Download Biochemistry: Mod 1 Study Guide Key Notes and more Study Guides, Projects, Research Biochemistry in PDF only on Docsity!
Biochemistry: Mod 1 Study
Guide Key Notes
DNA = phosphate + deoxyribose sugar + A/T/C/G o Contains two strands. The strands are antiparallel (opposite each other). o 5’ → 3’ 3’ ← 5’ RNA = phosphate + ribose sugar + A/U/C/G o Single strand, can fold back onto itself and form pairs between itself (stem loop).‐ Each nucleic acid is made up of polymers (many monomers) that are called nucleotides. o Nucleotides contain one or more phosphates, a five carbon‐ sugar, and a nitrogen base. o Nucleotides are always made in the 5’ to 3’ direction. o 5 is always the beginning of the strand, 3 is the end where nucleotides are added. DNA organization: DNA is wrapped around proteins called histones → nucleosome → chromatin fiber→ chromosomes Steps to the central dogma: o Coding DNA → template DNA → mRNA → tRNA (amino acid) o DNA → transcribed to mRNA → translated to protein o Each step is complementary (opposite) to the previous step, but if you skip a step it will be identical to the previous step. o Example 1. Coding DNA strand 5’ AAA TTT GGG CCC 3’ 2. Template DNA strand 3’ TTT AAA CCC GGG 5’ 3. mRNA 5’ AAA UUU GGG CCC 3’ 4. tRNA Lys Phe Gly Pro Pairing: o DNA: A → T o RNA: A → U DNA replication: o Because DNA is a double helix, one strand can be separated and serve as a template for synthesis of
a new strand. o Semi conservative‐ : each copy of DNA contains a template strand and a new strand. o Steps of replication: o 1. The DNA must be separated, creating a replication fork. This is done by helicase. o 2. Primase attaches an RNA primer , where the replication is to start. o 3. DNA polymerase adds bases to the remaining of the strand until it reaches a stop codon. This is done in fragments, called okazaki fragments. If an error is detected, it removes the nucleotides and replaces them with correct ones, known as exonuclease. o Exonuclease removes all of the RNA primers, and DNA polymerase fills in those gaps. o DNA ligase seals the two strands forming a double helix. DNA → transcribed → mRNA → translated → protein Transcription occurs in the nucleus: o Initiation: RNA polymerase binds to a sequence of DNA called the promoter , found near the beginning of a gene. Each gene has its own promoter. Once bound, RNA polymerase separates the DNA strands, providing the single stranded template needed‐ for transcription.
Translation occurs in the cytoplasm: o Initiation: The ribosome assembles around the mRNA to be read and tRNA brings in its perspective protein, decoding 3 bases at a time, beginning with the start codon, AUG. o These 3 base pairs of mRNA are called codons. The mRNA base pairs are complementary to the base pairs of the tRNA, called anticodons. o Elongation : The amino acid chain gets longer. The mRNA is read one codon at a time, and the amino acid matching each codon is added to a growing protein chain. When the complementary pairs are formed, they are added to the protein chain by peptide bonds, the result is polypeptides. o Termination: The finished polypeptide chain is released when a stop codon (UAG, UAA, or UGA) enters the ribosome. Gene regulation o Promotor sites : can be turned off or on, enabling or disabling a gene from being replicated. o Alternative splicing : Exons are used to code for protein, introns are clipped out. The order of exons can determine different mature mRNA strands which result in different proteins. o Epigenetics : involves packaging of DNA. DNA is round around histones. These packages are called nucleosomes. How tightly packed they are determines whether or not the gene is on or off.
