Download Applications of thread level parallelism and more Lecture notes Computer Architecture and Organization in PDF only on Docsity!
192 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
until just before the store commits and can be placed directly into the store’s
ROB entry by the sourcing instruction. This is accomplished by having the hard-
ware track when the source value to be stored is available in the store’s ROB
entry and searching the ROB on every instruction completion to look for depen-
dent stores.
This addition is not complicated, but adding it has two effects: We would
need to add a field to the ROB, and Figure 3. 14 , which is already in a small font,
would be even longer! Although Figure 3. 14 makes this simplification, in our
examples, we will allow the store to pass through the write result stage and sim-
ply wait for the value to be ready when it commits.
Like Tomasulo’s algorithm, we must avoid hazards through memory. WAW
and WAR hazards through memory are eliminated with speculation because the
actual updating of memory occurs in order, when a store is at the head of the
ROB, and, hence, no earlier loads or stores can still be pending. RAW hazards
through memory are maintained by two restrictions:
1. Not allowing a load to initiate the second step of its execution if any active
ROB entry occupied by a store has a Destination field that matches the value
of the A field of the load.
2. Maintaining the program order for the computation of an effective address of
a load with respect to all earlier stores.
Together, these two restrictions ensure that any load that accesses a memory loca-
tion written to by an earlier store cannot perform the memory access until the
store has written the data. Some speculative processors will actually bypass the
value from the store to the load directly, when such a RAW hazard occurs.
Another approach is to predict potential collisions using a form of value predic-
tion; we consider this in Section 3. 9.
Although this explanation of speculative execution has focused on floating
point, the techniques easily extend to the integer registers and functional units.
Indeed, speculation may be more useful in integer programs, since such programs
tend to have code where the branch behavior is less predictable. Additionally,
these techniques can be extended to work in a multiple-issue processor by allow-
ing multiple instructions to issue and commit every clock. In fact, speculation is
probably most interesting in such processors, since less ambitious techniques can
probably exploit sufficient ILP within basic blocks when assisted by a compiler.
The techniques of the preceding sections can be used to eliminate data, control
stalls, and achieve an ideal CPI of one. To improve performance further we
would like to decrease the CPI to less than one, but the CPI cannot be reduced
below one if we issue only one instruction every clock cycle.
3.7 Exploiting ILP Using Multiple Issue and
Static Scheduling
3.7 Exploiting ILP Using Multiple Issue and Static Scheduling ■ 193
The goal of the multiple-issue processors , discussed in the next few sections,
is to allow multiple instructions to issue in a clock cycle. Multiple-issue proces-
sors come in three major flavors:
1. Statically scheduled superscalar processors
2. VLIW (very long instruction word) processors
3. Dynamically scheduled superscalar processors
The two types of superscalar processors issue varying numbers of instructions
per clock and use in-order execution if they are statically scheduled or out-of-
order execution if they are dynamically scheduled.
VLIW processors, in contrast, issue a fixed number of instructions formatted
either as one large instruction or as a fixed instruction packet with the parallel-
ism among instructions explicitly indicated by the instruction. VLIW processors
are inherently statically scheduled by the compiler. When Intel and HP created
the IA-64 architecture, described in Appendix H, they also introduced the name
EPIC—explicitly parallel instruction computer—for this architectural style.
Although statically scheduled superscalars issue a varying rather than a fixed
number of instructions per clock, they are actually closer in concept to VLIWs,
since both approaches rely on the compiler to schedule code for the processor.
Because of the diminishing advantages of a statically scheduled superscalar as the
issue width grows, statically scheduled superscalars are used primarily for narrow
issue widths, normally just two instructions. Beyond that width, most designers
choose to implement either a VLIW or a dynamically scheduled superscalar.
Because of the similarities in hardware and required compiler technology, we
focus on VLIWs in this section. The insights of this section are easily extrapolated
to a statically scheduled superscalar.
Figure 3. 15 summarizes the basic approaches to multiple issue and their dis-
tinguishing characteristics and shows processors that use each approach.
The Basic VLIW Approach
VLIWs use multiple, independent functional units. Rather than attempting to
issue multiple, independent instructions to the units, a VLIW packages the multi-
ple operations into one very long instruction, or requires that the instructions in
the issue packet satisfy the same constraints. Since there is no fundamental
difference in the two approaches, we will just assume that multiple operations are
placed in one instruction, as in the original VLIW approach.
