



Randal E. Bryant
Carnegie Mellon University
CS:APP2e
CS:APP Chapter 4
Computer Architecture
Wrap-Up
http://csapp.cs.cmu.edu















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
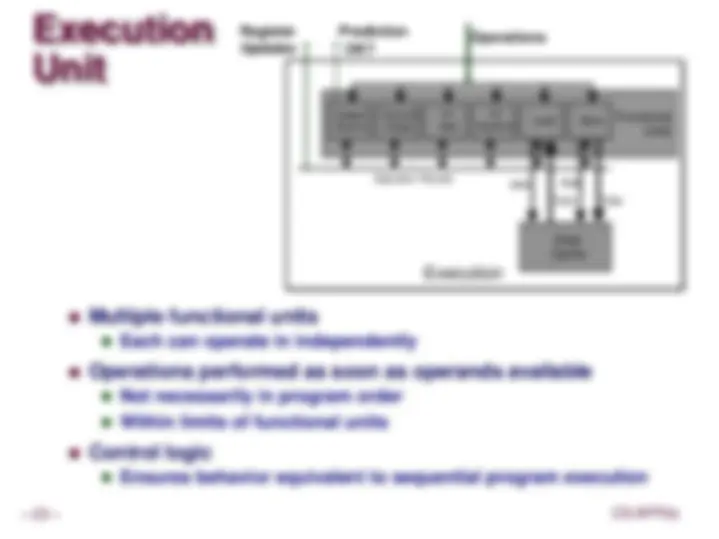
Pipe Design, Modern High-Performance Processors, Exceptions, Maintain Exception, Ordering Exception, Handling Logic, Side Effect in Pipeline, processors, Control logic, Performance metrics, CPI for PIPE, Standard Fetch Timing, Modified Fetch Timing, Execution Unit, ICore Operation
Typology: Slides
1 / 28