o Loosely packed = transcription possible. o Tightly packed = transcription impeded. o Modifications determine how tightly/loosely packed they are. Many of these modifications are determined by environment/diet. Mutations‐ Mutations originate at the DNA level, but show their effects at the protein level. o Point mutations‐ when one of the DNA bases (nucleotides) are replaced with another, results in a different protein o Example: Coding: 5’ AAA TTT GGG CCC 3’ = Lys Mutation: 5’ TAA TTT GGG CCC 3’ = stop codon o Missense mutations ‐ any mutation that causes a change in amino acid o Nonsense mutations ‐ leads to a stop codon “stop the nonsense” o Silent mutations ‐ doesn’t affect the protein at all, the codon results in the same protein o Frameshift mutations‐ adds one base into the protein sequence, but changes the final protein amino acids by causing a shift. Insertion mutation ‐ can change the entire read of the protein Deletion mutation ‐ can change the entire read of the protein Conservative mutations ‐ where the resulting amino acid is in the same type as the original Non conservative‐ mutation ‐ amino acid is a different type than the original
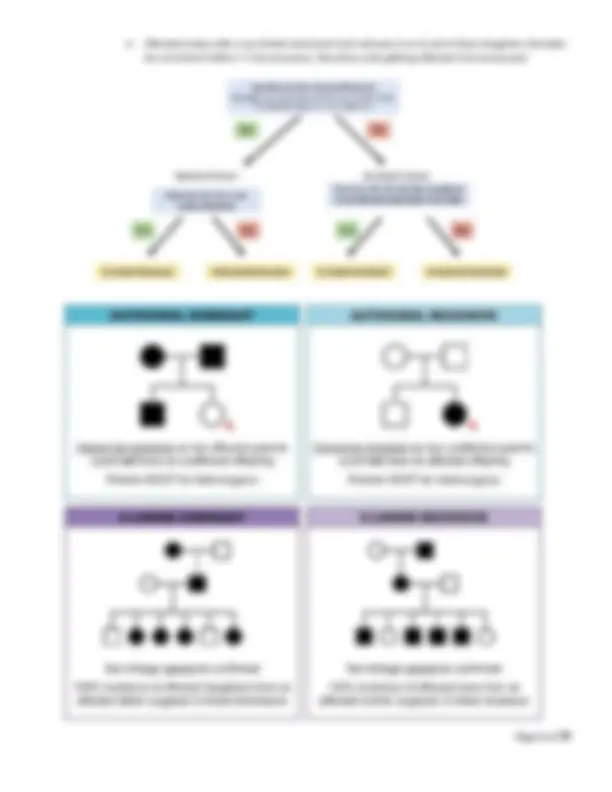
Homologous recombination ‐a sister chromosome is used as a guide to recombine the strands by copying the chromosome, but this doesn’t always work. Must be done after DNA replication. Nonhomologous end joining ‐ if no sister DNA to copy (ie before DNA replication) the non damaged sections are joined together and the damaged DNA is lost. Last‐ resort method d/t high risk of mutations. Inheritance o 1 22‐ are autosomal chromosomes o If a mutation is on an autosomal chromosome (1 22)‐ then there is no bias towards males or females. o Sex chromosomes: o Females Xx o Males Xy o X linked mutation is bias because females have Xx and males are Xy. o Allele : a copy of a gene o Genotype : complete set of genes, the genetic makeup of an individual. o Phenotype: all the observable characteristics or traits of an individual, including ones that are not easily seen, such as blood type or color blindness o The genotype (pair of genes) decide the phenotype (observable characteristics) of an individual. o Heterozygous: one allele is dominate while the other is recessive. The dominant allele is observable in the phenotype while the recessive allele is not. (Aa) o Homozygous: two identical alleles (AA or aa) o Dominant: an allele that always expresses its phenotype, even in the presence of a recessive allele, represented by a capital letter. o Recessive: an allele that is only expressed in the phenotype when both alleles of a gene are recessive. Represented by a lower case letter.‐ Determining pedigrees o Females are indicated by circles; males are indicated by squares. o Unaffected individuals are indicated by open shapes; affected individuals are indicated by filled shapes. o Recessive vs Dominant o If two unaffected parents have an affected child, they are carrier parents. o Carrier parents = recessive trait o No carrier parents = dominant trait o Autosomal vs Sex linked o Males and females affected equally = autosomal o Only males = sex linked o Autosomal dominant vs sex linked dominant
o Affected males with a sex linked dominant trait will pass it on to all of their daughters (females do not inherit father’s Y chromosome, therefore only getting affected X chromosome)
Visual representation with chromosomes Remember that chromosomes come in pairs of two, eliminate the answers that don’t include pairs. Carriers have one of each allele (Rr). If the person actually has the disease, they will have both alleles (rr) or (RR). Autosomal is chromosomes 1 22,‐ sex linked is chromsomes X and Y.
PCR and genetic testing ‐ DNA replication in a test tube o What is needed for PCR 1. Template DNA 2. Nucleotides (dNTP’s) 3. DNA polymerase 4. DNA primers o Stages of PCR: 1. Denaturation 95 degrees C Separates the template DNA strands to be able to copy each strand. 2. Annealing 50 degrees C DNA Primers that match the gene were looking for attach to the ends of the piece we want to copy. 3. Elongation 70 degrees C DNA polymerase adds on to the primers, building a copy strand. o Using PCR to detect mutation‐ must copy DNA multiple times (2^n, where n= # of cycles) Make primers that flank the mutation and sequence the product Use primers that stick to the mutation. If the mutation is present, it will stick, if it isn’t present, it won’t stick.