Since the advantage of a VLIW increases as the maximum issue rate grows,
we focus on a wider issue processor. Indeed, for simple two-issue processors, the
overhead of a superscalar is probably minimal. Many designers would probably
argue that a four-issue processor has manageable overhead, but as we will see
later in this chapter, the growth in overhead is a major factor limiting wider issue
processors.
3.7 Exploiting ILP Using Multiple Issue and Static Scheduling ■ 195
For now, we will rely on loop unrolling to generate long, straight-line code
sequences, so that we can use local scheduling to build up VLIW instructions and
focus on how well these processors operate.
Example Suppose we have a VLIW that could issue two memory references, two FP oper-
ations, and one integer operation or branch in every clock cycle. Show an
unrolled version of the loop x[i] = x[i] + s (see page 158 for the MIPS code)
for such a processor. Unroll as many times as necessary to eliminate any stalls.
Ignore delayed branches.
Answer Figure 3.16 shows the code. The loop has been unrolled to make seven copies of
the body, which eliminates all stalls (i.e., completely empty issue cycles), and
runs in 9 cycles. This code yields a running rate of seven results in 9 cycles, or
1.29 cycles per result, nearly twice as fast as the two-issue superscalar of Section
3.2 that used unrolled and scheduled code.
For the original VLIW model, there were both technical and logistical prob-
lems that make the approach less efficient. The technical problems are the
increase in code size and the limitations of lockstep operation. Two different
elements combine to increase code size substantially for a VLIW. First, generat-
ing enough operations in a straight-line code fragment requires ambitiously
unrolling loops (as in earlier examples), thereby increasing code size. Second,
whenever instructions are not full, the unused functional units translate to wasted
bits in the instruction encoding. In Appendix H, we examine software scheduling
Memory reference 1 Memory reference 2
FP
operation 1
FP
operation 2 Integer operation/branch L.D F0,0(R1) L.D F6,-8(R1) L.D F10,-16(R1) L.D F14,-24(R1) L.D F18,-32(R1) L.D F22,-40(R1) ADD.D F4,F0,F2 ADD.D F8,F6,F L.D F26,-48(R1) ADD.D F12,F10,F2 ADD.D F16,F14,F ADD.D F20,F18,F2 ADD.D F24,F22,F S.D F4,0(R1) S.D F8,-8(R1) ADD.D F28,F26,F S.D F12,-16(R1) S.D F16,-24(R1) DADDUI R1,R1,#- S.D F20,24(R1) S.D F24,16(R1) S.D F28,8(R1) BNE R1,R2,Loop Figure 3.16 VLIW instructions that occupy the inner loop and replace the unrolled sequence. This code takes 9 cycles assuming no branch delay; normally the branch delay would also need to be scheduled. The issue rate is 23 oper- ations in 9 clock cycles, or 2.5 operations per cycle. The efficiency, the percentage of available slots that contained an operation, is about 60%. To achieve this issue rate requires a larger number of registers than MIPS would normally use in this loop. The VLIW code sequence above requires at least eight FP registers, while the same code sequence for the base MIPS processor can use as few as two FP registers or as many as five when unrolled and scheduled.
196 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
approaches, such as software pipelining, that can achieve the benefits of unroll-
ing without as much code expansion.
To combat this code size increase, clever encodings are sometimes used. For
example, there may be only one large immediate field for use by any functional
unit. Another technique is to compress the instructions in main memory and
expand them when they are read into the cache or are decoded. In Appendix H,
we show other techniques, as well as document the significant code expansion
seen on IA-64.
Early VLIWs operated in lockstep; there was no hazard-detection hardware at
all. This structure dictated that a stall in any functional unit pipeline must cause
the entire processor to stall, since all the functional units must be kept synchro-
nized. Although a compiler may be able to schedule the deterministic functional
units to prevent stalls, predicting which data accesses will encounter a cache stall
and scheduling them are very difficult. Hence, caches needed to be blocking and
to cause all the functional units to stall. As the issue rate and number of memory
references becomes large, this synchronization restriction becomes unacceptable.
In more recent processors, the functional units operate more independently, and
the compiler is used to avoid hazards at issue time, while hardware checks allow
for unsynchronized execution once instructions are issued.
