Download Repeated Measures ANOVA: Effect of Question Type on Word Recognition and more Lecture notes History in PDF only on Docsity!
Repeated Measures ANOVA
In this example participants saw one of three types of questions before seeing a word – a surface level question (Is the word printed in upper case letters?), a phonemic level question (Does the word rhyme with cat?) and a semantic level question (Is the word a type of animal?). Each participant saw 20 question / words pairs for each of the three types of questions. For each question / word pair, they pressed one key on the keyboard if the answer to the question was “Yes” and a different key if the answer was “No”. After seeing all 60 question / word pairs, they saw 180 words. Sixty of those words where the words they just studied and the other 120 words were distractors. They had to select the 60 words they had just seen. For each of the three question types, the number of words correctly recognized was recorded for each of the 25 participants.
- Step 1: Write the null and alternative hypotheses and specify the probability of making a Type I error:
H 0 : μSurface = μRhyme = μSemantic H 1 : not H 0
α =.
- Step 2: We will compare the reported p value to α. If p ≤ α, we will reject H 0 and conclude that the type of mnemonic likely had an effect on ordered recall.
- Step 3: Calculate the test statistic:
a. Open SPSS
b. Either type the data (see the second to last page for the data) or open a data set. The class data set (for homework) is available from . Save the data file somewhere and open it with SPSS.
If you are typing the data, switch to the Variable View (click on that tab in the lower left) and create three variables. Name one of the variables surface, one phonemic and name the last variable semantic. Switch back to the Data View. Enter the data. Be sure to enter all of a given individual’s data on the same row.
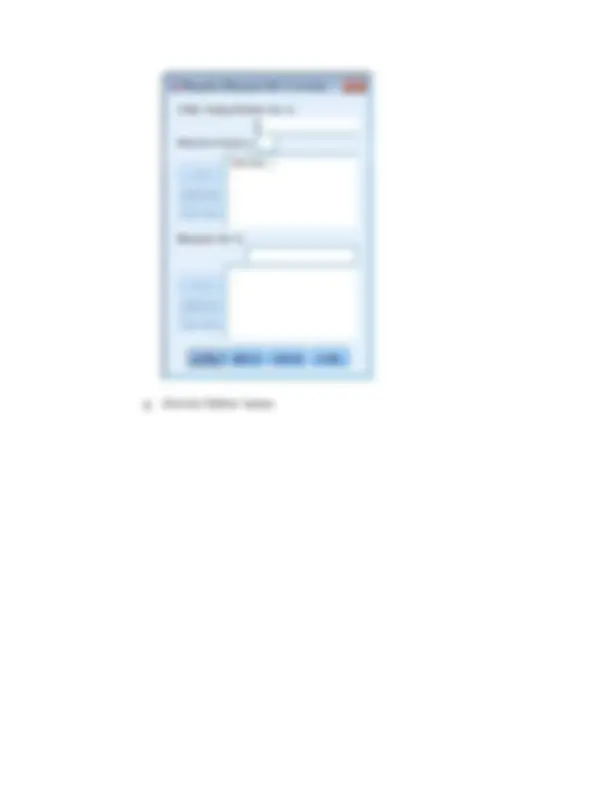
c. Analyze | General Linear Model | Repeated Measures
d. In the “Within-Subjects Factor Name:” box, type of the name of the IV: question
e. In the “Number of Levels:” box, type the number of levels of this IV: 3
f. Click the “Add” button
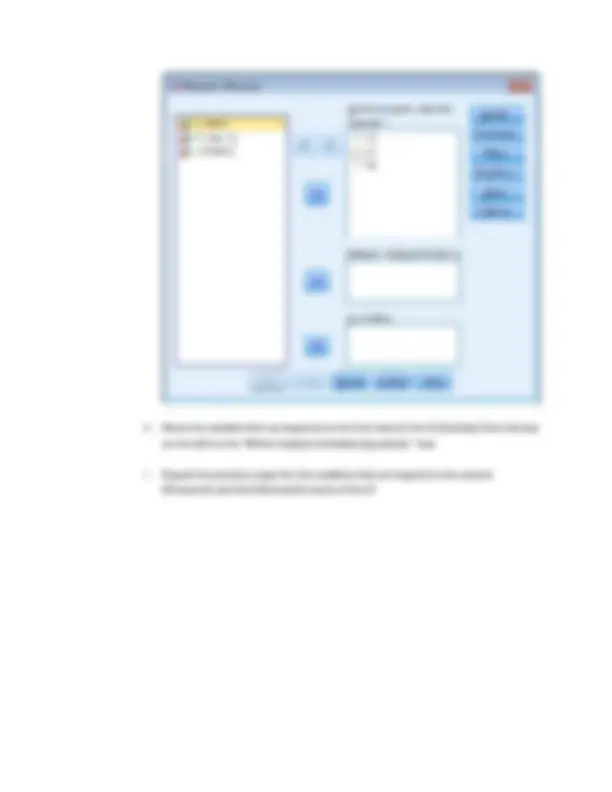
h. Move the variable that corresponds to the first level of the IV (Surface) from the box on the left to the “Within-Subjects Variables (question):” box.
