Download Applying Statistical Analysis to Domestic Violence: One Way & Repeated Measures ANOVA and more Essays (high school) History in PDF only on Docsity!
One Way ANOVA (Between Measures)
This is a data set from one of my dissertation students last year drastically reduced. This domestic violence
data set focuses on attitudes towards domestic violence taking into consideration the gender of the
perpetrator and that of the victim. The study used a vignette whereby the gender of the perpetrator and
the victim were changed. Everything else remained identical. Each level of the scenario is identified by two
sets of gender therefore male/male = male perpetrator and male victim (i.e. a homosexual violence
scenario). The IV was therefore Scenario with four levels (Male/ Male, Male/ Female, Female/ Male and
Female/ Female). The DV was one question – “how seriously do you rate this case?” The higher number
equates to higher levels of perceived seriousness.
Between subjects data
should look like this
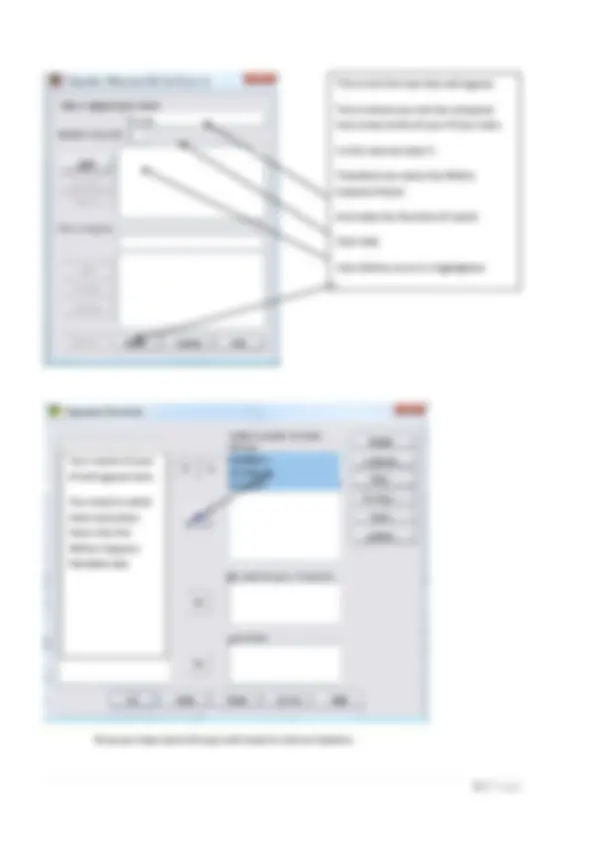
Analyze > General Linear Model > Univariate
Your Variables will
appear here – be
sure you know
which one is the IV
and which is the DV
Place your DV in the
‘Dependent Variable’
box
And the IV in the
‘Fixed Factor(s)’ box
Select Options
Univariate Analysis of Variance
This box just informs you of the different levels of the IV.
It will also tells you how many participants you have in
each group.
I have scored it out as it doesn’t provide you with any
NEW information
This box provides you with the descriptive statistics that
you will need to report. Note that this box provides you
with mean and SD but no 95%CI.
The estimated marginal means box provides you with
the mean, SE (remember the difference) and the 95%CI
(which you will need)
This is your Homogeneity of Variances test.
Remember this tests the differences in variances across the three
different groups. If there are significant differences in variation this
would be below 0.05 therefore indicating a violation of the
assumption. In this case there is a violation of homogeneity of
variances.
Recall that in large sample sizes this test becomes unreliable so you
may want to use the following rule of thumb: if the biggest
variance is 3x bigger than the smallest variance then you have a
problem.
The above box is the main table needed for your write up... You should be reading the line that contains the name of the IV only with addition of the error df for write up. One way Between Measures ANOVA indicated a significant difference between two or more groups: F(3, 153) = 6.178, p < 0.001, pη
= 0.108, observed power = 0. Remember Partial eta squared or pη
is the effect size calculation for ANOVA Observed Power may be useful for future research so report it. The 95% CI within this table should be reported with your descriptive statistics. Very briefly they indicate where the true population mean is.
One Way Repeated Measures ANOVA
Analyze > General Linear Model > Repeated Measures
Within subjects data
set should look like this.
This box simply indicates if some of
your levels of the IV can be grouped
together as one. In this case, due to all
being significantly different from one
another, there are no homogenous
subsets.
Once you have done this you will need to click on Options.
This is the first box that will appear.
This is where you tell the computer
how many levels of your IV you have.
In this case we have 3
Therefore we name the Within
Subjects Factor
And state the Number of Levels
Click Add.
Click Define once it is highlighted
Your Levels of your
IV will appear here.
