



1
Stima puntuale e stima
intervallare


























Studia grazie alle numerose risorse presenti su Docsity

Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium

Prepara i tuoi esami
Studia grazie alle numerose risorse presenti su Docsity
Prepara i tuoi esami con i documenti condivisi da studenti come te su Docsity
Trova i documenti specifici per gli esami della tua università
Preparati con lezioni e prove svolte basate sui programmi universitari!
Rispondi a reali domande d’esame e scopri la tua preparazione
Riassumi i tuoi documenti, fagli domande, convertili in quiz e mappe concettuali
Studia con prove svolte, tesine e consigli utili
Togliti ogni dubbio leggendo le risposte alle domande fatte da altri studenti come te
Esplora i documenti più scaricati per gli argomenti di studio più popolari
Ottieni i punti per scaricare
Guadagna punti aiutando altri studenti oppure acquistali con un piano Premium
Panoramica sull'inferenza statistica, focalizzata su stima puntuale e intervallare. Introduce l'inferenza e i parametri di studio come media, proporzione e varianza. Spiega le due tecniche principali: la stima puntuale, che assegna un singolo valore a un parametro, e la stima intervallare, che produce un intervallo di valori plausibili. Esempi pratici illustrano i concetti, come la stima delle ore in bici dei residenti e l'importo medio degli ordini online. Include formule e tabelle per la stima intervallare di media e proporzione, distinguendo tra popolazioni normali e non, con varianza nota e non. Infine, discute margini di errore e livelli di confidenza, offrendo una guida per l'applicazione pratica.
Tipologia: Appunti
1 / 34

Questa pagina non è visibile nell’anteprima
Non perderti parti importanti!
1
2
L’inferenza statistica è il processo secondo il quale vengono usati i
risultati ottenuti da campioni per stimare o trarre conclusioni circa i
parametri di una popolazione.
I parametri oggetto di studio sono:
Media – Proporzione - Varianza
4
verifica delle ipotesi
i dati campionari vengono utilizzati per
rifiutare o accettare una particolare ipotesi
circa un parametro incognito relativo alla
popolazione
Da un’indagine campionaria sul grado di soddisfazione dei servizi
bibliotecari, è emerso un livello pari a 8.5 (oppure una percentuale di
soddisfatti pari all’85%).
Se il direttore della biblioteca aveva stabilito un livello target di
soddisfazione pari a 8 (oppure avere una percentuale di soddisfatti pari
all’80%), può ritenersi contento?
5
7
8
Un’azienda deve tenere sotto controllo la qualità del processo di
produzione di un macchinario che produce pezzi di una certa
lunghezza. Se si tenessero sotto controllo tutti i pezzi prodotti e se ne
calcolasse la lunghezza si potrebbe ottenere senza difficoltà la
lunghezza media (parametro).
Se non si possono misurare le lunghezze di tutti i pezzi prodotti, ma
solo quelle relative ad un campione casuale di pezzi di numerosità n,
allora si può calcolare solo la lunghezza media del campione di pezzi
(statistica o stimatore).
In tal caso la lunghezza media della popolazione di pezzi è ignota.
Come la posso stimare? Con la media del campione.
10
In questo esempio, la distribuzione
campionaria dello stimatore è concentrata
intorno al suo valore atteso, che in questo
esempio coincide con il valore del
parametro della popolazione. Pertanto, ci
si attende che la stima ottenuta attraverso
l’estrazione di un campione casuale sia una
valore vicino al parametro.
11
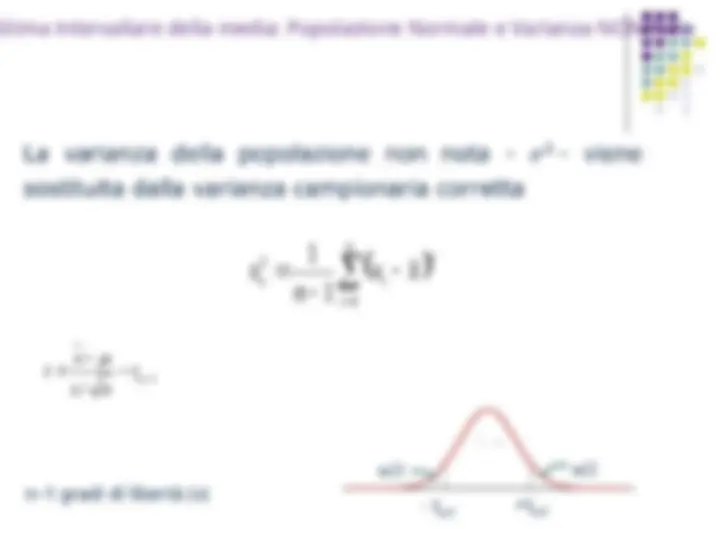
Dalla stima puntuale alla stima intervallare
Il principale svantaggio della stima puntuale è legato alla casualità delle
osservazioni campionarie.
Infatti, per effetto del caso, la stima puntuale sulla base di un campione
può essere molto diversa dal valore vero del parametro.
Allora, si preferisce stimare un intervallo di valori entro i quali si ritiene
sia compreso il parametro incognito.
Una stima intervallare:
riflette meglio l’incertezza legata all’inferenza
incorpora direttamente l’informazione sul grado di precisione
Per costruire una stima intervallare del parametro , si stimano, sulla
base dei dati campionari, gli estremi dell’intervallo (L
1
e L
2
), dopo aver
scelto un livello di probabilità, ossia:
1
2
Ciò significa che, con un livello di probabilità (di fiducia, di confidenza)
pari a (1-), il parametro che si intende studiare (media, varianza o
proporzione) è compreso tra L
1
e L
2
Quindi, (1-) è la misura della attendibilità della stima e prende il nome
di livello di confidenza.
θ
Non possiamo sapere se il campione che abbiamo effettivamente
estratto è uno di quelli per i quali gli intervalli stimati contengono μ
oppure no.
Per programmare meglio il servizio offerto, un’azienda leader nella
vendita on line di libri, Cd e DVD vuole conoscere:
Estrae un campione casuale di n transazioni delle quali osserva
l’importo e il metodo di pagamento.
Ad esempio, l’intervallo stimato al livello del 95% comprende valori da
54,04 a 60,44.
54,
60,
Invece, la proporzione campionaria dei pagamenti fatti con la VISA è pari
a 0.52 (stima puntuale).
Questa proporzione varia da campione a campione a seconda delle unità
selezionate. Per effetto del caso, posso essere stato “fortunato” e avere
estratto un campione che fornisce una proporzione molto vicina a quella
incognita della popolazione. Ma posso anche essere stato
particolarmente “sfortunato” e avere estratto un campione di
osservazioni che produce una proporzione molto distante da quella
incognita della popolazione.