Scarica TEST STATISTICI IN ECOLOGIA e più Appunti in PDF di Ecologia solo su Docsity!
13.TEST STATISTICI SU CAMPIONI ESTRATTI DA POPOLAZIONI:
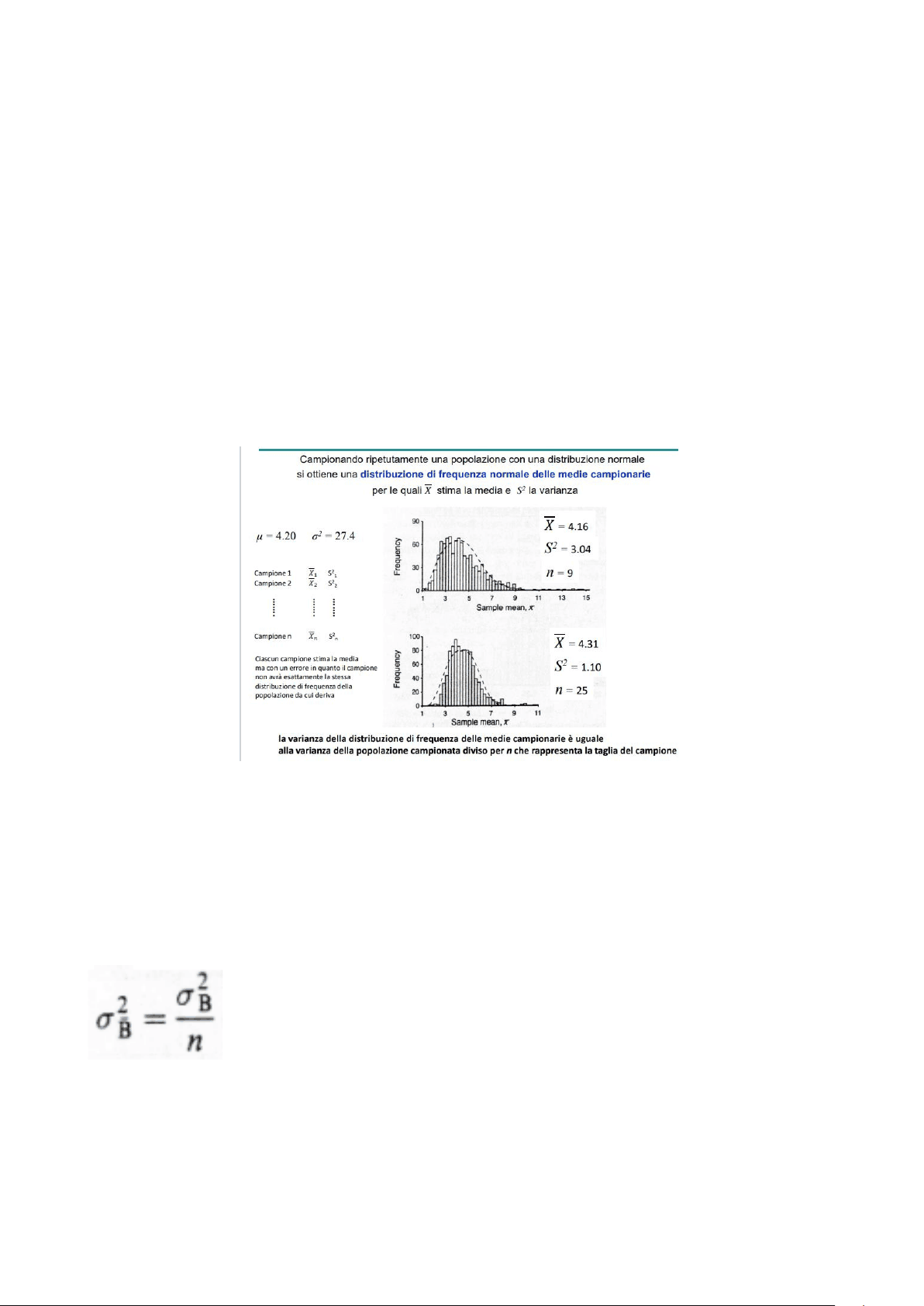
Stiamo studiando una popolazione con distribuzione normale e preleviamo delle osservazioni (=campioni). Distribuzione di frequenza normale delle medie campionarie: μ=4, σ^2 =27, ex: lunghezza media dei rospi=variabile x se campioniamo la popolazione un migliaio di volte: il campione 1 darà x medio1 e S^2 il campione 2 darà x medio2 etc fino a campione n= →non otterremo mai la stessa media e la stessa varianza Facendolo per 1000 volte, ciascun campione stima μ, ma con un errore perché ogni campione non avrà la stessa varianza della popolazone da cui deriva. Posso costruire la distribuzione di frequenza delle medie campionarie: La distribuzione di frequenza di X̅ dovrebbe essere centrata sulla stessa media della variabile x (=μ). X̅ in un caso è 4.16 e nell’altro è 4.31. Tra i 2 grafici il parametro che cambia è n (=numero osservazioni): 9 e 25 In quello superiore la distribuzione di frequenza è centrata su 4,16 (=media) mentre sotto è 4,31. Se aumento n diminuisce la variabilità tra i campioni (AUMENTANDO n AUMENTO L’ACCURATEZZA) →curva si stringe verso il valore reale (aumento l’accuratezza aumentando n). L’altro aspetto da considerare è la varianza: con n=9 la varianza stimata S^2 è 3,04, mentre è 1,10 con n=25. Questo perché la varianza è uguale alla distribuzione di frequenza delle medie campionarie diviso n. →la distribuzione di frequenza delle medie campionarie ha valore medio corrispondente a quello relativo la variabile x e varianza uguale alla varianza della popolazione campionata diviso n, dove n=taglia campione. n=numero di osservazioni/taglia del campione
