Download Understanding CPU Execution Time and Instruction Pipelining: MIPS and CPI and more Slides Advanced Computer Architecture in PDF only on Docsity!
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Advanced Computer ArchitectureAdvanced Computer Architecture
Course Goal:Understanding important emerging design techniques, machine structures,technology factors, evaluation methods that will determine the form of high-performance programmable processors and computing systems in 21st Century.Important Factors: •
Driving Force: Applications with diverse and increased computational demands even inmainstream computing (multimedia etc.)
Techniques must be developed to overcome the major limitations of current computingsystems to meet such demands:
Instruction-Level Parallelism (ILP) limitations, Memory latency, IO performance.
Increased branch penalty/other stalls in deeply pipelined CPUs.
General-purpose processors as only homogeneous system computing resource.
Increased density of VLSI logic (~ nine billion transistors in 2015)
Enabling Technology for many possible solutions:^ –
Enables implementing more advanced architectural enhancements.
Enables chip-level Thread Level Parallelism:
Simultaneous Multithreading (SMT)/Chip Multiprocessors (CMPs, AKA multi-core processors).
Enables a high-level of chip-level system integration.
System On Chip (SOC) approach
- Integration of other types of computing elements on chip
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Course Topics
Topics we will cover include: •
Overcoming inherent ILP & clock scaling limitations by exploitingThread-level Parallelism (TLP):
Support for Simultaneous Multithreading (SMT).
Alpha EV8. Intel P4 Xeon and Core i7 (aka Hyper-Threading), IBM Power5.
Chip Multiprocessors (CMPs):
The Hydra Project: An example CMP with Hardware Data/Thread Level Speculation(TLS) Support.
IBM Power4, 5, 6 ….
Instruction Fetch Bandwidth/Memory Latency Reduction:
Conventional & Block-based Trace Cache (Intel P4).
Advanced Dynamic Branch Prediction Techniques.
Towards micro heterogeneous computing systems:
Vector processing.
Vector Intelligent RAM (VIRAM).
Digital Signal Processing (DSP), Media Processors.
Graphics Processor Units (GPUs).
Re-Configurable Computing and Processors.
Virtual Memory Design/Implementation Issues.
High Performance Storage: Redundant Arrays of Disks (RAID).
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Computing Engine Choices
General Purpose Processors (GPPs): Intended for general purpose computing(desktops, servers, clusters..)
Application-Specific Processors (ASPs): Processors with ISAs andarchitectural features tailored towards specific application domains
E.g Digital Signal Processors (DSPs), Network Processors (NPs), Media Processors,Graphics Processing Units (GPUs),
Vector Processors??? ...
Co-Processors: A hardware (hardwired) implementation of specificalgorithms with limited programming interface (augment GPPs or ASPs)
Configurable Hardware:
Field Programmable Gate Arrays (FPGAs)
Configurable array of simple processing elements
Application Specific Integrated Circuits (ASICs): A custom VLSI hardwaresolution for a specific computational task
The choice of one or more depends on a number of factors including:
- Type and complexity of computational algorithm
(general purpose vs. Specialized)
Desired level of flexibility
Development cost
Power requirements
Real-time constrains
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Computing Engine Choices
General Purpose
Processors (GPPs):
Application-Specific
Processors (ASPs)
Co-Processors
Application SpecificIntegrated Circuits
(ASICs)
Configurable Hardware
E.g Digital Signal Processors (DSPs),Network Processors (NPs),Media Processors,Graphics Processing Units (GPUs)
- Type and complexity of computational algorithms
(general purpose vs. Specialized)
Desired level of flexibility
Development cost
Power requirements
Selection Factors:
Programmability /Flexibility
Specialization , Development cost/timePerformance/Chip Area/Watt (Computational Efficiency)
Processor = Programmable computing element that runsprograms written using a pre-defined set of instructions (ISA)
ISA Requirements
→
Processor Design
Software
Hardware
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
CMPE550 ReviewCMPE550 Review
Recent Trends in Computer Design.
Computer Performance Measures.
