


1
CSE 311
Computer Organization
Mostafa I. Soliman
Professor of Computer Engineering
CSE Department
Lecture 10
Enhancing Performance
with Pipelining
Lecture 10
Enhancing Performance
with Pipelining

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Computer Organization MIPS pipelining
Typology: Slides
Uploaded on 04/14/2021
5 documents
1 / 32

This page cannot be seen from the preview
Don't miss anything!
Pipelined vs. Single-Cycle
Instruction Execution: the Plan
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Single-cycle
Pipelined
Assume 2 ns for memory access, ALU operation; 1 ns for register access:
therefore, single cycle clock 8 ns; pipelined clock cycle 2 ns.
Pipelining: Keep in Mind
increases throughput of entire workload
potential speedup = number pipe stages
in the pipeline – reduces speedup
Pipelining MIPS
structural hazards: different instructions, at different stages, in the pipeline want to use the same
hardware resource
into pipeline, depends on the outcome of a previous
branch instruction, already in pipeline
data to be computed by a previous instruction still in
the pipeline
control we first briefly examine these potential hazards
individually…
Structural Hazards
Structural hazard : inadequate hardware to simultaneously
support all instructions in the pipeline in the same clock cycle
in pipeline below with one read port
MIPS was designed to be pipelined : structural hazards are easy to
avoid!
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Pipelined
Instruction
fetch
Reg ALU
Data
access
Reg
Control Hazards
Instruction
fetch
Reg ALU
Data
access
Reg
Time