This page cannot be seen from the preview
Don't miss anything!
CS:APP2e
Overview
Wrap-Up of PIPE Design
Exceptional conditions
Performance analysis
Fetch stage design
Modern High-Performance Processors
Out-of-order execution
Exception Examples
Detect in Fetch Stage
Detect in Memory Stage
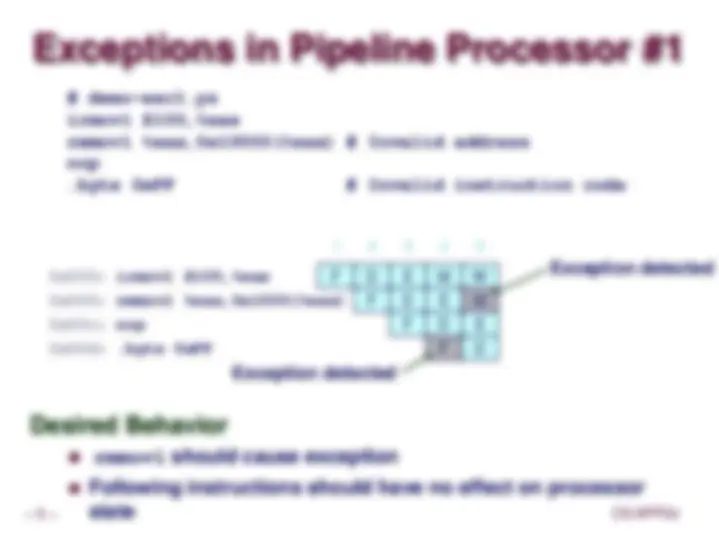
Exceptions in Pipeline Processor #
Desired Behavior
rmmovl should cause exception
Following instructions should have no effect on processor state
0x000: irmovl $100,%eax
1 2 3 4
F D E M 0x006: rmmovl %eax,0x1000(%eax) F D E 0x00c: nop 0x00d: .byte 0xFF
5
Maintaining Exception Ordering
Add status field to pipeline registers
Fetch stage sets to either “AOK,” “ADR” (when bad fetch address), “HLT” (halt instruction) or “INS” (illegal instruction)
Decode & execute pass values through
Memory either passes through or sets to “ADR”
Exception triggered only when instruction hits write back
F predPC
W stat icode^ valE^ valM^ dstE^ dstM
M stat icode^ Cnd valE^ valA^ dstE^ dstM
E stat icode^ ifun^ valC^ valA^ valB^ dstE^ dstM^ srcA^ srcB
D stat icode^ ifun^ rA rB^ valC^ valP
Exception Handling Logic
Fetch Stage
Memory Stage
Writeback Stage
dmem_error
int f_stat = [ imem_error: SADR; !instr_valid : SINS; f_icode == IHALT : SHLT; 1 : SAOK; ];
int m_stat = [ dmem_error : SADR; 1 : M_stat; ];
int Stat = [
W_stat == SBUB : SAOK; 1 : W_stat; ];
Avoiding Side Effects
Presence of Exception Should Disable State Update
Invalid instructions are converted to pipeline bubbles
Data memory will not write to invalid address
Prevent invalid update of condition codes
Handling exception in final stages
Included in HCL code
Control Logic for State Changes
Setting Condition Codes
Stage Control
Also controls updating of memory
bool set_cc = E_icode == IOPL &&
!m_stat in { SADR, SINS, SHLT } && !W_stat in { SADR, SINS, SHLT };
through memory stage bool M_bubble = m_stat in { SADR, SINS, SHLT } || W_stat in { SADR, SINS, SHLT };
bool W_stall = W_stat in { SADR, SINS, SHLT };
Performance Metrics
Clock rate
Measured in Gigahertz
Function of stage partitioning and circuit design
Rate at which instructions executed
CPI: cycles per instruction
On average, how many clock cycles does each instruction require?
Function of pipeline design and benchmark programs
CPI for PIPE
CPI ≈ 1.
Fetch instruction each clock cycle
Effectively process new instruction almost every cycle
CPI > 1.
Sometimes must stall or cancel branches
Computing CPI
C clock cycles
I instructions executed to completion
B bubbles injected (C = I + B)
CPI = C/I = (I+B)/I = 1.0 + B/I
Factor B/I represents average penalty due to bubbles
Fetch Logic Revisited
During Fetch Cycle
**1. Select PC
Timing
Steps 2 & 4 require significant amount of time
Standard Fetch Timing
Must Perform Everything in Sequence
Can’t compute incremented PC until know how much to increment it by
Select PC
Mem. Read Increment
need_regids, need_valC
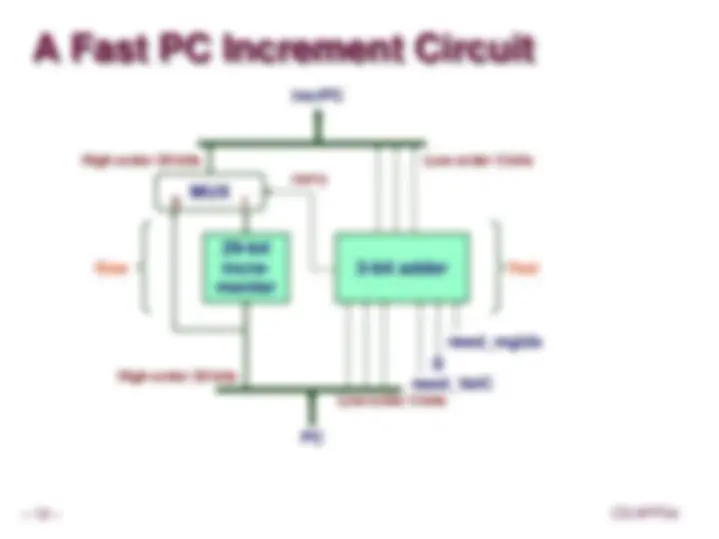
Modified Fetch Timing
29-Bit Incrementer
Acts as soon as PC selected
Output not needed until final MUX
Works in parallel with memory read
Select PC
Mem. Read
Incrementer
need_regids, need_valC 3-bit add
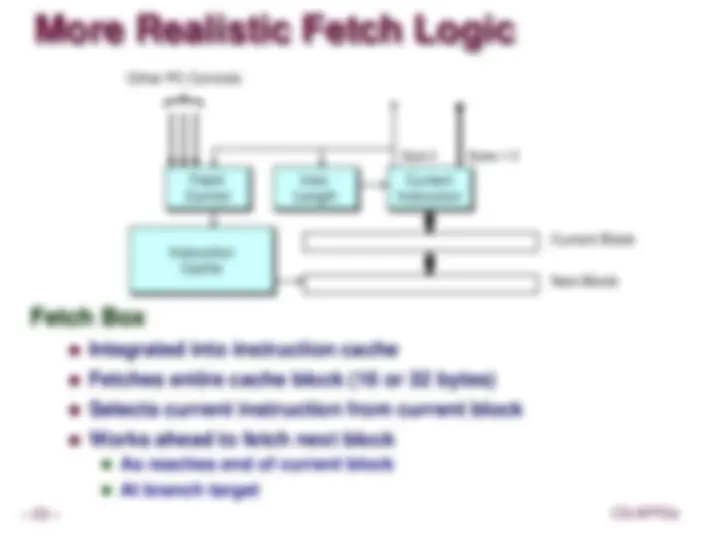
More Realistic Fetch Logic
Fetch Box
Integrated into instruction cache
Fetches entire cache block (16 or 32 bytes)
Selects current instruction from current block
Works ahead to fetch next block
Instruction Cache
Instruction Cache
Byte 0 Bytes 1-
Current Block
Next Block
Current Instruction
Current Instruction
Instr. Length
Instr. Length
Fetch Control
Fetch Control
Other PC Controls