Download Deep Residual Learning for Image Recognition: ResNet Architecture Analysis and more Schemes and Mind Maps Design in PDF only on Docsity!
Deep Residual Learning
for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
work done at
Microsoft Research Asia
1 x^1 conv
,^64
3 x^3 conv
,^64
1 x^1 conv
1 x^1 conv
,^64
3 x^3 conv
,^64
1 x^1 conv
1 x^1 conv
,^64
3 x^3 conv
,^64
1 x^1 conv
1 x^1 conv
/^2
3 x^3 conv
1 x^1 conv
1 x^1 conv
3 x^3 conv
1 x^1 conv
1 x^1 conv
3 x^3 conv
1 x^1 conv
1 x^1 conv
3 x^3 conv
1 x^1 conv
1 x^1 conv
3 x^3 conv
1 x^1 conv
1 x^1 conv
,^128
3 x^3 conv
,^128
1 x^1 conv
,^512
1 x^1 conv
3 x^3 conv
1 x^1 conv
1 x^1 conv
,^128
3 x^3 conv
,^128
1 x^1 conv
,^512
1 x^1 conv
/^2
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^1024
1 x^1 conv
/^2
3 x^3 conv
1 x^1 conv
,^2048
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^2048
1 x^1 conv
3 x^3 conv
1 x^1 conv
,^2048
ave pool
,^ fc^1000
7 x^7 conv
, 64 ,^ /^2
,^ pool^ /
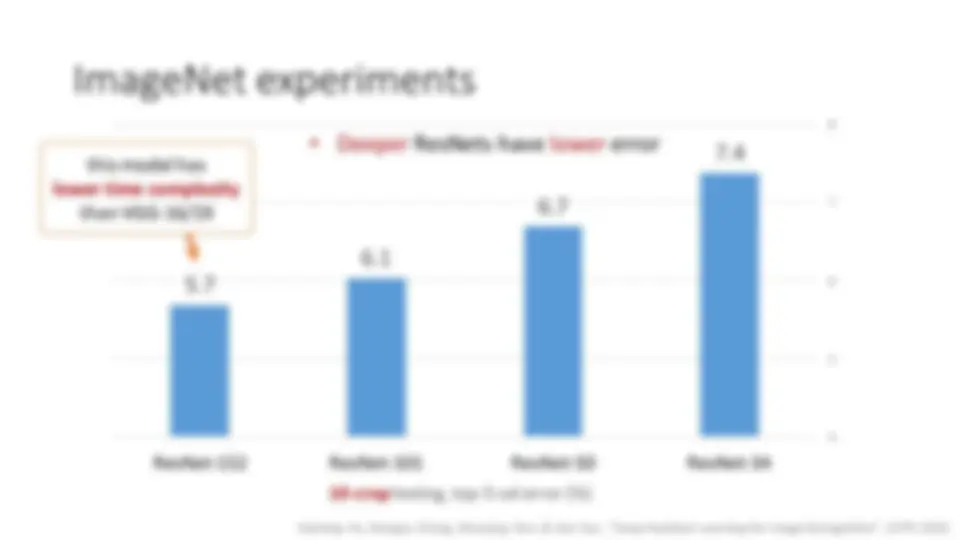
ResNet @ ILSVRC & COCO 2015 Competitions 1st places in all five main tracks
- ImageNet Classification: “ Ultra-deep ” 152 - layer nets
- ImageNet Detection: 16% better than 2nd
- ImageNet Localization: 27% better than 2nd
- COCO Detection: 11% better than 2nd
- COCO Segmentation: 12% better than 2nd *improvements are relative numbers
Revolution of Depth
HOG, DPM AlexNet
(RCNN)
VGG
(RCNN)
ResNet
(Faster RCNN)*
PASCAL VOC 2007 Object Detection mAP (%)
shallow 8 layers 16 layers
101 layers
*w/ other improvements & more data Engines of visual recognition
Revolution of Depth 11 x 11 conv, 96 , / 4 , pool/ 2
5 x 5 conv, 256 , pool/ 2
3 x 3 conv, 384
3 x 3 conv, 384
3 x 3 conv, 256 , pool/ 2
fc, 4096
fc, 4096
fc, 1000
AlexNet, 8 layers
(ILSVRC 2012)
AlexNet, 8 layers
(ILSVRC 2012)
Revolution of Depth
ResNet, 152 layers
VGG, 19 layers
Is learning better networks
as simple as stacking more layers?
