Download Calculating Program - High Performance Computing - Lecture Slides and more Slides Computer Science in PDF only on Docsity!
High Performance Computing
Lecture 41
2
Example: MPI Pi Calculating Program
/Each process initializes, determines the communicator
size and its own rank
MPI_Init (&argc, &argv);
MPI_Comm_size ( MPI_COMM_WORLD, &numprocs);
MPI_Comm_rank ( MPI_COMM_WORLD, &myid);
/The master process (P
0
) takes input from the user
if (myid == 0){
printf(“Enter the number of intervals”);
scanf(“%d”, &n);
/The master process broadcasts the value of n
MPI_Bcast (&n,1,MPI_INT,0, MPI_COMM_WORLD);
4
Parallelizing a Program
Given a sequential program/algorithm, how to
go about producing a parallel version
Four steps in program parallelization
1. Decomposition
Identifying parallel tasks with large extent of possible parallel activity
2. Assignment
Grouping the tasks into processes with best load balancing
3. Orchestration
Reducing synchronization and communication costs
4. Mapping
Mapping of processes to processors
5
Example 1: Barrier Implementation
What is a barrier?
A process synchronization primitive
If n cooperating processes all include a call to the
barrier primitive …
Each entering process gets blocked on the barrier
call until all the n processes have reached the
barrier call
Thus, the n processes are synchronized on
departure from the barrier call
7
Linear Barrier Pseudocode
P
0 P 2
P
3
P
4
P
5
P
6
P
P 7
1 When a process reaches the barrier call, it sends a message to the master process
8
Linear Barrier Pseudocode
P
0 P 2
P
3
P
4
P
5
P
6
P
P 7
1 When the master process has received n messages, it sends a message to each of the participating processes to go ahead
10
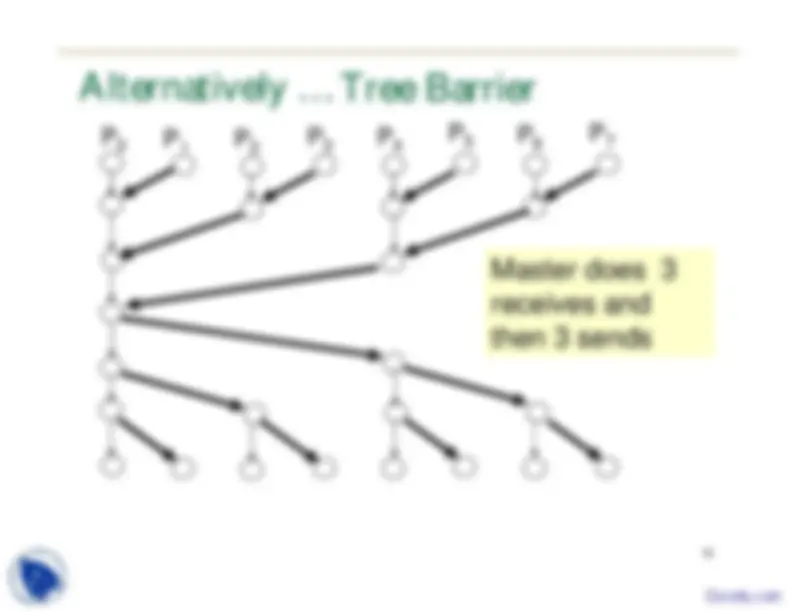
Alternatively …
P
0 P 2
P
3
P
4
P
5 P 6
P
P 7
1 Master does 3 receives and then 3 sends
Tree Barrier
11
Alternatively …
P
0 P 2
P
3
P
4
P
5 P 6
P
P 7
1
Butterfly Barrier
Each process does 3 send- receives Stage 1: P0-P1, P2-P3, P4-P5, P6-P Stage 2: P0-P2, P1-P3, P4-P6, P5-P Stage 3: P0-P4, P1-P5, P2-P6, P3-P
13
Some Decomposition Options
1. A parallel task for each element update
14
Option 1
16
Some Decomposition Options..
1. A parallel task for each element update
Maximum parallelism: n
2
Synchronization required: wait for left & top values
High synchronization cost
2. A parallel task for each anti-diagonal
17
Option 2 Anti-diagonals
19
Option 3 Blocks of rows
20
High Performance Computing
- Program execution: Compilation, Object files, Function call and return, Address space, Data & its representation (4)
- Computer organization: Memory, Registers, Instruction set architecture, Instruction processing (6)
- Virtual memory: Address translation, Paging (4)
- Operating system: Processes, System calls, Process management (6)
- Pipelined processors: Structural, data and control hazards, impact on programming (4)
- Cache memory: Organization, impact on programming (5)
- Program profiling (2)
- File systems: Disk management, Name management, Protection (4)
- Parallel programming: Inter-process communication, Synchronization, Mutual exclusion, Parallel architecture, Programming with message passing using MPI (5)