al carattere colore degli occhi e colore dei capelli) è necessario avere a disposizione indici
particolari, che prendono il nome di indici normalizzati, che consentono di fare confronti tra caratteri diversi o stessi caratteri ma misurati con unità di misura diverse (variabilità di un titolo azionario in euro e uno in
dollaro) e tengono conto di qual'è il valore massimo e minimo della cosa che sto calcolando.
○ I = indice da normalizzare
○ Imin e Imax = valori di I nelle situazioni estreme
L'indice normalizzato sarà sempre compreso fra 0 e 1
○ nella situazione di minima mutabilità, l'indice di Gini normalizzato è 0
○nella situazione di minima mutabilità, l'indice di Gini normalizzato è 0
○ nella situazione di massima mutabilità, l'indice di Gini normalizzato è 1
La situazione di massima mutabilità è una situazione in cui osservo le modalità con la stessa frequenza (G2) e il valore dell'indice in questa situazione è 1 - 1/k e dipende da k (modalità diverse).
• E = 0.
EN = 0,565/0,75 = 0,
mutabilità abbastanza alta nel G1 vedendo E N
- G3 = mutabilità bassa/medio-alta/intermedia in quanto supera il 50% di poco
G2 = mutabilità molto alta vedendo E N
Potrebbe sembrare che il secondo caso abbia una mutabilità più alta visto il nr > di variabilità, ma non è cosi in quanto E N
nel 1° caso è > rispetto al 2° caso
E
N
1° caso
▪ 0,499/1 - 1/2 = 0,499/0,5 = 0.998 (mutabilità/eterogeneità molto alta)
EN 2° caso
▪ 0.685/1-1/5 = 0.685/0,8 = 0.856 (mutabilità/eterogeneità alta ma bassa rispetto al primo caso)
Varianza e sue proprietà
- La definizione di variabilità nel caso di caratteri quantitativi può essere applicata alle modalità in modo analitico.
Una misura molto grezza di variabilità di un fenomeno è data dal range, cioè dalla differenza ( xmax - xmin ) tra il valore massimo e il valore minimo osservati.
○ range = massima osservazione - minima osservazione
○ grezza = facile da calcolare e risente dei valori estremi (in quanto uguale al massimo - minimo)
Un’altra misura di variabilità che vedremo al termine di questo capitolo, quando faremo i box-plot, è invece la differenza interquartile (Q 3
- Q
1
), cioè la differenza tra il terzo e il primo quartile.
terzo quartile - primo quartile = percentile 75% (0.75) - Q
▪ dal mio dataset tolgo il 25% dei valori più bassi e il 25% dei valori più alti
○ meno influenzato dai valori estremi
○ non è un indice analitico (non ho una formula)
○ meno proprietà teoriche
E’ possibile però ottenere anche indici più elaborati. Ad esempio è possibile calcolare tutte le “differenze” o “distanze” tra le varie modalità del carattere, e su di esse basarsi per definire un indice che ne dia una misura
sintetica. Esistono due impostazioni basate sul differente modo del calcolo di tali distanze:
distanze di ogni modalità da tutte le altre
esponenziale nel numero di dati ed è un calcolo oneroso
distanze di ogni modalità da una particolare, scelta ad hoc (es la media aritmetica): modalità osservata oppure che non ho osservato
▪ più semplice rispetto alla distanza precedente
- La varianza è definita dalla seguente formula:
- Scelgo una modalità particolare di riferimento: indice di posizione --> media
Metto (x - μx)
2
- in modo da avere tutto positivo (proprietà internalità media aritmetica)
- μx = media di x (che deve essere lo stesso carattere di cui sto calcolando la varianza)
Attenzione!!
- Nella formula μ rappresenta la media della variabile di cui sto calcolando la varianza. Dunque: se sto calcolando Var(Y) --> μ = M(Y), se invece sto calcolando Var(X), allora μ = M(X).
Proprietà della varianza
- Come per la media aritmetica, che è l’indice di posizione più utilizzato, anche per la varianza tante sono le proprietà.
Nel seguito ne vedremo alcune delle più importanti:
○ operatore varianza
○ teorema di scomposizione della varianza
- Varianza totale = varianza nei gruppi + varianza entro i gruppi
Operatore della varianza
- Associa ad ogni variabile la sua varianza con le seguenti proprietà:
- a = costante
- 2° e 3° = simili a linearità media aritmetica
- 3° = cancello b in quanto la variabilità di una variabile + costante deve essere uguale alla variabilità della variabile stessa
Var (X - Y) --> d
Var (X + (-1 * Y))
Var (X) + Var (-1 * Y) + C
Var (X) + (-1)
2
Var (Y) + C
→ Var (X) + Var (Y)
Teorema della scomposizione della varianza
- I dati elementari sono classificati in h sottogruppi.
- Per ciascuno dei sottogruppi si conosce la numerosità (nj e serve anche per calcolare la media) , la media e la varianza
Il teorema di scomposizione della varianza afferma che:
La varianza totale (varianza di tutte le unità statistiche messe insieme) Ϭ
2 è ottenibile come la somma della
varianza “entro/dentro i gruppi” (varianza within = Ϭ
2
▪ W )
varianza “tra i gruppi” (varianza between = Ϭ
2
B
Entrambe le varianze sono positive
Definizione della varianza between e within
Varianza within: quanto variano le unità statistiche all'interno dei gruppi / media delle varianze nei gruppi
2
j
○ = modalità/varianze all'interno dei gruppi
n j
○ = frequenze assolute. ovvero il nr. di unità all'interno di ogni gruppo
→ Esempio : ho 50 unità statistiche in un gruppo e 50 nell'altro, con una varianza pari a 10 nel 1° gruppo e 11 nel 2° quindi quale sar à la varianza all'interno dei gruppi? la media delle 2 varianze --> 10 + 11 / 2 = 10.
