Download Understanding Memory Bandwidth and Data Size in Computer Architecture - Prof. William D. G and more Exams Computer Science in PDF only on Docsity!
Computer Architecture and
Performance:
Memory Impact;
Instruction Execution
William Gropp
Importance of Memory in
Performance Bounds
• We have seen:
♦ Loads and stores can be as important as
floating point operations
♦ Simple models that look at just sustained
memory bandwidth (and ignore details of
cache effects) can provide useful bounds on
performance
- Recall the sparse matrix-multiply example
- True for problems where the majority of data accesses are consecutive
♦ Note that this is a bound, a guaranteed-not-
to-exceed value for the performance
Memory Bandwidth vs Data Size
L
L
Main Memory
Impact of Memory Hierarchy
Data Size (Bytes) 10 3 10 4 10 5 10 6 10 7 10 (^10008) 2000 3000 4000 5000 6000 7000 8000 9000 10000 11000 12000 13000 14000 15000 STREAM performance in MB/s versus data size L L
Breaking the Model: TLB
- Adding virtual memory requires a extremely
fast way to convert virtual addresses to
physical addresses
♦ The Translation Lookaside Buffer is a cache that performs this translation ♦ However, with typical page sizes, the TLB does not provide fast translation for all memory in cache
- Cost of occasional TLB miss in consecutive accesses (for data in memory and not on disk) is relatively small
- Cost for non-consecutive addresses can be very large ♦ Partial fix: Specify larger pages
- No standard way to do this in language (or among flavors of Unix) ♦ Algorithmic fix: Change order of accesses
- No standard way to control in language
- Depends on page and cache line size
What’s Next?
• There are many details that we’ve
ignored
♦ Can more than one operation take
place at a time?
♦ Does each assignment require a store
into memory?
♦ What about the other operations
(loop counts and tests, array
indexing, etc.)?
• Before answering these, lets revisit
the CPU
More Details
• Can more than one operation take place
at a time?
♦ Yes, if they involve different functional units
♦ Or if there are multiple units of the same
type, as long as enough units are available
- Architecture Feature: Quickest way to add to peak floating point performance is to add floating point units
- Algorithm and Programming language must make use of these − Discussion Question: Are there natural ways to use and express this?
More Details (2)
• Does each assignment require a store
into memory?
• Consider this code in C:
double sum = 0;
for (I=0;I <n; I++) {
sum = sum + a[I];
• The value “sum” may be stored in
register, requiring no load or store.
♦ Making use of registers can be crucial in
achieving high performance
♦ Recall the CPU diagram: most operations
take place between operands in register
Perils of Aliasing
- They do not compute the same value!
- Consider this usage of the routines ♦ Sum( &a[2], a, 3 ); ♦ In the first case, the routine computes - A[2] + A[0] + a[1] + a[2] + a[0] + a[1] - Why? ♦ In the second case, the routine computes - A[0] + a[1] + a[2]
- When two variables may describe overlapping memory regions, they are said to alias one another ♦ Programming languages with pointers often permit aliasing (how can they prevent it) ♦ The potential for aliasing can force the compiler to store a value (or in a different example, load it) even though the programmer does not intend to use aliased data ♦ Discussion Question: Is this a flaw in the programming model? If so, how would you fix it?
More Details (4)
• What about the other operations (loop
counts and tests, array indexing, etc.)?
♦ Operations on integers are relatively fast in
modern CPUs
- Exceptions include integer divide and modulus
♦ Branches (conditional jumps to other parts
of the code, such as at a loop test) are also
relatively expensive
♦ However, most are still faster than an L
cache miss
Some Rules for Bounding Performance
- Most importantly remember: the goal is to create an effective (but possibly approximate) bound on performance - not an estimate! ♦ Discussion Question: What’s the difference?
- Count the number of operations in each functional unit category: ♦ Loads/Stores ♦ Floating Point (add, subtract, multiply - divides are a special subcase) ♦ Other operations (integer arithmetic, branches, comparisons, etc.)
- For each of these, compute the time they will take
- The bound on the time is the max of these three ♦ Note: not really a bound because we’ve ignored any dependencies between the different operations ♦ You can refine each of these by including more detail - Refine load/store by considering cache
Another Example: Matrix-Matrix Multiply (ddot form)
- do i=1,n do j=1,n do k=1,n c(i,j) = c(i,j) + a(i,k) * b(k,j) =
- Like transpose, but two new features:
- Perform a calculation (we’ll see why this is important later)
- Reuse of data: n 2 data used for n 3 operations
Reusing Data
- Load data into register
- Use several times (each load, even from
cache, is at least a cycle)
- Use loop unrolling to expose register use ♦ … c(i,j) += a(i,k) * b(k,j) c(i+1,j) += a(i+1,k) * b(k,j) c(i,j+1) += a(i,k) * b(k,j+1) c(i+1,j+1) += a(i+1,k) * b(k,j+1)
- Each a(i,j) etc. used twice ♦ Cuts the numbers of loads in half ♦ But requires enough registers to hold all items - 4 registers for a(I,k), a(I+1,k), b(k,j), b(k,j+1) plus 2 registers for I, j, and 4 registers for address of a(I,k), address of b(k,j), address of c(I,j), and address of c(I,j+1).
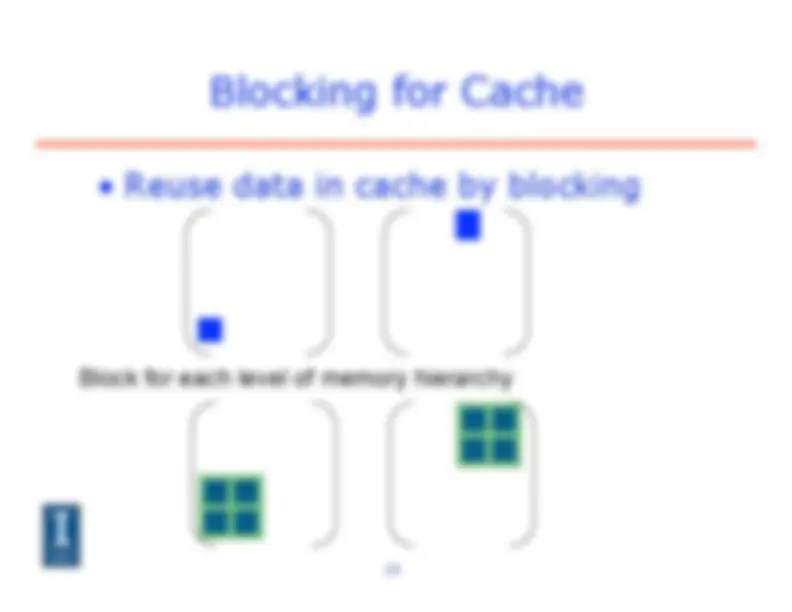
Blocking for Cache
• Reuse data in cache by blocking
Block for each level of memory hierarchy