Binary code compatibility has also been a major logistical problem for
VLIWs. In a strict VLIW approach, the code sequence makes use of both the
instruction set definition and the detailed pipeline structure, including both func-
tional units and their latencies. Thus, different numbers of functional units and
unit latencies require different versions of the code. This requirement makes
migrating between successive implementations, or between implementations
with different issue widths, more difficult than it is for a superscalar design. Of
course, obtaining improved performance from a new superscalar design may
require recompilation. Nonetheless, the ability to run old binary files is a practi-
cal advantage for the superscalar approach.
The EPIC approach, of which the IA-64 architecture is the primary example,
provides solutions to many of the problems encountered in early VLIW designs,
including extensions for more aggressive software speculation and methods to
overcome the limitation of hardware dependence while preserving binary com-
patibility.
The major challenge for all multiple-issue processors is to try to exploit large
amounts of ILP. When the parallelism comes from unrolling simple loops in FP
programs, the original loop probably could have been run efficiently on a vector
processor (described in the next chapter). It is not clear that a multiple-issue pro-
cessor is preferred over a vector processor for such applications; the costs are
similar, and the vector processor is typically the same speed or faster. The poten-
tial advantages of a multiple-issue processor versus a vector processor are their
ability to extract some parallelism from less structured code and their ability to
easily cache all forms of data. For these reasons multiple-issue approaches have
become the primary method for taking advantage of instruction-level parallelism,
and vectors have become primarily an extension to these processors.
198 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
shows the issue logic for one case: issuing a load followed by a dependent FP
operation. The logic is based on that in Figure 3.14 on page 191, but represents
only one case. In a modern superscalar, every possible combination of dependent
instructions that is allowed to issue in the same clock cycle must be considered.
Since the number of possibilities climbs as the square of the number of instruc-
tions that can be issued in a clock, the issue step is a likely bottleneck for
attempts to go beyond four instructions per clock.
We can generalize the detail of Figure 3.18 to describe the basic strategy for
updating the issue logic and the reservation tables in a dynamically scheduled
superscalar with up to n issues per clock as follows:
Figure 3.17 The basic organization of a multiple issue processor with speculation. In this case, the organization could allow a FP multiply, FP add, integer, and load/store to all issues simultaneously (assuming one issue per clock per functional unit). Note that several datapaths must be widened to support multiple issues: the CDB, the operand buses, and, critically, the instruction issue logic, which is not shown in this figure. The last is a difficult problem, as we discuss in the text. From instruction unit Integer and FP registers Reservation stations FP adders FP multipliers 3 2 1 2 1 Common data bus (CDB) Operation bus Operand Address unit^ buses Load buffers Memory unit Reg # Data Reorder buffer Store data (^) Address Load data Store address Floating-point operations Load/store operations Instruction queue Integer unit 2 1 © Hennessy, John L.; Patterson, David A., Oct 07, 2011, Computer Architecture : A Quantitative Approach Morgan Kaufmann, Burlington, ISBN: 9780123838735
3.8 Exploiting ILP Using Dynamic Scheduling, Multiple Issue, and Speculation ■ 199
1. Assign a reservation station and a reorder buffer for every instruction that
might be issued in the next issue bundle. This assignment can be done before
the instruction types are known, by simply preallocating the reorder buffer
entries sequentially to the instructions in the packet using n available reorder
buffer entries and by ensuring that enough reservation stations are available
to issue the whole bundle, independent of what it contains. By limiting the
number of instructions of a given class (say, one FP, one integer, one load,