You need to select
them and place
them into the
Within Subjects
Variables box
Descriptive Statistics Mean Std. Deviation N baseline 41.1296 12.45858 108 rhyming 48.9722 12.08031 108 incongr 66.2222 16.17159 108 Effect Value F Hypothesis df Error df Sig. Partial Eta Squared Observed Powerb Stroop Pillai's Trace .681 113.191a^ 2.000 106.000 .000 .681 1. Wilks' Lambda .319 113.191a^ 2.000 106.000 .000 .681 1. Hotelling's Trace 2.136 113.191a^ 2.000 106.000 .000 .681 1. Roy's Largest Root 2.136 113.191a^ 2.000 106.000 .000 .681 1. Mauchly's Test of Sphericityb Measure:MEASURE_ Within Subjects Effect Mauchly's W Approx. Chi- Square df Sig. Epsilona Greenhouse- Geisser Huynh-Feldt Lower-bound Stroop .705 37.013 2 .000 .772 .782. Tests the null hypothesis that the error covariance matrix of the orthonormalized transformed dependent variables is proportional to an identity matrix. a. May be used to adjust the degrees of freedom for the averaged tests of significance. Corrected tests are displayed in the Tests of Within-Subjects Effects table. b. Design: Intercept Within Subjects Design: Stroop
Mauchly’s test of sphericity: we are now aware that the Homogeneity of variances is important within between group
statistics many people assume this isn’t an issue in repeated measures. This is not the case therefore the assumption of
sphericity can be likened to the assumption of homogeneity of variance. Sphericity is more a general condition of
compound symmetry which holds true when both variances across conditions are equal and the covariance’s between
pairs of conditions are equal. Sphericity thus refers to the equality of variances of the differences between treatment
levels. So if you take each pair of treatment levels, and calculate the differences between each pair of scores, then it is
necessary that these differences have equal variances. You need to have at least 3 conditions for sphericity to e an
issue.
This box provides you with the
descriptive statistics of your data that
you will need to report.
Remember you can get the 95% CI
from the marginal means further down
in the output
The above box provides the multivariate tests. For ANOVA you do not need to concern yourself with this.
Source Type III Sum of Squares df Mean Square F Sig. Partial Eta Squared Observed Powera Stroop Sphericity Assumed 35593.521 2 17796.760 170.888 .000 .615 1. Greenhouse-Geisser 35593.521 1.545 23042.091 170.888 .000 .615 1. Huynh-Feldt 35593.521 1.563 22772.168 170.888 .000 .615 1. Lower-bound 35593.521 1.000 35593.521 170.888 .000 .615 1. Error(Stroop) Sphericity Assumed 22286.530 214 104. Greenhouse-Geisser 22286.530 165.285 134. Huynh-Feldt 22286.530 167.244 133. Lower-bound 22286.530 107.000 208. The highlighted aspects are those that need writing up. Why use the Greenhouse-Geisser? The Greenhouse-Geisser is used when Sphericity cannot be assumed. However, authors often recommend that this is used all the time. When reporting the Greenhouse-Geiser df round the figures up. Source Stroop Type III Sum of Squares df Mean Square F Sig. Partial Eta Squared Observed Powera Stroop Linear 34000.543 1 34000.543 228.356 .000 .681 1. Quadratic 1592.978 1 1592.978 26.821 .000 .200. Error(Stroop) Linear 15931.540 107 148. Quadratic 6354.990 107 59. Source Type III Sum of Squares df Mean Square F Sig. Partial Eta Squared Observed Powera Intercept 879739.447 1 879739.447 2482.440 .000 .959 1. Error 37919.194 107 354. The above two boxes can be ignored – you do not need to write them up or understand what they tell you
Another table of the multivariate tests which is not needed for the write up. Value F Hypothesis df Error df Sig. Partial Eta Squared Observed Powerb Pillai's trace .681 113.191a^ 2.000 106.000 .000 .681 1. Wilks' lambda .319 113.191a^ 2.000 106.000 .000 .681 1. Hotelling's trace 2.136 113.191a^ 2.000 106.000 .000 .681 1. Roy's largest root 2.136 113.191a^ 2.000 106.000 .000 .681 1. Write up: One way repeated ANOVA indicated a significant difference in stroop tasks: F(2, 165) = 170.89, p < 0.001, pη
= 0.615, observed power = 1.00. Post hoc analysis indicated these differences to be between conditions 1 & 2 (p < 0.001, 95%CI [-9.785, -5.900]), conditions 1 & 3 (p <0.001, 95% CI [- 28.384, -21.801]) and conditions 2 & 3 (p < 0.001, 95%CI [-20.101, -14.399]).
Non- Parametric Equivalents: Between Measures –
Kruskal Wallis
Analyze > K Independent Samples
Place your DV into the ‘Test Variable
List’
Place your IV into the ‘Grouping
Variable’ and then select ‘Define
Groups’
This will bring up a separate dialogue
box. Here you need to state the
minimum and maximum range for the
IV
Once this has been done click continue
and then OK
16 | P a g e
Non- Parametric Equivalents: Within Measures –
Freedman
Analyze> Non Parametric tests> K Related Tests
Select all the levels of the
variables of interest and
place them over into ‘test
variables’
Then select OK
Mean ranks as before. This indicates
that the incongruent group has the
longest time to read through the list.
Test statistics are needed for your
write up
Thus for this study
Freedman test indicates a significant
difference between the groups on
speed of reading: χ^2 (2) 145.814, p <
If you would like to follow this up run
non-parametric wilcoxen test
correcting for number of tests used.