i. Repeat the previous steps for the variables that correspond to the second (Phonemic) and third (Semantic) levels of the IV
j. While Post Hoc tests might be necessary (this IV has three levels; if we reject H 0 , we would need to perform multiple comparisons), SPSS will not perform them for a repeated measures IV. Thus, do not click on the “Post Hoc” button.
k. Click on the “Options” button.
n. Click the Continue button
o. Click the OK button
p. The SPSS output viewer will open
q. Check the first part of the output to see if the levels of the independent variable are appropriately specified:
r. The next part of the output gives descriptive statistics for the dependent variable for each condition (level of the independent variable):
s. This tells us that for the mean number of words recognized for the Surface question is 8.20 (mean column and Surface row), the sample standard deviation (s) is 3.786, and the sample size (N) is 25. Likewise, this tells us that for the Phonemic question there were 15 scores (in the N column of the Phonemic row), that the sample mean ( ) is 10.40 (mean column and the Phonemic row), and the sample standard deviation (s) is 4.967.
t. The next part of the output that is of interest to us is the ANOVA summary table:
n. For this class, we will assume that the sphericity assumption is satisfied and thus only look at the rows that say “Sphericity Assumed”. The only rows of interest are the ones with the IV (question) and Error(question). The between-treatment information is on the row labeled with the IV. The error variance information is on the row labeled with Error(question). (These should make sense – between- treatment variance measures the effect of the IV and error and the error variances measures error.)
- Calculate the HSD:
√ √
q is from a table for critical q values (see ) with α = .05, df = 48 (the degrees of freedom of the Error(question) row), and k = 3 (there are three means to compare). MSerror is from the Error(question) row. n is from the descriptive statistics output.
- If the absolute value of the difference of a pair of sample means is at least as large as the HSD, then you can reject H 0 that those two means are equal in the population.
From the Descriptive Statistics output:
| MSurface – MPhonemic | = | 8.20 – 10.40 | = 2.2; Reject H 0 : μSurface = μPhonemic | MSurface – MSemantic | = | 8.20 – 14.24 | = 6.04; Reject H 0 : μSurface = μPSemantic | MPhonemic - MSemantic | = | 10.40 – 14.24 | = 3.84; Reject H 0 : μPhonemic = μSemantic
Modifying what we wrote previously to include the results of the Tukey multiple comparisons:
The mean number of words correctly recognized in the surface ( M = 8.20), phonemic ( M = 10.40) and semantic ( M = 14.24) conditions are not likely all equal. The repeated measures ANOVA revealed a main effect of type of question, F (2, 48) = 25.871, MSerror = 9.030, η^2 = .519, p = .000, α = .05. Tukey’s test revealed that each type of question was likely different from every other type of question in the population, all p < .05.
Step 1 is identical to those used with SPSS.
Step 2: We will return to it once we know the dfs.
Step 3: Calculate the test statistic:
Surface Phonemic Semantic Person 3 6 14 4 10 7 3 8 13 10 13 11 11 14 10 5 9 2 6 6 13 5 3 11 8
ΣX 205 260 356 273.6667 205+260+356=
ΣX^2 2025 3296 5658 3359.
n 25 25 25 25 N = 25+25+25=
8.2 10.4 14.24 10.94667 10.
SS
273.67^2 /25=363.
SSTotal = ΣX^2 – (ΣX)^2 / N = 10,979-821^2 /75=1991.