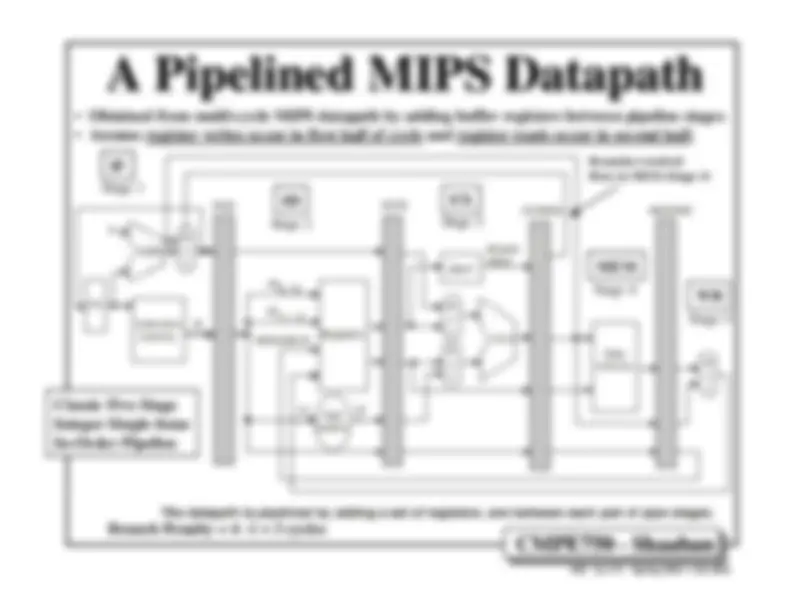
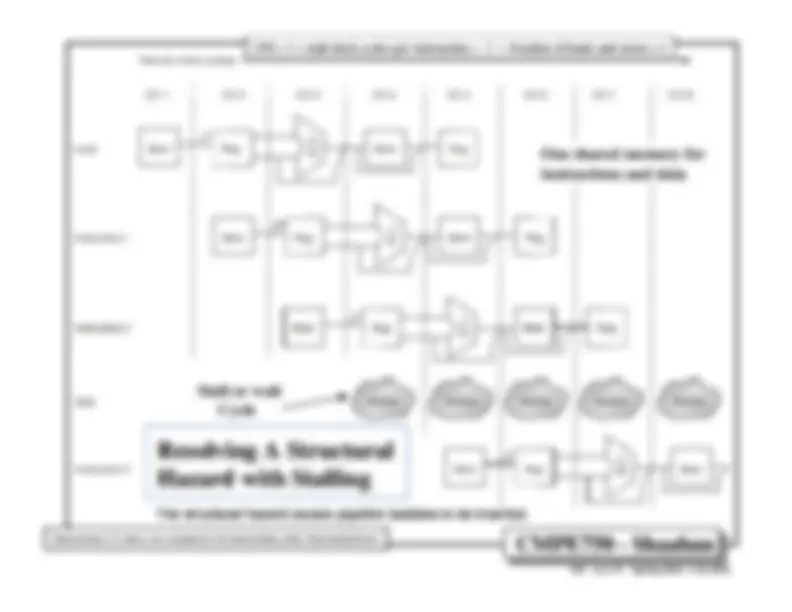
Instruction Pipelining.
Dynamic Branch Prediction.
Instruction-Level Parallelism (ILP).
Loop-Level Parallelism (LLP) + Data Parallelism.
Dynamic Pipeline Scheduling.