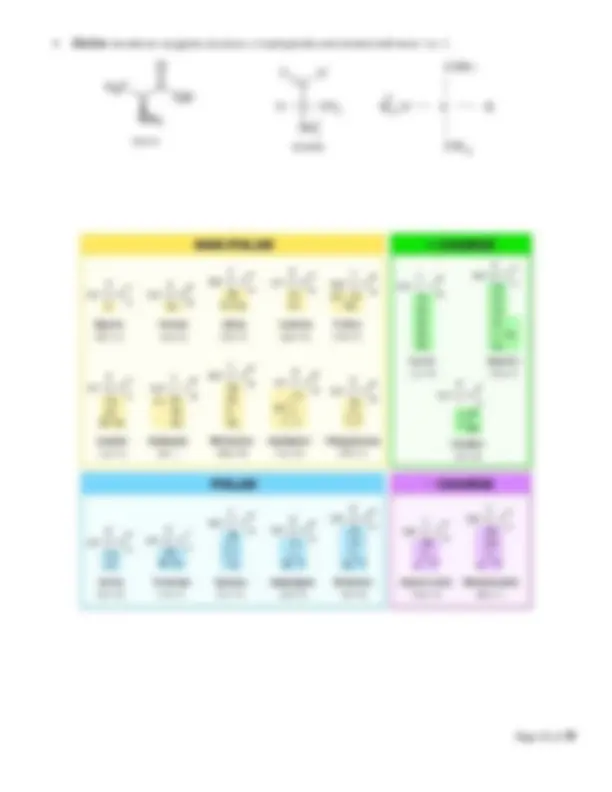
Amino acids Biochem Mod 2 o Amino acid back bone‐ same in all amino acids Central carbon (alpha carbon) ‐carbon in the center that holds the amino acid together as other groups bind to it. C H, CH‐ Amino group‐ contains nitrogen and hydrogen. NH2, NH3+ Carboxyl group‐ has two oxygens and one carbon, gives the amino acid its acid properties. COO ,‐ COOH o Side groups (R group) are different which effect how the amino acid acts, will classify them as charged, polar, or hydrophobic. To determine what their classification is, first look for: Charged amino acids ‐ R group will have ‐/+ which means negatively or positively charged. If charged, will take precedence. If not charged, look to see if its polar. Polar amino acids‐ will have SH, OH, NH at the end of the R group. If not polar, then the amino acid is non polar.‐ Non polar‐ amino acids‐ will have CH at the end of the R group. Hydrophobic amino acids ‐ will have several hydrogen molecules in the R group, each will end with an H atom. o Bonds Amino acids will have three types of bonds Charged amino acids make ionic bonds (only + with ‐) Polar amino acids will make hydrogen or disulfide bonds o OH and NH make hydrogen bonds o SH makes disulfide bond (the strongest type of bond, can only bond with itself so very few of them) o “OH look it’s a N orthern H emisphere/ S outhern H emisphere Polar Bear!” Non polar amino acids will make hydrophobic interactions o CH “ C an’t h ave water” (weakest bond, but many of them) Strongest to weakest: disulfide, ionic, hydrogen, hydrophobic What breaks the bonds ( denaturing ) Charged: pH and salt changes Polar: pH and salt changes, disulfide bonds have to be broken by reducing agents Non polar: broken by heat
Protein structure‐ chains of amino acids o Linking amino acids together‐ Forming peptide bonds (the backbone of an amino acid) Primary structure : chain of amino acids by peptide bonds , does not denature The carboxyl group and amino group of two amino acids bond together by using 2 hydrogens and one H2O. A water molecule is lost in this process, known as dehydration. o Amino group + carboxyl group Secondary structure: shaped that is formed when hydrogen bonds are added between carboxyl and amino groups. Forming of alpha helix and beta sheets within the backbone, held together by hydrogen bonds. Tertiary structure: three dimensional folding, the result of different secondary‐ structures interacting with one another via their R groups/side chains. These interactions include hydrophobic interactions, hydrogen bonds, ionic bonds, and disulfide bonds. Proteins can now function at this stage. Disruption of its hydrophobic state is the simplest way to denature. Quaternary structure : more than one amino acid/polypeptide/protein, held together by R groups/side chains. Not all proteins need this structure.