Action or bookkeeping Comments if (RegisterStat[rs1].Busy)/in-flight instr. writes rs/ {h ← RegisterStat[rs1].Reorder; if (ROB[h].Ready)/* Instr completed already / {RS[r1].Vj ← ROB[h].Value; RS[r1].Qj ← 0;} else {RS[r1].Qj ← h;} / wait for instruction / } else {RS[r1].Vj ← Regs[rs]; RS[r1].Qj ← 0;}; RS[r1].Busy ← yes; RS[r1].Dest ← b1; ROB[b1].Instruction ← Load; ROB[b1].Dest ← rd1; ROB[b1].Ready ← no; RS[r].A ← imm1; RegisterStat[rt1].Reorder ← b1; RegisterStat[rt1].Busy ← yes; ROB[b1].Dest ← rt1; Updating the reservation tables for the load instruction, which has a single source operand. Because this is the first instruction in this issue bundle, it looks no different than what would normally happen for a load. RS[r2].Qj ← b1;} / wait for load instruction / Since we know that the first operand of the FP operation is from the load, this step simply updates the reservation station to point to the load. Notice that the dependence must be analyzed on the fly and the ROB entries must be allocated during this issue step so that the reservation tables can be correctly updated. if (RegisterStat[rt2].Busy) /in-flight instr writes rt/ {h ← RegisterStat[rt2].Reorder; if (ROB[h].Ready)/ Instr completed already / {RS[r2].Vk ← ROB[h].Value; RS[r2].Qk ← 0;} else {RS[r2].Qk ← h;} / wait for instruction */ } else {RS[r2].Vk ← Regs[rt2]; RS[r2].Qk ← 0;}; RegisterStat[rd2].Reorder ← b2; RegisterStat[rd2].Busy ← yes; ROB[b2].Dest ← rd2; Since we assumed that the second operand of the FP instruction was from a prior issue bundle, this step looks like it would in the single-issue case. Of course, if this instruction was dependent on something in the same issue bundle the tables would need to be updated using the assigned reservation buffer. RS[r2].Busy ← yes; RS[r2].Dest ← b2; ROB[b2].Instruction ← FP operation; ROB[b2].Dest ← rd2; ROB[b2].Ready ← no; This section simply updates the tables for the FP operation, and is independent of the load. Of course, if further instructions in this issue bundle depended on the FP operation (as could happen with a four-issue superscalar), the updates to the reservation tables for those instructions would be effected by this instruction. Figure 3.18 The issue steps for a pair of dependent instructions (called 1 and 2) where instruction 1 is FP load and instruction 2 is an FP operation whose first operand is the result of the load instruction; r1 and r2 are the assigned reservation stations for the instructions; and b1 and b2 are the assigned reorder buffer entries. For the issuing instructions, rd1 and rd2 are the destinations; rs1, rs2, and rt2 are the sources (the load only has one source); r1 and r2 are the reservation stations allocated; and b1 and b2 are the assigned ROB entries. RS is the res- ervation station data structure. RegisterStat is the register data structure, Regs represents the actual registers, and ROB is the reorder buffer data structure. Notice that we need to have assigned reorder buffer entries for this logic to operate properly and recall that all these updates happen in a single clock cycle in parallel, not sequentially!
3.8 Exploiting ILP Using Dynamic Scheduling, Multiple Issue, and Speculation ■ 201
the speculative processor executes in clock cycle 13, while it executes in clock
cycle 19 on the nonspeculative pipeline. Because the completion rate on the non-
speculative pipeline is falling behind the issue rate rapidly, the nonspeculative
pipeline will stall when a few more iterations are issued. The performance of the
nonspeculative processor could be improved by allowing load instructions to
complete effective address calculation before a branch is decided, but unless
speculative memory accesses are allowed, this improvement will gain only 1
clock per iteration.
This example clearly shows how speculation can be advantageous when there
are data-dependent branches, which otherwise would limit performance. This
advantage depends, however, on accurate branch prediction. Incorrect specula-
tion does not improve performance; in fact, it typically harms performance and,
as we shall see, dramatically lowers energy efficiency.
Iteration number Instructions Issues at clock cycle number Executes at clock cycle number Memory access at clock cycle number Write CDB at clock cycle number Comment 1 LD R2,0(R1) 1 2 3 4 First issue 1 DADDIU R2,R2,#1 1 5 6 Wait for LW 1 SD R2,0(R1) 2 3 7 Wait for DADDIU 1 DADDIU R1,R1,#8 2 3 4 Execute directly 1 BNE R2,R3,LOOP 3 7 Wait for DADDIU 2 LD R2,0(R1) 4 8 9 10 Wait for BNE 2 DADDIU R2,R2,#1 4 11 12 Wait for LW 2 SD R2,0(R1) 5 9 13 Wait for DADDIU 2 DADDIU R1,R1,#8 5 8 9 Wait for BNE 2 BNE R2,R3,LOOP 6 13 Wait for DADDIU 3 LD R2,0(R1) 7 14 15 16 Wait for BNE 3 DADDIU R2,R2,#1 7 17 18 Wait for LW 3 SD R2,0(R1) 8 15 19 Wait for DADDIU 3 DADDIU R1,R1,#8 8 14 15 Wait for BNE 3 BNE R2,R3,LOOP 9 19 Wait for DADDIU Figure 3.19 The time of issue, execution, and writing result for a dual-issue version of our pipeline without speculation. Note that the LD following the BNE cannot start execution earlier because it must wait until the branch outcome is determined. This type of program, with data-dependent branches that cannot be resolved earlier, shows the strength of speculation. Separate functional units for address calculation, ALU operations, and branch-condition evaluation allow multiple instructions to execute in the same cycle. Figure 3.20 shows this example with speculation.
