



Deep Residual Learning for Image Recognition
Authors:
Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun
Presenter: Masoud Hoveidar
Facilitators: Amber Ma and Ramya Balasubramaniam
12th August 2019

















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Our current optimization solvers are not able to approximate the identity mappings of a stack of added non-linear layers.
Typology: Exercises
1 / 27

This page cannot be seen from the preview
Don't miss anything!
Authors: Kaiming He, Xiangyu Zhang, Shaoqing Ren and Jian Sun
How DEEP should we make our Neural Networks?
○ The complexity of the task at hand ○ Available computational capacity in the time of training ○ Available computational capacity in the time of inference (e.g. on edge devices)
○ Can we train very deep networks efficiently using current optimization solvers? ○ Is training a better model as simple as adding more and more layers?
How DEEP should we make our Neural Networks?
○ The complexity of the task at hand ○ Available computational capacity in the time of training ○ Available computational capacity in the time of inference (e.g. on edge devices)
○ Can we train very deep networks efficiently using current optimization solvers? ○ Is training a better model as simple as adding more and more layers?
NO
Why is it not OK to just add more layers?
○ Vanishing/Exploding gradients ■ Can be addressed by normalized initialization and intermediate normalization ○ Degradation problem ■ What should we do about it?
Degradation problem … (continued)
conv conv conv
fc softmax
Acc. = X%
Degradation problem … (continued)
conv conv conv
fc softmax
Acc. = X%
conv conv conv identity identity
fc softmax
Acc. = X% identity identity
Degradation problem … (continued)
Degradation problem … (continued)
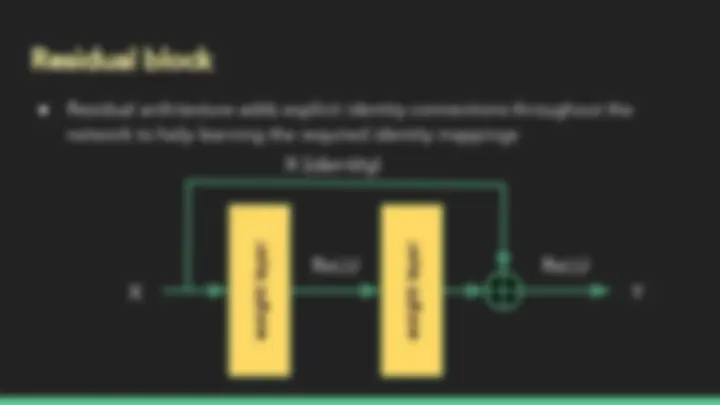
Residual block
X
ReLU
X (identity)
ReLU
Y
Residual block (continued)
Resnet architecture
Y = F(x,{Wi}) + Wsx
Linear projections For dimension matching
Resnet architectures for ImageNet dataset
“18 layers vs 34 layers” on ImageNet dataset