Protein folding o Chaperones help fold proteins o Can misfold, or take another shape ( conformation ), results in it being non functional‐ o Denature : environmental change that causes the protein to misfold or unfold by breaking side chain bonds/secondary structure, but does NOT break the primary structure o Degradation : breaking apart of the primary structure/peptide bonds by hydrolysis o Aggregation: proteins clump together abnormally due to hydrophobic interactions either by unfolding or mutation. o Hydrophobic interactions: when a protein is exposed by unfolding, causing its hydrophobic parts to be exposed to water o Misfolding of proteins leads to Alzheimer’s: Intracellular tangles and extracellular plaques (senile plaques) are caused by aggregated amyloid beta‐ fibers which accumulate in the brain. Connections between tau is lost leading to progressive neurodegeneration.
o Control by enzyme inhibition: Feedback inhibition – similar to the drug induced form of noncompetitive inhibition, when excess product is detected, the pathway is stopped by inhibition. The product at the end of the pathway binds to allosteric site on the first enzyme at the beginning of the pathway to stop the process. o Medical inhibition with drugs Competitive inhibition ‐ appears similar to the substrate, binds to the active site on the enzyme to prevent substrate from binding Can be overcome by adding additional substrate, if there’s too much substrate and not enough inhibition the substrate will win. Noncompetitive inhibition ‐ binds to the allosteric site (away from the active site) Changes shape of protein and therefore changes the active site, causing the substrate to not be able to fit into the enzyme.
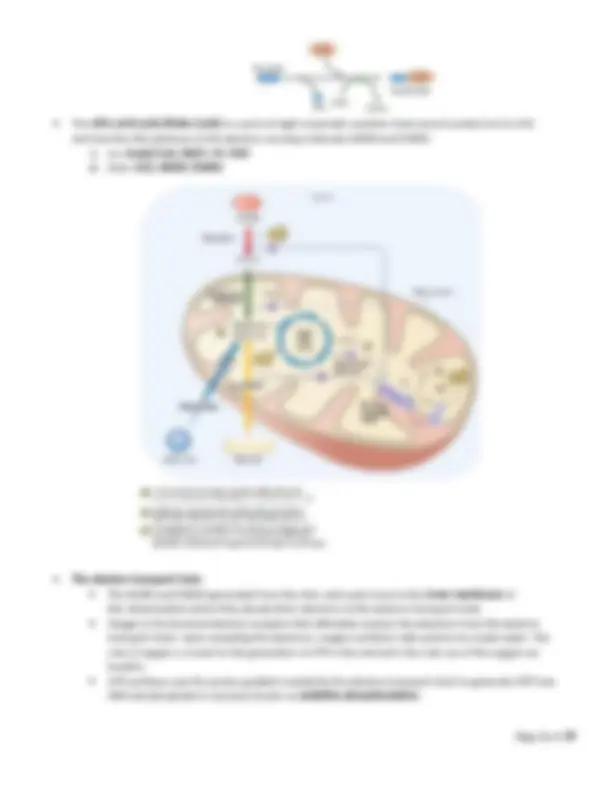
Myoglobin and Hemoglobin Biochem Mod 3 o Myoglobin‐ storage of oxygen, holds onto it 1 subunit, one polypeptide chain with tertiary structure , has only one heme therefore can only carry one oxygen molecule Can grab oxygen quickly, stores oxygen within muscles tightly (high affinity ) Is not affected by changes in pH Since it is stored in muscles, can be used to detect MI, rhabdomyolysis, etc. because it will be released when muscle is damaged. o Hemoglobin‐ transport of oxygen 4 subunits, quaternary structure Responsible for transport of oxygen from the lungs to the tissues, but not very good at grabbing oxygen (lower affinity). Heme ‐ iron, where O2 binds, has 4 so it can carry 4 oxygen molecules at one time Tense or "T" state Deoxygenated, heme is bent out of shape (dome shape), its 4 subunits are spread apart, low affinity. Low affinity = decreased ability to grab oxygen, will require more and more oxygen to bind Once one subunit binds to oxygen, the shape of all 4 subunits change to the relaxed state. This is called cooperativity , and it will bind to O2 faster now. Relaxed or "R" state Oxygenated, heme is flat and relaxed, subunits are closer together Has an increase in affinity so its ability to grab oxygen is better. Once one of the subunits grabs oxygen, the others tend to grab oxygen more quickly. Deoxygenated (tense state) Oxygenated (relaxed state)