202 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
In a high-performance pipeline, especially one with multiple issues, predicting
branches well is not enough; we actually have to be able to deliver a high-
bandwidth instruction stream. In recent multiple-issue processors, this has meant
delivering 4 to 8 instructions every clock cycle. We look at methods for increas-
ing instruction delivery bandwidth first. We then turn to a set of key issues in
implementing advanced speculation techniques, including the use of register
renaming versus reorder buffers, the aggressiveness of speculation, and a tech-
nique called value prediction , which attempts to predict the result of a computa-
tion and which could further enhance ILP.
Increasing Instruction Fetch Bandwidth
A multiple-issue processor will require that the average number of instructions
fetched every clock cycle be at least as large as the average throughput. Of
course, fetching these instructions requires wide enough paths to the instruction
cache, but the most difficult aspect is handling branches. In this section, we look
Iteration number Instructions Issues at clock number Executes at clock number Read access at clock number Write CDB at clock number Commits at clock number Comment 1 LD R2,0(R1) 1 2 3 4 5 First issue 1 DADDIU R2,R2,#1 1 5 6 7 Wait for LW 1 SD R2,0(R1) 2 3 7 Wait for DADDIU 1 DADDIU R1,R1,#8 2 3 4 8 Commit in order 1 BNE R2,R3,LOOP 3 7 8 Wait for DADDIU 2 LD R2,0(R1) 4 5 6 7 9 No execute delay 2 DADDIU R2,R2,#1 4 8 9 10 Wait for LW 2 SD R2,0(R1) 5 6 10 Wait for DADDIU 2 DADDIU R1,R1,#8 5 6 7 11 Commit in order 2 BNE R2,R3,LOOP 6 10 11 Wait for DADDIU 3 LD R2,0(R1) 7 8 9 10 12 Earliest possible 3 DADDIU R2,R2,#1 7 11 12 13 Wait for LW 3 SD R2,0(R1) 8 9 13 Wait for DADDIU 3 DADDIU R1,R1,#8 8 9 10 14 Executes earlier 3 BNE R2,R3,LOOP 9 13 14 Wait for DADDIU Figure 3.20 The time of issue, execution, and writing result for a dual-issue version of our pipeline with specula- tion. Note that the LD following the BNE can start execution early because it is speculative.
3.9 Advanced Techniques for Instruction Delivery and
Speculation
204 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
If a matching entry is found in the branch-target buffer, fetching begins
immediately at the predicted PC. Note that unlike a branch-prediction buffer, the
predictive entry must be matched to this instruction because the predicted PC
will be sent out before it is known whether this instruction is even a branch. If the
processor did not check whether the entry matched this PC, then the wrong PC
would be sent out for instructions that were not branches, resulting in worse
performance. We only need to store the predicted-taken branches in the branch-
target buffer, since an untaken branch should simply fetch the next sequential
instruction, as if it were not a branch.
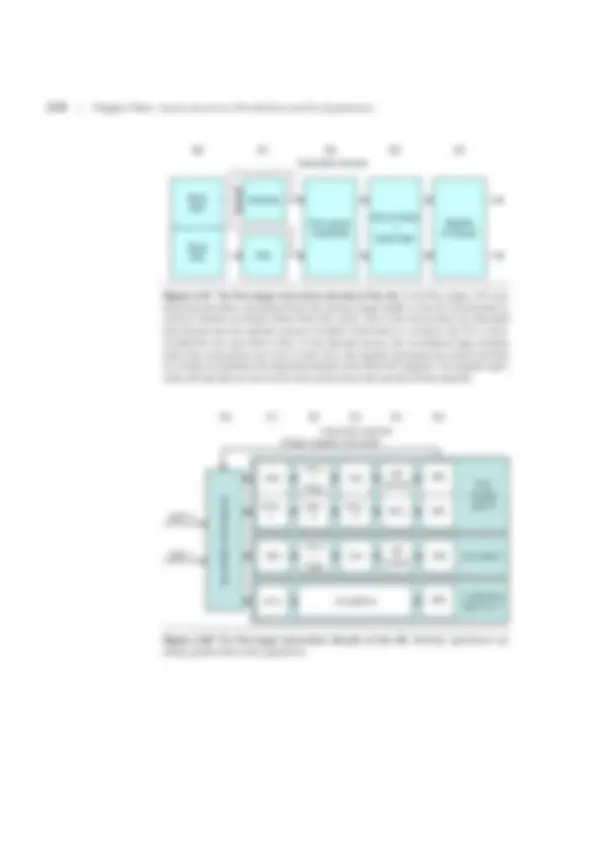
Figure 3.22 shows the steps when using a branch-target buffer for a simple
five-stage pipeline. From this figure we can see that there will be no branch delay
Figure 3.22 The steps involved in handling an instruction with a branch-target buffer. IF ID EX Send PC to memory and branch-target buffer Entry found in branch-target buffer? No No Normal instruction execution Yes Send out predicted Is PC instruction a taken branch? Taken branch? Enter branch instruction address and next PC into branch- target buffer Mispredicted branch, kill fetched instruction; restart fetch at other target; delete entry from target buffer Branch correctly predicted; continue execution with no stalls Yes No Yes
3.9 Advanced Techniques for Instruction Delivery and Speculation ■ 205
if a branch-prediction entry is found in the buffer and the prediction is correct.