Multiple Instruction Issue (CPI < 1):
Superscalar vs. VLIW
Dynamic Hardware-Based Speculation
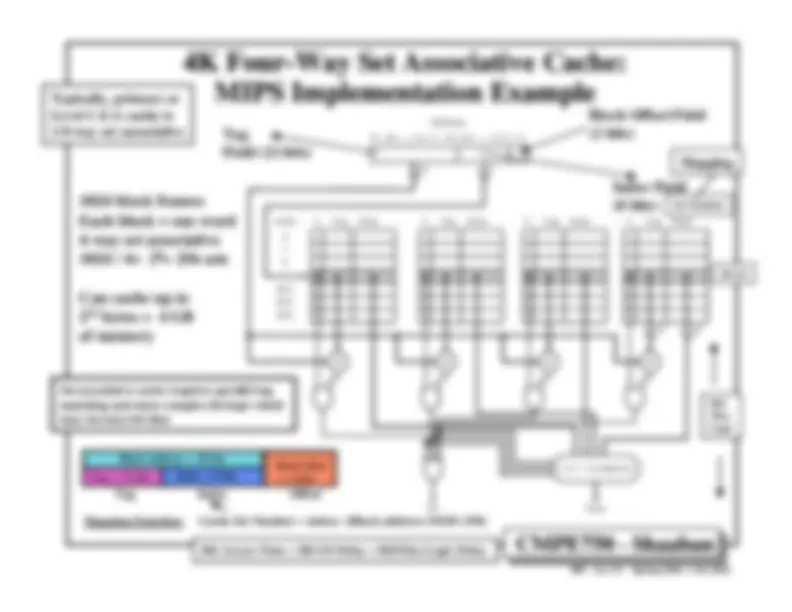
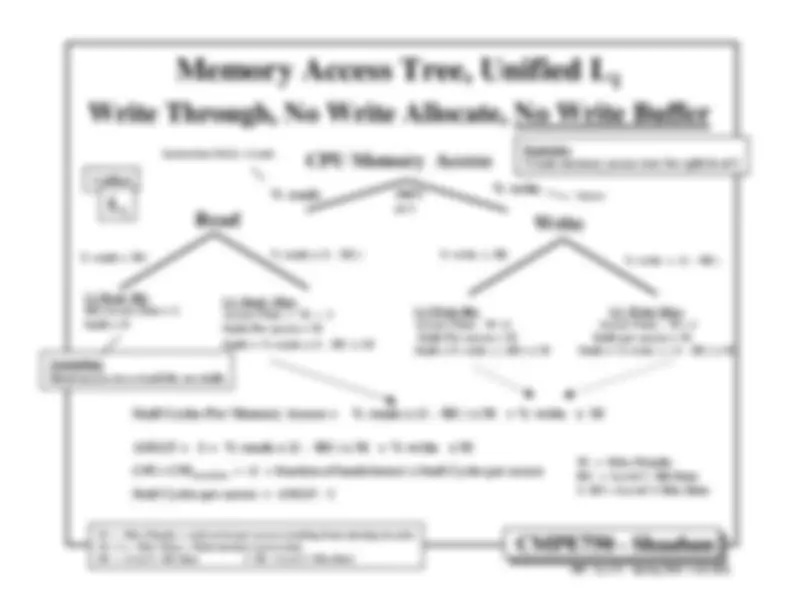
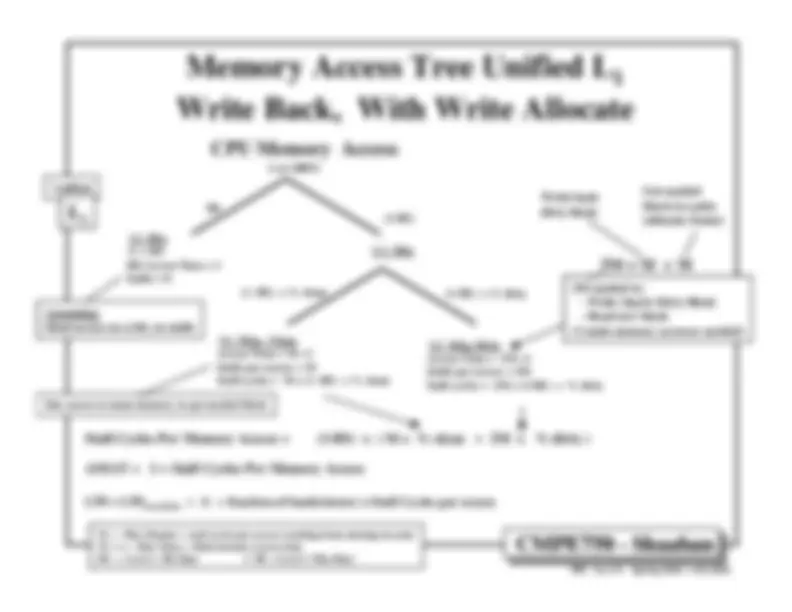
Cache Design & Performance.
Basic Virtual memory Issues
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Trends in Computer DesignTrends in Computer Design
The cost/performance ratio of computing systems have seen a steadydecline due to advances in:
Integrated circuit technology:
decreasing feature size,
λ
Clock rate improves roughly proportional to improvement in
λ
Number of transistors improves proportional to
λ
2
(or faster).