Simply stacking layers? 0 1 2 3 4 5 6 0 5 10 20 iter. (1e4) error (%) plain- 20 plain- 32 plain- 44 plain- 56 CIFAR- 10 20 - layer 32 - layer 44 - layer 56 - layer 0 10 20 30 40 50 20 30 40 50 60 iter. (1e4) error (%) plain- 18 plain- 34 ImageNet- 1000 34 - layer 18 - layer
- “Overly deep” plain nets have higher training error
- A general phenomenon, observed in many datasets
solid: test/val
dashed: train
7 x 7 conv, 64 , / 2 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 128 , / 2 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 256 , / 2 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 512 , / 2 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 fc 1000
a shallower
model
(18 layers)
a deeper
counterpart
(34 layers)
7 x 7 conv, 64 , / 2 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 64 3 x 3 conv, 128 , / 2 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 128 3 x 3 conv, 256 , / 2 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 512 , / 2 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 fc 1000 “extra” layers
- Richer solution space
- A deeper model should not have higher
training error
- A solution by construction :
- original layers: copied from a
learned shallower model
- extra layers: set as identity
- at least the same training error
- Optimization difficulties: solvers cannot
find the solution when going deeper…
Deep Residual Learning
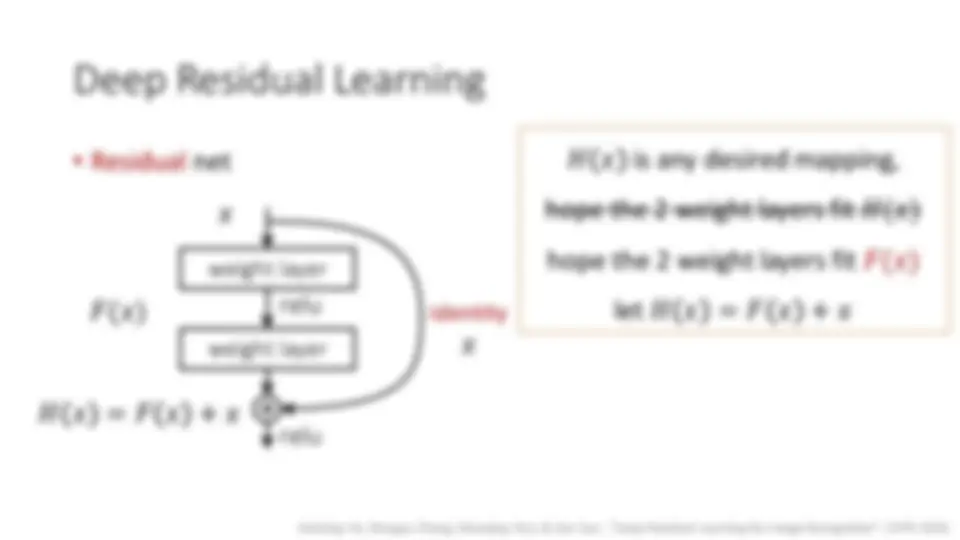
- Residual net 𝐻 𝑥 is any desired mapping, hope the 2 weight layers fit 𝐻(𝑥) hope the 2 weight layers fit 𝐹(𝑥) let 𝐻 𝑥 = 𝐹 𝑥 + 𝑥
weight layer
weight layer
relu relu 𝑥 𝐻 𝑥 = 𝐹 𝑥 + 𝑥
identity
𝑥 𝐹(𝑥)
Deep Residual Learning
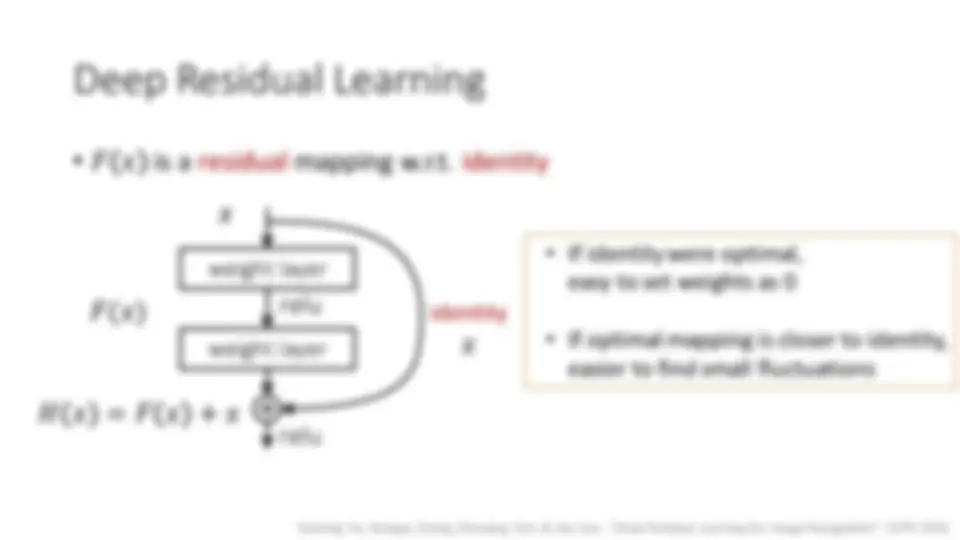