beq $ 1 , $ 2 , 40
add $ 4 , $ 5 , $ 6
lw $ 3 , 300 ($ 0 )
Instruction
fetch
Reg ALU
Data
access
Reg
2 ns
Instruction
fetch
Reg ALU
Data
access
Reg
2 ns
Program
execution
order
(in instructions)
Instruction
fetch
Reg ALU
Data
access
Reg
Time
beq $ 1 , $ 2 , 40
add $ 4 , $ 5 ,$ 6
or $ 7 , $ 8 , $ 9
Instruction
fetch
Reg ALU
Data
access
Reg
2 4 6 8 10 12 14
2 4 6 8 10 12 14
Instruction
fetch
Reg ALU
Data
access
Reg
2 ns
4 ns
Program
execution
order
(in instructions)
Prediction success
Prediction failure: undo )=flush( lw
Control Hazards
next statement with the branch executing after one
instruction delay – compiler’s job to find a statement that
can be put in the slot that is independent of branch
outcome
Settings(
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Instruction
fetch
Reg ALU
Data
access
Reg
Delayed branch beq is followed by add that is
independent of branch outcome
Data Hazards
Time
lw $s 0 , 20 ($t 1 )
sub $t 2 , $s 0 , $t 3
Program
execution
order
(in instructions)
Time
lw $s 0 , 20 ($t 1 )
sub $t 2 , $s 0 , $t 3
Program
execution
order
(in instructions)
Reordering Code to Avoid
Pipeline Stall )Software Solution(
lw $t0, 0($t1)
lw $t2, 4($t1)
sw $t2, 0($t1)
sw $t0, 4($t1)
lw $t0, 0($t1)
lw $t2, 4($t1)
sw $t0, 4($t1)
sw $t2, 0($t1)
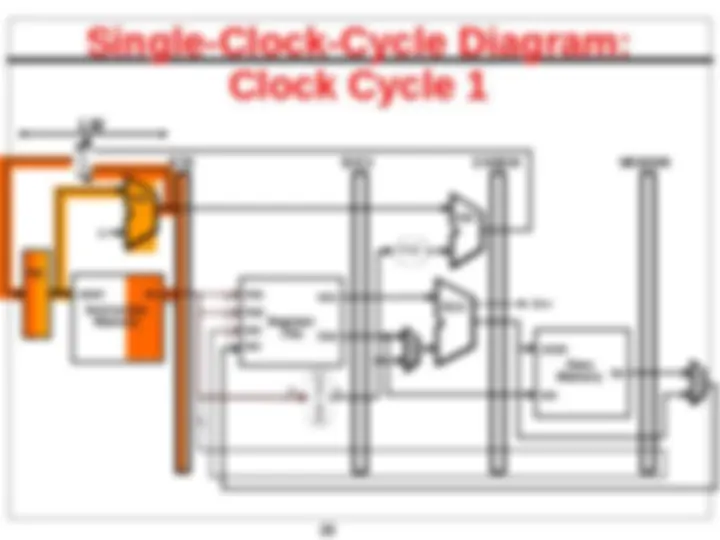
Review - Single-Cycle Datapath “Steps”
5 5
16
16 32
5
Instruction I
32
M
U
X
M
U
X
32
IF
ID
EX
. Execute/ Address Calc
MEM
WB
Zero
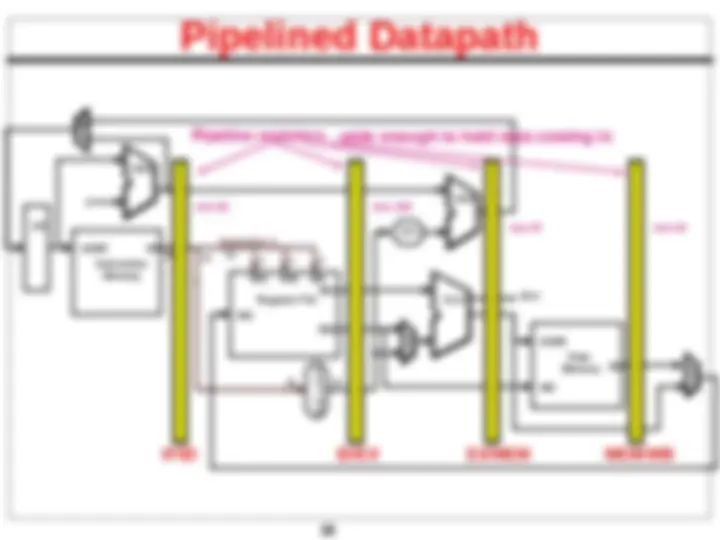
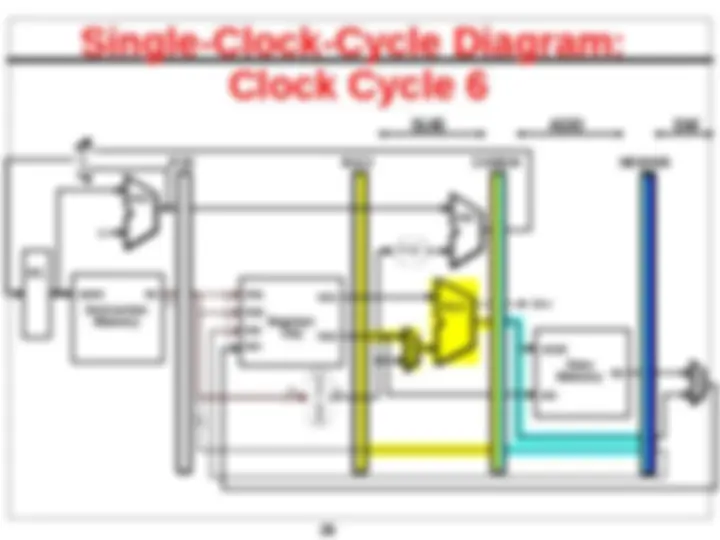
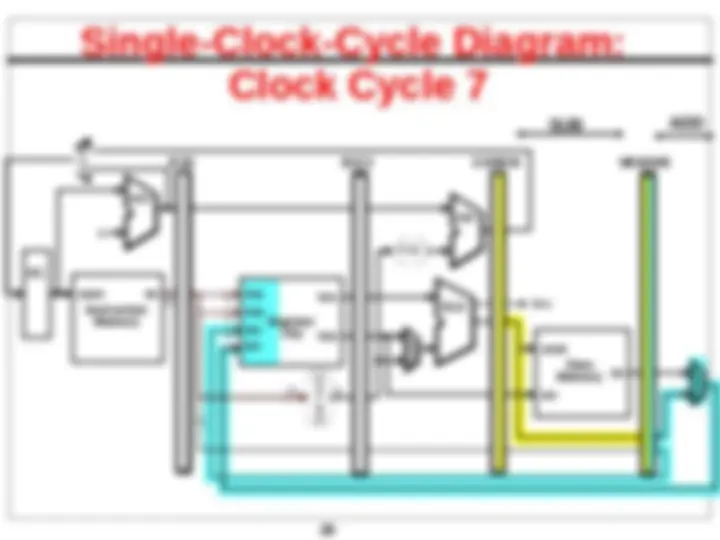
Pipelined Datapath – Key Idea
extra hardware?