Otherwise, there will be a penalty of at least two clock cycles. Dealing with the
mispredictions and misses is a significant challenge, since we typically will have
to halt instruction fetch while we rewrite the buffer entry. Thus, we would like to
make this process fast to minimize the penalty.
To evaluate how well a branch-target buffer works, we first must determine
the penalties in all possible cases. Figure 3.23 contains this information for a sim-
ple five-stage pipeline.
Example Determine the total branch penalty for a branch-target buffer assuming the pen-
alty cycles for individual mispredictions from Figure 3.23. Make the following
assumptions about the prediction accuracy and hit rate:
■ Prediction accuracy is 90% (for instructions in the buffer).
■ Hit rate in the buffer is 90% (for branches predicted taken).
Answer We compute the penalty by looking at the probability of two events: the branch is
predicted taken but ends up being not taken, and the branch is taken but is not
found in the buffer. Both carry a penalty of two cycles.
This penalty compares with a branch penalty for delayed branches, which we
evaluate in Appendix C, of about 0.5 clock cycles per branch. Remember,
though, that the improvement from dynamic branch prediction will grow as the
Instruction in buffer Prediction Actual branch Penalty cycles Yes Taken Taken 0 Yes Taken Not taken 2 No Taken 2 No Not taken 0 Figure 3.23 Penalties for all possible combinations of whether the branch is in the buffer and what it actually does, assuming we store only taken branches in the buffer. There is no branch penalty if everything is correctly predicted and the branch is found in the target buffer. If the branch is not correctly predicted, the penalty is equal to one clock cycle to update the buffer with the correct information (during which an instruction cannot be fetched) and one clock cycle, if needed, to restart fetching the next correct instruction for the branch. If the branch is not found and taken, a two-cycle penalty is encountered, during which time the buffer is updated. Probability (branch in buffer, but actually not taken) = Percent buffer hit rate ×Percent incorrect predictions = 90% × 10%=0. Probability (branch not in buffer, but actually taken) = 10% Branch penalty = ( 0.09 +0.10) × 2 Branch penalty = 0.
3.9 Advanced Techniques for Instruction Delivery and Speculation ■ 207
ILP in Section 3.10. Both the Intel Core processors and the AMD Phenom proces-
sors have return address predictors.
Integrated Instruction Fetch Units
To meet the demands of multiple-issue processors, many recent designers have
chosen to implement an integrated instruction fetch unit as a separate autono-
mous unit that feeds instructions to the rest of the pipeline. Essentially, this
amounts to recognizing that characterizing instruction fetch as a simple single
pipe stage given the complexities of multiple issue is no longer valid.
Instead, recent designs have used an integrated instruction fetch unit that inte-
grates several functions:
1. Integrated branch prediction —The branch predictor becomes part of the
instruction fetch unit and is constantly predicting branches, so as to drive the
fetch pipeline.