TEROEMA DEL LIMITE CENTRALE:
partendo da una distribuzione NON normale (=no curva a campana) si ottiene una distribuzione della frequenza delle medie campionarie che è normale con n abbastanza grande. →man a mano che aumenta n sono approssimate comunque da distribuzioni normali TEOREMA: La distribuzione della MEDIA CAMPIONARIA è approssimata dalla distribuzione normale con media μ e varianza σ^2 /n anche se i campioni provengono da altri tipi di frequenze di distribuzione, quando l’ampiezza del campione diventa sufficientemente grande In alcuni casi il teorema del limite centrale NON è valido: 1)se abbiamo distribuzioni amodali=più mode. Ad ex caso dove si studia la taglia di individui in popolazioni con differenze molto marcate per classi d’età. In questo caso anche se ripetessimo il campionamento per 1000 volte non si otterrebbe una distribuzione di frequenza normale →in questo caso dobbiamo suddividere le taglie per classi. 2)anche per distribuzioni di frequenza asimmetriche non funzionano (processo di mortalità) →si risolve trasformando i dati su base logaritmica ottenendo una distribuzione normale → PARTENDO DA UNA DISTRIBUZIONE DI FREQUENZA DI X NORMALE ANCHE LA DISTRIBUZIONE DI MEDIE CAMPIONARIE SARA’ NORMALE Quando campioniamo una determinata popolazione non sappiamo se è normale o no, ma se prendiamo campioni da una distribuzione uniforme troviamo un totale delle medie e quindi troviamo un valore che è comunque vicino a quello medio della variabile che stiamo studiando.