- 𝐹 𝑥 is a residual mapping w.r.t. identity
- If identity were optimal,
easy to set weights as 0
- If optimal mapping is closer to identity,
easier to find small fluctuations
weight layer
weight layer
relu relu 𝑥 𝐻 𝑥 = 𝐹 𝑥 + 𝑥
identity
𝑥 𝐹(𝑥)
CIFAR-10 experiments 0 1 2 3 4 5 6 0 5 10 20 iter. (1e4) error (%) plain- 20 plain- 32 plain- 44 plain- 56 20 - layer 32 - layer 44 - layer 56 - layer CIFAR-10 plain nets (^00 1 2 3 4 5 ) 5 10 20 iter. (1e4) error (%) ResNet- 20 ResNet- 32 ResNet- 44 ResNet- 56 ResNet- 110 CIFAR- 10 ResNets 56 - layer 44 - layer 32 - layer 20 - layer 110 - layer
- Deep ResNets can be trained without difficulties
- Deeper ResNets have lower training error , and also lower test error solid: test dashed: train
ImageNet experiments 0 10 20 30 40 50 20 30 40 50 60 iter. (1e4) error (%) ResNet- 18 ResNet- 34 0 10 20 30 40 50 20 30 40 50 60 iter. (1e4) error (%) plain- 18 plain- 34 ImageNet plain nets ImageNet ResNets solid: test dashed: train 34 - layer 18 - layer 18 - layer 34 - layer
- Deep ResNets can be trained without difficulties
- Deeper ResNets have lower training error , and also lower test error
Beyond classification
A treasure from ImageNet is on learning features.
Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. arXiv 2015.
“ Features matter. ” (quote [Girshick et al. 2014], the R-CNN paper) task
2nd-place
winner
ResNets
margin
(relative) ImageNet Localization (top-5 error) 12.0^ 9.0^ 27% ImageNet Detection ([email protected]) 53.6^ 62.1^ 16% COCO Detection ([email protected]:.95) 33.5^ 37.3^ 11% COCO Segmentation ([email protected]:.95) 25.1^ 28.2^ 12%
- Our results are all based on ResNet- 101
- Our features are well transferrable
absolute
8.5% better!