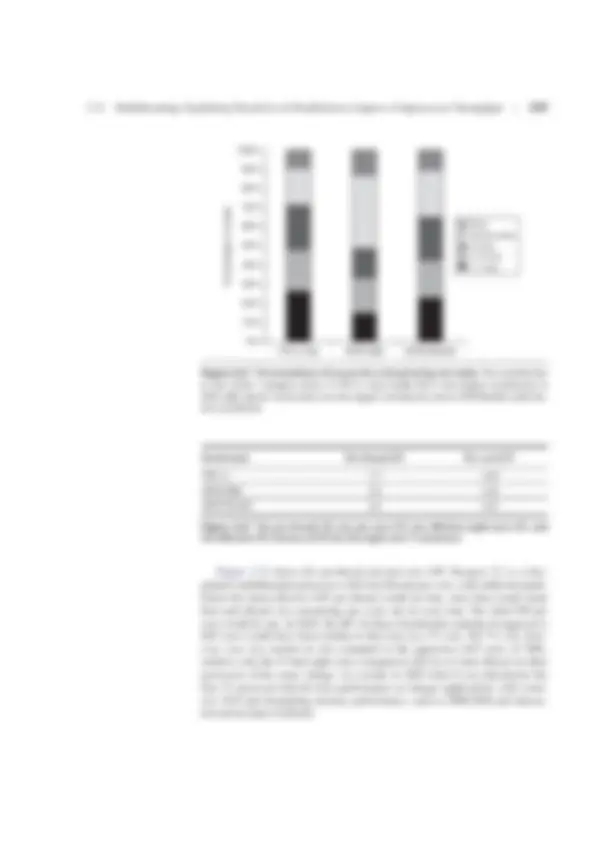
Figure 3.24 Prediction accuracy for a return address buffer operated as a stack on a number of SPEC CPU95 benchmarks. The accuracy is the fraction of return addresses predicted correctly. A buffer of 0 entries implies that the standard branch prediction is used. Since call depths are typically not large, with some exceptions, a modest buffer works well. These data come from Skadron et al. [1999] and use a fix-up mechanism to prevent corruption of the cached return addresses. Misprediction frequency 70% 60% 50% 40% 30% 20% 0 10% 0% 1 2 4 Return address buffer entries 8 Go m88ksim cc Compress Xlisp Ijpeg Perl Vortex 16
208 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
2. Instruction prefetch —To deliver multiple instructions per clock, the instruc-
tion fetch unit will likely need to fetch ahead. The unit autonomously man-
ages the prefetching of instructions (see Chapter 2 for a discussion of
techniques for doing this), integrating it with branch prediction.
3. Instruction memory access and buffering —When fetching multiple instruc-
tions per cycle a variety of complexities are encountered, including the diffi-
culty that fetching multiple instructions may require accessing multiple cache
lines. The instruction fetch unit encapsulates this complexity, using prefetch
to try to hide the cost of crossing cache blocks. The instruction fetch unit also
provides buffering, essentially acting as an on-demand unit to provide
instructions to the issue stage as needed and in the quantity needed.
Virtually all high-end processors now use a separate instruction fetch unit con-
nected to the rest of the pipeline by a buffer containing pending instructions.
Speculation: Implementation Issues and Extensions
In this section we explore four issues that involve the design trade-offs in specu-
lation, starting with the use of register renaming, the approach that is often used
instead of a reorder buffer. We then discuss one important possible extension to
speculation on control flow: an idea called value prediction.
Speculation Support: Register Renaming versus Reorder Buffers
One alternative to the use of a reorder buffer (ROB) is the explicit use of a larger
physical set of registers combined with register renaming. This approach builds
on the concept of renaming used in Tomasulo’s algorithm and extends it. In
Tomasulo’s algorithm, the values of the architecturally visible registers (R0, …,
R31 and F0, …, F31) are contained, at any point in execution, in some combina-
tion of the register set and the reservation stations. With the addition of specula-
tion, register values may also temporarily reside in the ROB. In either case, if the
processor does not issue new instructions for a period of time, all existing
instructions will commit, and the register values will appear in the register file,
which directly corresponds to the architecturally visible registers.
In the register-renaming approach, an extended set of physical registers is
used to hold both the architecturally visible registers as well as temporary values.
Thus, the extended registers replace most of the function of the ROB and the res-
ervation stations; only a queue to ensure that instructions complete in order is
needed. During instruction issue, a renaming process maps the names of architec-
tural registers to physical register numbers in the extended register set, allocating
a new unused register for the destination. WAW and WAR hazards are avoided
by renaming of the destination register, and speculation recovery is handled
because a physical register holding an instruction destination does not become
the architectural register until the instruction commits. The renaming map is a
simple data structure that supplies the physical register number of the register
210 ■ Chapter Three Instruction-Level Parallelism and Its Exploitation
Both register renaming and reorder buffers continue to be used in high-end
processors, which now feature the ability to have as many as 40 or 50 instructions
(including loads and stores waiting on the cache) in flight. Whether renaming or
a reorder buffer is used, the key complexity bottleneck for a dynamically sched-
ule superscalar remains issuing bundles of instructions with dependences within
the bundle. In particular, dependent instructions in an issue bundle must be issued
with the assigned virtual registers of the instructions on which they depend.