Varianza between: varianza delle medie dei gruppi
○ μ1,2 ecc = media di ogni gruppo (nuova variabile)
μ j
○ = nuova modalità
I gruppi sono in questo caso identificati da una variabile quantitativa continua (età)
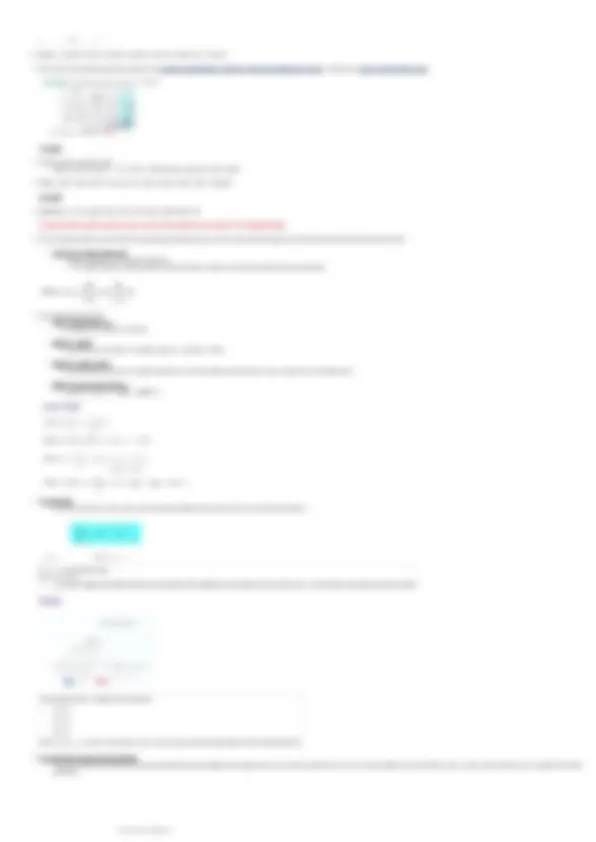
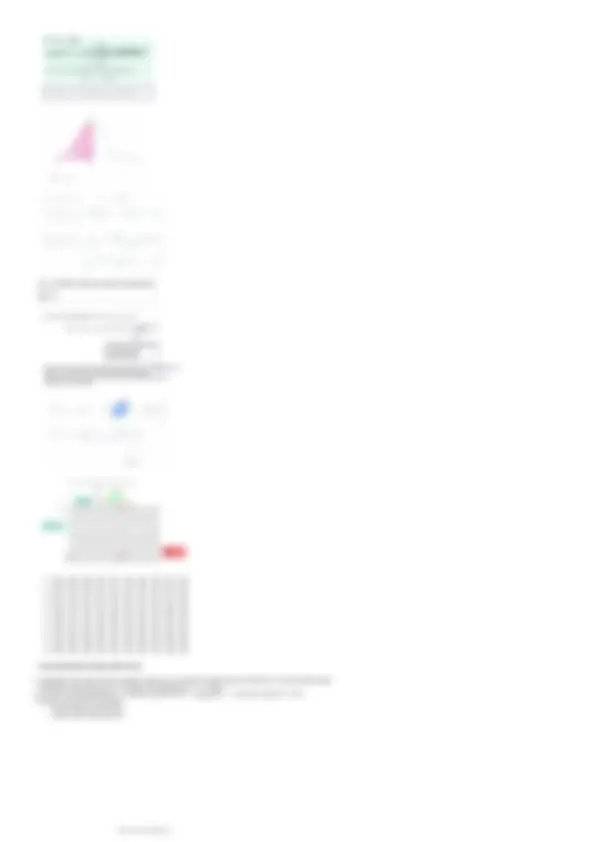
Grafici box plot (o box & whiskers)
- Grafico riassuntivo dei maggiori indici descrittivi univariati che consente confronti visivi tra diverse variabili
Per ogni variabile vengono rappresentate:
○ mediana (Q 2 = secondo quartile della distribuzione)
○ I e III quartile (Q 1 e Q 3 )
Differenza interquartile (indice di variabilità) H = Q 3
– Q
1
○ Range --> minimo e massimo dato del mio dataset
Il grafico box plot è formato da:
box (scatola rossa)
delimitato da Q 1
e Q 2
la linea nera al suo interno indica la mediana Q 2
tra Q 3
e Q 1
si trova il 50% delle unità statistiche/dati
butto via ciò che sta sotto a Q 1
→ (25% dei miei dati)
→ butto via ciò che sta sopra Q 3 (25% dei miei dati)
altezza --> H = Q 3 - Q 1 (mediana) in cui si trova il 50% delle unità statistiche.
□ Q 3 - Q 1 = differenza interquartile
whiskers (baffi)
il più basso rappresenta il minimo
→ Q 1 - 1.5 (Q 3 - Q 1 )
il più alto rappresenta il massimo
→ Q 1 + 1.5 (Q 3 - Q 1 )