LA DEVIAZIONE STANDARD È LA RADICE QUADRATA DELLA VARIANZA:
→la deviazione standard della distribuzione di frequenza della media campionaria è chiamata ERRORE STANDARD →l’errore standard è la deviazione standard della distribuzione di frequenza delle medie campionarie ed indica quanto sarebbero variabili le medie campionarie se prendessimo un certo numero di campioni dalla popolazione INTERVALLO DI CONFIDENZA PER MEDIA CAMPIONARIA: Ex: lunghezza becco μB=11 mm σ^2 =2, →distribuzione normale centrata su μB= →con formula inversa di distribuzione Zeta possiamo stabilire i valori inferiori e superiori che includono il 95% dell’intera distribuzione. Per ogni distribuzione normale di x posso calcolare x sup e x inf In questo esempio B corrisponde a X. →possiamo calcolare gli estremi: se ho intervallo molto piccolo, conosco anche l’accuratezza, mentre se ottengo un intervallo enorme e trovo valore medio non so comunque come questo si collochi rispetto al parametro che sto per stimare Ogni volta che stimiamo un valore di B medio c’è una probabilità del 95% che B medio si trovi in quell’intervallo e del 5% che ne sia fuori →si trova all’interno di questo intervallo di confidenza con probabilità del 95%. B medio sta nell’intervallo definito da ultima formula per il 95% di tutti i possibili valori di B. (PARTIAMO DA IDEA CHE EVENTO SIA PROBABILE OGNI VOLTA CHE ACCADE 1 VOLTA SU 20→per questo consideriamo 95%) Con un solo campione prendo 20 triglie e le misuro, trovo valore medio e solo con questo campione posso stabilire un intervallo all’interno del quale ho il 95% di probabilità che si trovi la media parametrica. INTERVALLO DI CONFIDENZA=INTERVALLO ALL’INTERNO DEL QUALE HO LA PROBABILITÀ DEL 95% DI TROVARE MEDIA PARAMETRICA. È UNA MISURA DELL’ACCURATEZZA Se intervallo di confidenza è piccolo→ misura accurata Se abbiamo errore standard grande arriveremo a medie diverse.
Ex. Articolo scientifico, reclutamento coralli. Ricci hanno effetto su coralli perchè essendo erbivori eliminano i competitori dei coralli Grafico 1=numero diadema per metro quadrato=densità ricci stimata. Il segnetto sopra indica errore standard perché quello valore medio generato att numero ridotto di osservazioni
→ si riporta una misura della media ma anche della precisione
ERRORE STANDARD DICE GRADO DI CONCORDANZA TRA LE MISURE DI UN CAMPIONE
Se abbiamo errore standard molto grande→minore accuratezza (intervallo di confidenza maggiore) Il principale valore dell’intervallo di confidenza è la misura dell’accuratezza (distanza tra valore medio stimato ed il valore reale) e si usa anche per testare HP0: INTERVALLO DI ACCURATEZZA E TEST HP0: ex: OSSERVAZIONE=esistono lucertole più grandi di quelle che si trovano sulla Terra MODELLO=le lucertole sono più grandi perchè provengono da Marte HP: la taglia medie delle lucertole provenienti da Marte è maggiore di quella che possiamo attenderci da un campione di lucertole terrestri. HP0: la taglia medie delle lucertole di Marte è minore o uguale a quelle delle lucertole terrestri So che lucertole terrestri sono descritte da: media μ=300 mm σ^2 = lucertole Marte: n= X medio= →posso trovare intervallo di confidenza per quanto riguarda la distribuzione di medie campionarie delle lucertole terrestri: →trovo INTERVALLO 252- 348 →il 95% DELLA TAGLIA MEDIA delle lucertole terrestri prese (=5) si trova tra 252 e 348 mm Se trovo lucertole di terra lunghe 360 mm, dato che la probabilità di misurare 360 sarebbe inferiore a 5% →HP0 rifiutata: le lucertole di 360 mm hanno una bassa probabilità di essere terrestri LA DISTRIBUZIONE t di STUDENT (Gosset 1908): PROBLEMA=L’applicazione della teoria precedente sugli intervalli di confidenza è limitata dal fatto che presuppone la conoscenza della varianza σ^2 , MA generalmente non conosciamo questo parametro →la distribuzione z funziona solo se conosciamo σ^2 Gosset nel 1908 ha risolto il problema: si usa un’altra distribuzione di frequenza che si possa usare al posto dei valori della distribuzione normale standard quando varianza non è nota ma solo stimata (=S^2 ) Se aumentiamo n, S^2 stimerà in maniera più precisa σ^2
I GDL con la distribuzione t devono essere presi in considerazione perché i valori critici cambiano in base a GDL (=numero di osservazioni utilizzate). Cambiando il numero di osservazioni cambia la curva che rappresenta la distribuzione t: aumentando i GDL la curva si restringe e si alza, mentre diminuendoli la curva si appiattisce e si allarga →dobbiamo far riferimento alla curva del nostro studio in base al numero di osservazioni (=elementi) e quindi al GDL Quando numero di osservazioni tende all’infinito è come se avessimo tutte le possibili osservazioni e quindi non c’è piu differenza tra S^2 e σ^2 →i valori critici che separano le 2 code tenderanno ad essere sempre più vicini a 1,96. Ex lucertole: non si possono contare tutte, si prende campione con n=15 che ci permette di stimare una media e una varianza. Per un campione n=15 ho distribuzione di frequenza delle medie campionarie →posso costruire un intervallo di confidenza, molto importante perche ci dà una misura di accuratezza →con un solo campione di 15 individui stabilisco un intervallo dove ho probabilità pari al 95% di trovarci μ (=media parametrica o media reale) →con un numero ridotto di campioni capisco dove sta la media.