A strategy for instruction issue with register renaming similar to that used for
multiple issue with reorder buffers (see page 198) can be deployed, as follows:
1. The issue logic pre-reserves enough physical registers for the entire issue
bundle (say, four registers for a four-instruction bundle with at most one reg-
ister result per instruction).
2. The issue logic determines what dependences exist within the bundle. If a
dependence does not exist within the bundle, the register renaming structure
is used to determine the physical register that holds, or will hold, the result on
which instruction depends. When no dependence exists within the bundle the
result is from an earlier issue bundle, and the register renaming table will
have the correct register number.
3. If an instruction depends on an instruction that is earlier in the bundle, then
the pre-reserved physical register in which the result will be placed is used to
update the information for the issuing instruction.
Note that just as in the reorder buffer case, the issue logic must both determine
dependences within the bundle and update the renaming tables in a single clock,
and, as before, the complexity of doing this for a larger number of instructions
per clock becomes a chief limitation in the issue width.
How Much to Speculate
One of the significant advantages of speculation is its ability to uncover events
that would otherwise stall the pipeline early, such as cache misses. This potential
advantage, however, comes with a significant potential disadvantage. Specula-
tion is not free. It takes time and energy, and the recovery of incorrect speculation
further reduces performance. In addition, to support the higher instruction execu-
tion rate needed to benefit from speculation, the processor must have additional
resources, which take silicon area and power. Finally, if speculation causes an
exceptional event to occur, such as a cache or translation lookaside buffer (TLB)
miss, the potential for significant performance loss increases, if that event would
not have occurred without speculation.
To maintain most of the advantage, while minimizing the disadvantages,
most pipelines with speculation will allow only low-cost exceptional events
(such as a first-level cache miss) to be handled in speculative mode. If an
expensive exceptional event occurs, such as a second-level cache miss or a TLB
miss, the processor will wait until the instruction causing the event is no longer
3.9 Advanced Techniques for Instruction Delivery and Speculation ■ 211
speculative before handling the event. Although this may slightly degrade the
performance of some programs, it avoids significant performance losses in
others, especially those that suffer from a high frequency of such events coupled
with less-than-excellent branch prediction.
In the 1990s, the potential downsides of speculation were less obvious. As
processors have evolved, the real costs of speculation have become more appar-
ent, and the limitations of wider issue and speculation have been obvious. We
return to this issue shortly.
Speculating through Multiple Branches
In the examples we have considered in this chapter, it has been possible to
resolve a branch before having to speculate on another. Three different situations
can benefit from speculating on multiple branches simultaneously: (1) a very
high branch frequency, (2) significant clustering of branches, and (3) long delays
in functional units. In the first two cases, achieving high performance may mean
that multiple branches are speculated, and it may even mean handling more than
one branch per clock. Database programs, and other less structured integer
computations, often exhibit these properties, making speculation on multiple
branches important. Likewise, long delays in functional units can raise the impor-
tance of speculating on multiple branches as a way to avoid stalls from the longer
pipeline delays.
Speculating on multiple branches slightly complicates the process of specula-
tion recovery but is straightforward otherwise. As of 2011, no processor has yet
combined full speculation with resolving multiple branches per cycle, and it is
unlikely that the costs of doing so would be justified in terms of performance ver-
sus complexity and power.
Speculation and the Challenge of Energy Efficiency
What is the impact of speculation on energy efficiency? At first glance, one
might argue that using speculation always decreases energy efficiency, since
whenever speculation is wrong it consumes excess energy in two ways:
1. The instructions that were speculated and whose results were not needed gen-
erated excess work for the processor, wasting energy.
2. Undoing the speculation and restoring the state of the processor to continue
execution at the appropriate address consumes additional energy that would
not be needed without speculation.
Certainly, speculation will raise the power consumption and, if we could control
speculation, it would be possible to measure the cost (or at least the dynamic
power cost). But, if speculation lowers the execution time by more than it
increases the average power consumption, then the total energy consumed may
be less.