cycle - pipelining
Pipelined Datapath
IF/ID
Pipeline registers
5 5
16
16 32
5
Instruction I
32
M
U
X
M
U
X
32
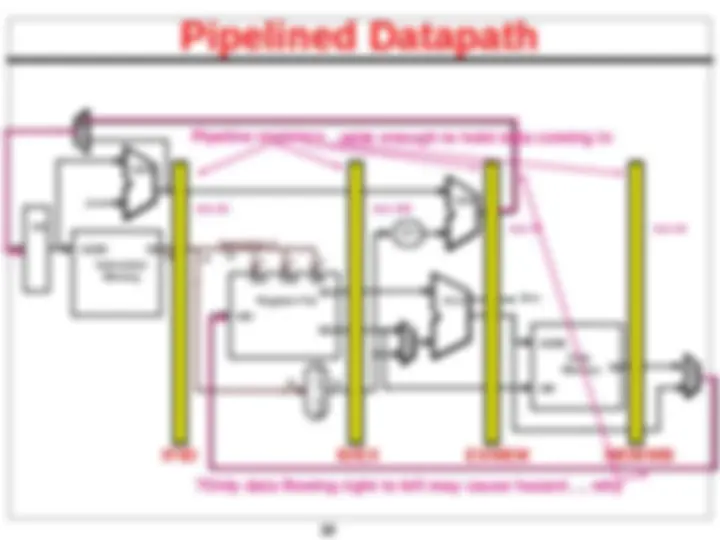
ID/EX EX/MEM MEM/WB
Zero
wide enough to hold data coming in
? Only data flowing right to left may cause hazard…, why
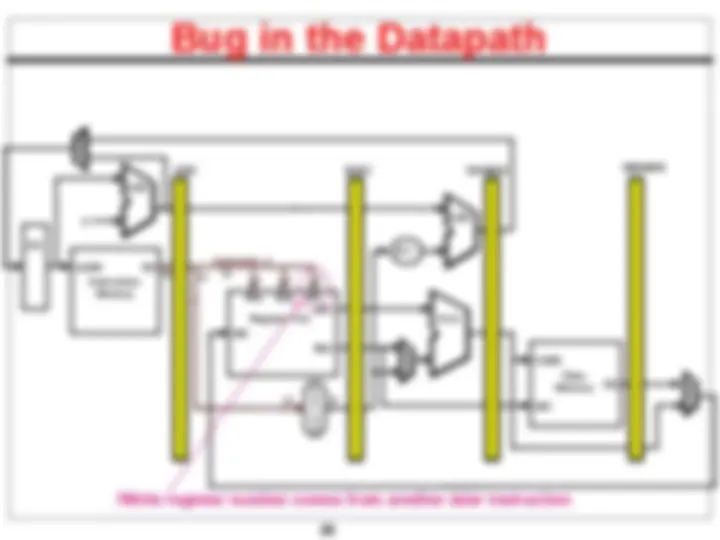
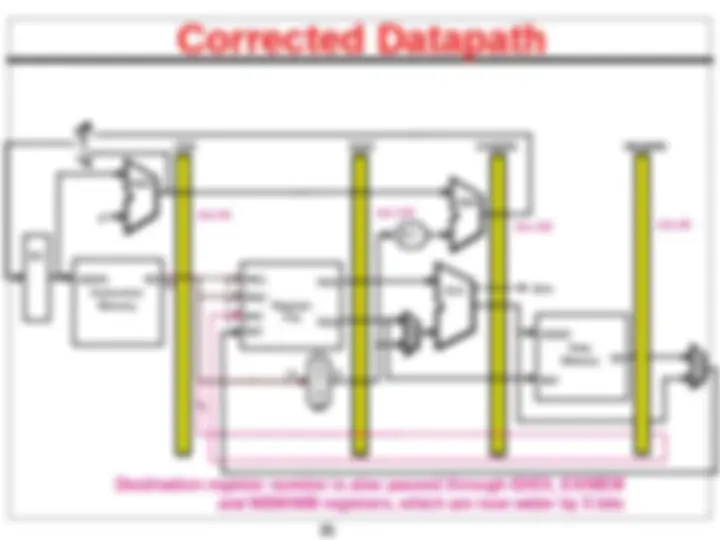
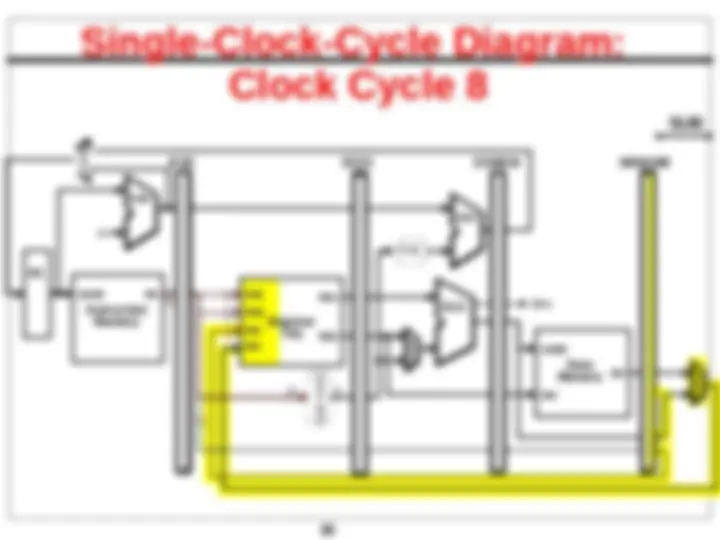
Bug in the Datapath
5 5
16
16 32
5
Instruction I
32
M
U
X
M
U
X
32
! Write register number comes from another later instruction