Da tavola si ottiene +-2,14, che nel loro insieme separano le 2 code che contengono il 5%, mentre il 95% sta nel mezzo. →La media parametrica si trova tra 15,39 e 21,4 (=estremi dell’intervallo di confidenza) Dato che x medio è 18,4 mm→la media parametrica torna (stima accurata) INTERVALLO DI CONFIDENZA=INTERVALLO ALL’INTERNO DEL QUALE SI HA LA PROBABILITA’ DEL 95% DI TROVARE MEDIA PARAMETRICA (NON CAMPIONARIA!!) GLI ESTREMI DELL’INTERVALLO DI CONFIDENZA SONO DATI DALLA MEDIA CAMPIONARIA +- IL t CRITICO PER L’ERRORE STANDARD COME AUMENTARE ACCURATEZZA e PRECISIONE:
- PROBABILITÀ USATA PER COSTRUIRE INTERVALLO DI CONFIDENZA. Quando passiamo da 0,05 a 0,01, l’intervallo di confidenza diventa più ampio→sono più sicuro che dentro ci stia media parametrica ma meno accurato (meno informativo) →USIAMO UN INTERVALLO DI CONFIDENZA PIÙ PICCOLO PER AUMENTARE L’ACCURATEZZA →generalmente utilizziamo valore 0,05 per t 2)TAGLIA DEL CAMPIONE (n): aumentare le osservazioni→aumento GDL aumentando n diminuisce il rapporto→incremento accuratezza Errore standard
Errore standard= variabilità che ci aspettiamo se ripetiamo il campionamento con stesso n con le stime delle medie La statistica t oltre a dare l’intervallo di confidenza ci può permettere di accettare o rifiutare un HP0: ex: →calcolo t=-2, Per decidere se accettare o rifiutare HP0: che probabilità ho di osservare un valore t=-2,57 se HP0 è vera? →dalle tavole le tavole permettono di trovare un valore che indica la probabilità: un evento è probabile se c’è probabilità di osservarlo maggiore al 5% →un evento è improbabile se si osserva con probabilità minore di 5% →se HP0 vera→la probabilità di osservare - 2,57 deve essere maggiore del 5% →da tavola ricavo estremi critici, uso 0,025 come riferimento perché considero una tabella con distribuzione a 2 code →valori critici: +2,306 e - 2,306 scelti in base ai GDL perché avevamo n=9 osservazioni→GDL=9-1=8. →se osservo - 2,57 nelle regioni rosse sia nella coda superiore che nella coda inferiore →devo rifiutare HP0, se invece avessi osservato ad esempio - 1,8 avrei accettato HP 0 ESEMPIO: Uova nel nido HP 0 : μ è uguale a 15 grammi (=peso medio osservato fuori dall’Europa) t ci permette di trovare intervalli critici superiori ed inferiori oppure una sola coda. densità media di insetti in aree di controllo ha μ= HP=nelle aree trattate con insetticida diminuerà la densità di insetti HP0= aree trattate con insetticida daranno densità maggiore o uguale rispetto a aree non trattate n=9 (quadrati di terreno) conosco X medio (=insetti per campione) S=deviazione standard
Se t osservato in regione del 5% →HP0 rifiutata ERRORE DI TIPO I E DI TIPO II: L’Errore di tipo II si indica con β (=probabilità di commettere errore di tipo II) Se decido di rifiutare HP0 ma è vera → errore di tipo I (probabilità 5%) (α) Se decido di accettare HP0 ma è falsa → errore di tipo II (β) L’errore di tipo II: ex:
→osservare un valore tra - 2,09 e 2,09 ha valore 95% se l’HP 0 è vera, se osserviamo quindi 1,5 accettiamo HP0, ciò va bene se generato da primo grafico. Ma può essere generato anche quando HP0 è falsa (valore generato da ipotesi alternativa)→β Il problema principale è che le due distribuzioni si sovrappongono →non sappiamo se errore è stato generato da una distribuzione o l’alternativa. definiamo valore critico della statistica F per cui si ha una coda che comprende il 5% dell’intera distribuzione di frequenza, ma la distribuzione della statistica f ha una forma differente.