Rate of clock speed improvement have decreased in recent years.
Architectural improvements in CPU design.
Microprocessor-based systems directly reflect IC and architecturalimprovement in terms of a yearly 35 to 55% improvement inperformance.
Assembly language has been mostly eliminated and replaced by otheralternatives such as C or C++
Standard operating Systems (UNIX, Windows) lowered the cost ofintroducing new architectures.
Emergence of RISC architectures and RISC-core architectures.
Adoption of quantitative approaches to computer design based onempirical performance observations.
Increased importance of exploiting thread-level parallelism (TLP) inmain-stream computing systems.
Simultaneous Multithreading SMT/Chip Multiprocessor (CMP)Chip-level Thread-Level Parallelism (TLP)
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Microprocessor PerformanceMicroprocessor Performance
1987-^1987
97
0
800 600 400 200
12001000
87
88
89
90
91
92
93
94
95
96
97
DEC Alpha 21264/
DEC Alpha 5/
DEC Alpha 5/
DEC Alpha 4/
IBM POWER 100
DECAXP/
HP
Sun
IBMRS/
MIPS
M/
MIPS
M
Integer SPEC92 PerformanceInteger SPEC92 Performance^2000
> 100x performance increase in the last decade
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Microprocessor Transistor Count Growth Rate^ Microprocessor Transistor Count Growth Rate
Intel 4004(2300 transistors)
Currently ~ 9 Billion
Still holds today
Moore’s Law:Moore’s Law:2X transistors/ChipEvery 1.5-2 years(circa 1970)
~4,000,000x transistor density increase in thelast 45 years
How to best exploit increased transistor count? •
Keep increasing cache capacity/levels?
Multiple GPP cores?
Integrate other types of computing elements?
4-Bit
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Transistors
1, 10, 100,
1,000, 10,000, 100,000,
1970
1975
1980
1985
1990
1995
2000
2005
Bit-level parallelism
Instruction-level
Thread-level (?)
i
i
i
i80286 i
i
R
Pentium
R
R
Parallelism in Microprocessor VLSI Generations^ Parallelism in Microprocessor VLSI Generations
SimultaneousMultithreading SMT:e.g. Intel’s Hyper-threadingChip-Multiprocessors (CMPs)e.g IBM Power 4, 5
Intel Pentium D, Core DuoAMD Athlon 64 X
Dual Core Opteron
Sun UltraSparc T1 (Niagara)
Chip-LevelParallelProcessing
Even more importantdue to slowing clockrate increase
Multiple micro-operations
per cycle (multi-cycle non-pipelined)
Superscalar/VLIWCPI <
Single-issuePipelinedCPI =
Not PipelinedCPI >> 1
(ILP)
Single Thread
(TLP)
Improving microprocessor generation performance byexploiting more levels of parallelism
Thread-LevelParallelism (TLP)
AKA Operation-Level Parallelism
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Microprocessor Architecture TrendsMicroprocessor Architecture Trends
CISC Machines
instructions take variable times to complete
RISC Machines (microcode)
simple instructions, optimized for speed
RISC Machines (pipelined)
same individual instruction latency
greater throughput through instruction "overlap"
Superscalar Processors
multiple instructions executing simultaneously
Multithreaded Processors
additional HW resources (regs, PC, SP)each context gets processor for x cycles
VLIW
"Superinstructions" grouped together
decreased HW control complexity
Single Chip Multiprocessors
duplicate entire processors
(tech soon due to Moore's Law)
SIMULTANEOUS MULTITHREADING
multiple HW contexts (regs, PC, SP)each cycle, any context may execute
CMPs
(SMT)
SMT/CMPs
e.g. IBM Power5,6,7 , Intel Pentium D, Sun Niagara - (UltraSparc T1)
Intel Nehalem (Core i7)
SingleThreaded
(e.g IBM Power 4/5,
AMD X2, X3, X4, Intel Core 2)
e.g. Intel’s HyperThreading (P4)
(Single or Multi-Threaded)
General Purpose Processor (GPP)
Chip-Level TLP
ILP
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Architectural ImprovementsArchitectural Improvements
Increased optimization, utilization and size of cache systems withmultiple levels (currently the most popular approach to utilize theincreased number of available transistors).
Memory-latency hiding techniques.
Optimization of pipelined instruction execution.
Dynamic hardware-based pipeline scheduling.
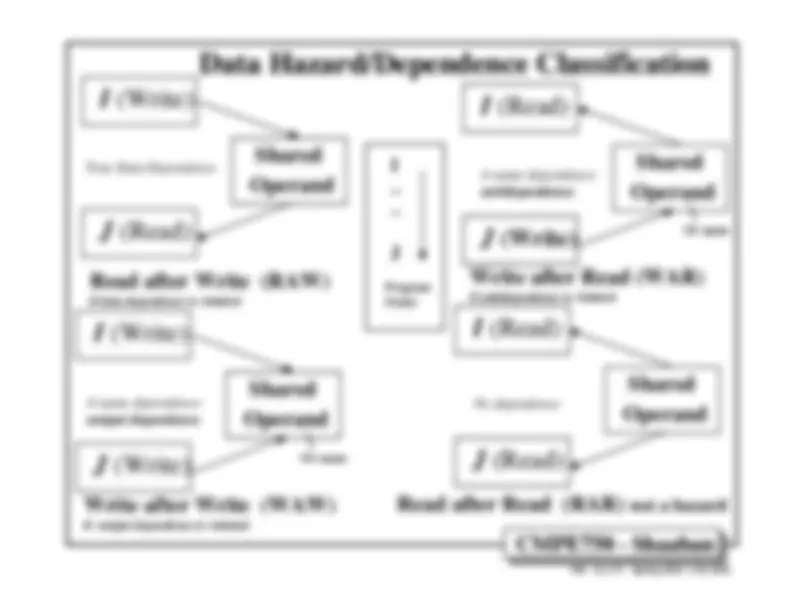
Improved handling of pipeline hazards.
Improved hardware branch prediction techniques.
Exploiting Instruction-Level Parallelism (ILP) in terms of multiple-instruction issue and multiple hardware functional units.
Inclusion of special instructions to handle multimedia applications.
High-speed system and memory bus designs to improve data transferrates and reduce latency.
Increased exploitation of Thread-Level Parallelism in terms ofSimultaneous Multithreading (SMT) and Chip Multiprocessors(CMPs)
Including Simultaneous Multithreading (SMT)
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Metrics of Computer PerformanceMetrics of Computer Performance
Compiler
Programming
Language Application Datapath
Control
Transistors Wires
Pins
ISA
Function Units
Cycles per second (clock rate).
Megabytes per second.
Execution time: Target workload,SPEC95, SPEC2000, etc.
Each metric has a purpose, and each can be misused.
(millions) of Instructions per second – MIPS(millions) of (F.P.) operations per second – MFLOP/s
(Measures)
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Factors Affecting CPU PerformanceFactors Affecting CPU Performance
CPU time
= Seconds
= Instructions x Cycles
x
Seconds
Program
Program
Instruction
Cycle
CPU time
= Seconds
= Instructions x Cycles
x
Seconds
Program
Program
Instruction
Cycle
CPIIPC
Clock Cycle C
Instruction
Count I
Program
Compiler
Organization(Micro-Architecture)
Technology
Instruction Set
Architecture (ISA)
X X
X
X
X X X
X X
T = I x CPI
x C
VLSI
CMPE750 -CMPE
Shaaban
Lec # 1
Spring 2016 1-26-
Performance Enhancement Calculations:Performance Enhancement Calculations:
Amdahl's LawAmdahl's Law
The performance enhancement possible due to a given designimprovement is limited by the amount that the improved feature is used
Amdahl’s Law:
Performance improvement or speedup due to enhancement E:
Execution Time without E
Performance with E
Speedup(E) =
Execution Time with E
Performance without E
Suppose that enhancement E accelerates a fraction F of theexecution time by a factor S and the remainder of the time isunaffected then:
Execution Time with E =
((1-F) + F/S) X Execution Time without E
Hence speedup is given by:
Execution Time without E
Speedup(E) =
((1 - F) + F/S) X Execution Time without E
(1 - F) + F/S
F (Fraction of execution time enhanced) refersto original execution time before the enhancement is applied