- Quando HP0 è vera→ primo grafico: la parte ombreggiata rappresenta HP0 falsa. Se osservo un valore di f<f critico→accetto HP 0 C’è anche una sovrapposizione delle 2 distribuzioni →la parte data falsa HP0 può generare valore di F<F critico accettando HP 0 Prima accettavamo HP 0 se si trovava in un valore critico sup o inf, ora avendo test ad una coda accetto HP 0 se valore sta nella parte bianca del grafico a sx.
- Se HP0 falsa la distribuzione è differente In seguito a sovrapposizione delle 2 distribuzione ho valori di f generati con probabilità β anche quando HP0 è falsa. LA POTENZA DEL TEST È DATA DA 1-β (=PROBABILITÀ DI RIFIUTARE HP0 QUANDO È FALSA) Se β errore di tipo II, tutto il resto della distribuzione è esattamente la probabilità di rifiutare HP0 quando è falsa COSA INFLUENZA LA POTENZA DI UN TEST: 1.ERRORE DI TIPO I/α. α è sotto il controllo dello sperimentatore. Abbiamo margine di movimento che ci permette di fare aggiustamenti. Frecce nere indicano valore di α=0. Se usiamo valore di α sup come 0,01, spostiamo i t critici verso l’ext (2 code) →dentro ai valori critici ci starà il 99%
Se spostiamo verso l’esterno i valori critici significa che ci spostiamo verso dx nella distribuzione di t data falsa HP →aumenta β→diminuisce potenza del test Cambiando il valore di α sposterei l’f critico, se commetto α varia 0,01, β aumenta. Avendo α minore→spostamento valori critici verso l’esterno→ampliamento di β. →potenza del test molto piccola→aumento di molto l’errore di tipo II→alta probabilità di accettare HP 0 quando è falsa→il test è poco potente →per aumentare la potenza del test→aumento α (ex anziché 0,05 0,1)→spostamento valori critici verso l’interno →diminuzione β. L’errore di tipo I influenza indirettamente errore di tipo II e quindi la potenza del test.
- PRINCIPIO PRECAUZIONARIO: Conseguenza di un eccessivo errore di tipo I e II: osservazione: ricchezza specie zona palustre molto bassa modello: mancanza di specie a causa di scarichi industriali HP: la ricchezza della zona impattata è minore di quella di zone palustri comparabili non influenzate da scarichi industriali HP0: la ricchezza della zona impattata è maggiore o uguale di quella in zone palustri comparabili non influenzate da scarichi industriali se faccio errore tipo I: rifiuto HP0 quando è vera→concludo in maniera errata che lo scarico industriale ha un effetto negativo se faccio errore II: accetto HP0 quando è falsa→concludo erroneamente che scarico industriale non ha effetto negativo sulla ricchezza di specie se commetto errore I, ci saranno approfondimenti (meglio di commettere errore II). Ex: HP0: farmaco non ha effetti collaterali →errore I: farmaco ha effetti collaterali Errore II: farmaco non ha effetti collaterali →MEGLIO FARE ERRORE I, ANZICHÉ II Meglio usare errore α=0, 10 →diminuisce probabilità errore II Ci sono casi in cui è giustificato errore I più grande e che aumenti potenza del test (PRINCIPIO PRECAUZIONARIO) 0,01; 0,10; 0,20 sono gli errori α che si possono usare 2.TAGLIA DEL CAMPIONE È sotto il controllo dello sperimentatore 2 distribuzioni:
- H0 vera con μ=
- distribuzione di frequenza alternativa a quella nulla è incentrata su mu= Se campioniamo per 1000 volte le distribuzioni di frequenza della variabile x otteniamo 2 t osservato: testiamo H0= valore medio è 100 i t critici sono calcolati dalle tavole e dalle tavole più aumenta taglia campione, più diminuisce il valore di t critico →le distribuzioni di frequenza si separano tra di loro →aumento potenza del test man mano che si aumenta la taglia del campione Se aumento n diminuisce l’errore standard 3.VARIANZA DELLA POPOLAZIONE
Differenza minima tra HP0 e ipotesi alternativa L’ipotesi alternativa è centrata su 115, HP su 110 →distribuzioni si separano all’aumentare di μ →DIMINUISCE SOVRAPPOSIZIONE→ AUMENTA POTENZA DEL TEST Ex. X= variabile che misura peso volpi Se mu=7, x medio maggiore rispetto a x medio se mu= Se peso medio volpi è 9→t osservato è ancora più grande →le distribuzioni di frequenza del t osservato data vera HP0 saranno molto più separate. Quella data vera HP0 e quella data falsa daranno valori di t molto differenti →sovrapposizione molto piccola→β molto piccolo SE CENTRATE SU VALORI MOLTO DIFFERENTI→DISTRIBUZIONI t OSSERVATE MOLTO DISTANTI TRA LORO LA POTENZA DEL TEST AUMENTA ALL’AUMENTARE DELLA TAGLIA DELL’EFFETTO ESPERIMENTI MANIPOLATIVI: Assegnazione delle unità sperimentali ai trattamenti: facciamo riferimento alla distribuzione t.
- Definizione della popolazione esaminata
- La distribuzione di frequenza di due campioni rappresentativi estratti dalla stessa popolazione non dovrebbe differire, eccetto che per l’errore di campionamento Problemi causati dalle necessità sperimentali per la definizione della popolazione esaminata: 1.L’abbondanza delle macroalghe può differire tra trattati e controlli indipendentemente dagli effetti degli erbivori Se voglio valutare effetto di erbivori gasteropodi patelle su popolamenti algali, si fa esperimento, per cui si ha HP0=dove escludo erbivori 2 esperimenti=controllo, situazione naturale ed uno in cui rimuovo patella Le vernice al rame per impedire il passaggio delle patelle viene applicata a zone sopraelevate per impedire che influenzi i popolamenti esaminati →comparo 2 popolazioni differenti (zone pianeggianti e zone sopraelevate) →Se trovo differenze non so se sono perché ho escluso erbivori o perché sto comparando 2 habitat diversi (pianeggianti e sopraelevati) →al netto dell’effetto è importante che le 2 popolazioni devono essere identiche 2.se assegno ai controlli solo le zona sopraelevate e trovo differenze in termini di abbondanza delle alghe posso concludere che l’effetto è dato dalle patelle.
Le differenze tra i trattati e controlli possono essere attribuite agli effetti degli erbivori DISEGNO SPERIMENTALE: ex: per capire l’effetto di un farmaco senza che sia influenzato da variabilità intrinseca →si prendono più individui da assegnare al trattamento (=REPLICAZIONE) →si prende in considerazione così la sorgente di variabilità casuale. 11 - 03 Spesso il t test non è sufficiente per verificare un’HP 0. Progettando un esperimento bisogna conoscere quali variabili possano influenzare la nostra variabilità di risposta. Esistono differenti sorgenti di variabilità. L’unica cosa che non varia mai è l’ERRORE CASUALE dovuto al fatto che ogni osservazione è unica. La variabilità si controlla attraverso la REPLICAZIONE (=avere un numero superiore ad 1 di unità di osservazione per ciascuno dei trattamenti inclusi nell’esperimento). Inoltre c’è ERRORE SISTEMATICO: se prendiamo persone a caso l’errore casuale è che alcune sono più basse dell’altezza media, altre più alte→la differenza va in entrambe le direzioni. Invece l’errore sistematico va in un’unica direzione (=sempre più alti o sempre più bassi rispetto altezza media, vd. Esempio sopra pesci acquario lenti). →si controlla attraverso la RANDOMIZZAZIONE=ciascuna osservazione ha stessa probabilità di essere inclusa nell’esperimento o in uno dei trattamenti usati per testare HP 0 (attraverso numeri random). Altre sorgenti di variabilità possono introdurre una variabilità nella variabile che stiamo studiando. Queste altre sorgenti si possono controllare attraverso un’INTERSPERSIONE (=se numeri random portano a selezionare individui in una sola certa fascia ci sarebbero già differenze e quindi devono essere interspersi per controllare altre sorgenti di variabilità) delle altre osservazioni che andiamo a compiere. Le nostre osservazioni devono essere INTERSPERSE nello spazio per evitare che alcuni individui o superfici siano influenzati da alcune sorgenti o no. EX: errore sistematico e effetto inquinanti su velocità pesce. L’errore va sempre nella stessa direzione (=errore sistematico): abbiamo assegnato i 12 pesci più lenti ad un determinato trattamento. Se vengono selezionati in modo random per cui ogni pesce ha un suo numero→errore casuale (non sistematico). Aumento probabilità di tipo 1 (=rifiutare HP0 quando è vera). Il problema dell’interspersione è importante quando si lavora con variabili distribuite nello spazio. EX: IMPORTANTE: AREA CONTROLLO=consumatore presente AREA TRATTAMENTO=consumatore rimosso
abbiamo una media per ogni area→comparo medie fra loro →trovo stime delle 3 sorgenti di variabilità →stimo come varia biomassa in assenza a presenza del consumatore Se vicino alle aree di controllo ci fosse una città, ci sarebbe comunque una SEGREGAZIONE SPAZIALE →bisogna scegliere aree in modo che siano intersperse→INTERSPERSIONE →ogni area permette di stimare naturale variabilità tra le aree. In maniera casuale assegno 3 aree ad un trattamento e 3 ad un altro LA PSEUDOREPLICAZIONE CONSISTE NEL VALUTARE L’EFFETTO DI UN FATTORE IN BASE A SORGENTE DI VARIABILITA’ TRA AREE, NON TRA REPLICHE. Ex. Pseudoreplicazione: calcolare variazione nella ricchezza di specie di piante tra stagioni. Difficile in quanto ogni stagione mostra differenze tra di loro. Per concludere che le differenze siano tra stagioni devo assicurarmi che queste siano superiori delle differenze tra dati nella stessa stagione. →effettuo più osservazioni per stagioni. In questo modo posso distinguere variabilità tra date differenti delle stesse stagioni Le differenze tra stagioni ci sono quando la variabilità tra le medie di ogni stagione è superiore delle medie in una stessa stagione EX: come varia altezza piante tra intervalli altitudinali. Usando una sola area si confonde variabilità naturale tra aree con differenze legate all’altitudine →aggiungo almeno un’altra area ad ogni altitudine. RANDOMIZZAZIONE:
esempio tratto da articolo scientifico: la predazione da parte di pesci su larve di libellule facilita l’impollinazione di piante terrestri spesso gli esperimenti implicano più di un livello di un fattore: nell’esempio del consumatore i livelli del consumatore erano 2, in quello delle stagioni erano 4. Il numero minimo di livelli di un fattore è 2. PER PIU’ DI 2 LIVELLI NON SI PUO USARE TEST t EX: cascate trofiche tra ecosistemi. I pesci nutrendosi di larve di libellula, hanno effetto positivo indirettamente su piante perché la minoranza di libellule favorisce abbondanza insetti impollinatori. Senza pesci→molte libellule di grandi dimensioni Lo stesso vale per densità adulti. L’errore standard è una misura di precisione (indicato da lineetta su grafico) Grafico disponibilità polline su y=mancanza di impollinatori P<0,03 deriva da test di ipotesi nulla Tasso di visita dei fiori da parte di impollinatori
- predatore assente
- predatore presente Problema di artefatto: con il caso del predatore assente non si valuta l’influenza della gabbia sia sulla pianta (magari altera produzione e qualità fiori) sia sul comportamento degli impollinatori.