Download Deep Residual Networks and more Lecture notes Design in PDF only on Docsity!
Deep Residual Networks
Deep Learning Gets Way Deeper
8:30-10:30am, June 19
ICML 2016 tutorial
Kaiming He
Facebook AI Research*
*as of July 2016. Formerly affiliated with Microsoft Research Asia
1 x^1 conv ,^64 3 x^3 conv ,^64 1 x^1 conv ,^256 1 x^1 conv ,^64 3 x^3 conv ,^64 1 x^1 conv ,^256 1 x^1 conv ,^64 3 x^3 conv ,^64 1 x^1 conv ,^256 1 x^1 conv ,^128 ,^ /^2 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^128 3 x^3 conv ,^128 1 x^1 conv ,^512 1 x^1 conv ,^256 , /^2 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv , 1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^256 3 x^3 conv ,^256 1 x^1 conv ,^1024 1 x^1 conv ,^512 ,^ /^2 3 x^3 conv ,^512 1 x^1 conv ,^2048 1 x^1 conv ,^512 3 x^3 conv ,^512 1 x^1 conv ,^2048 1 x^1 conv ,^512 3 x^3 conv ,^512 1 x^1 conv ,^2048 ave pool ,^ fc^1000 7 x^7 conv ,^64 ,^ /^2 , pool^ / 2
Overview
- Introduction
- Background
- Deep Residual Networks
- From 10 layers to 100 layers
- From 100 layers to 1000 layers
- Applications
- Q & A
Introduction
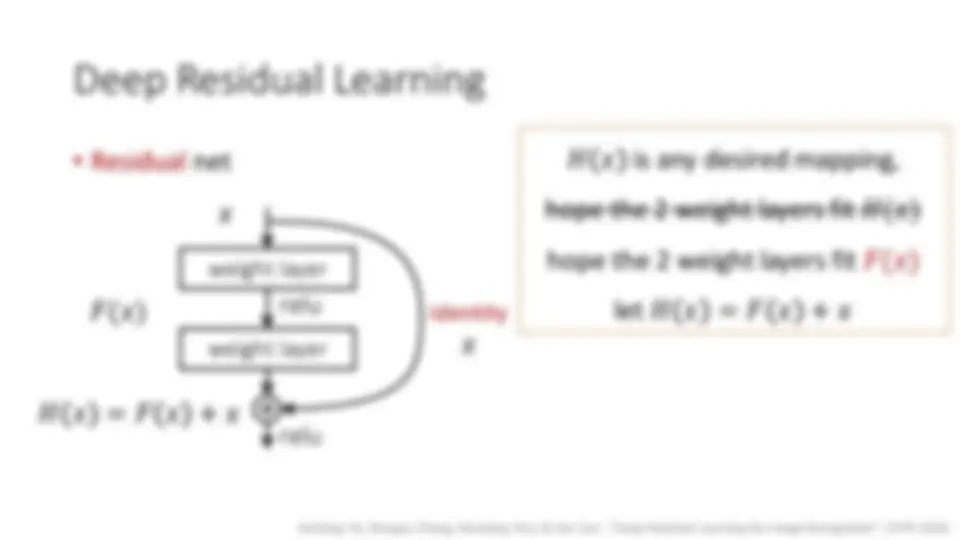
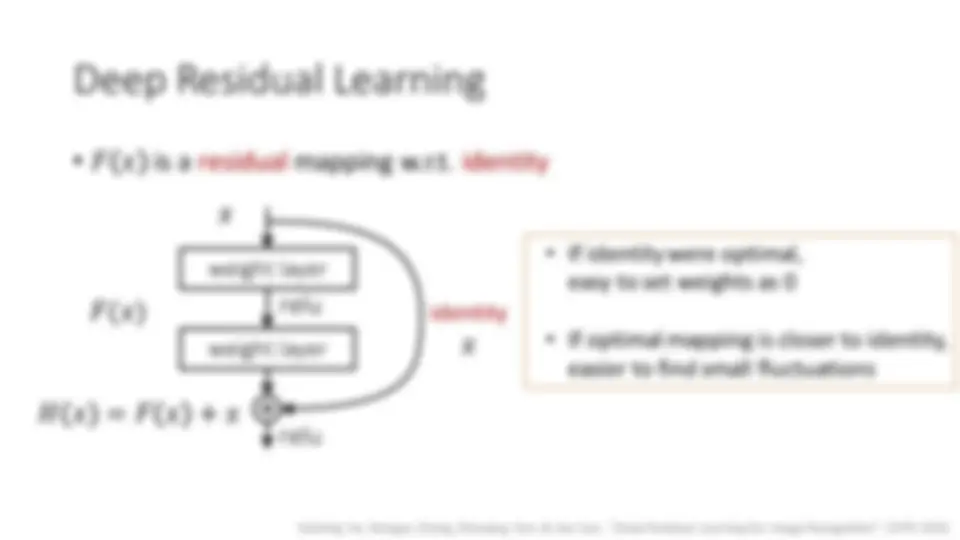
Deep Residual Networks (ResNets)
- “Deep Residual Learning for Image Recognition”. CVPR 2016 (next week)
- A simple and clean framework of training “very” deep nets
- State-of-the-art performance for
- Image classification
- Object detection
- Semantic segmentation
- and more… Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016.
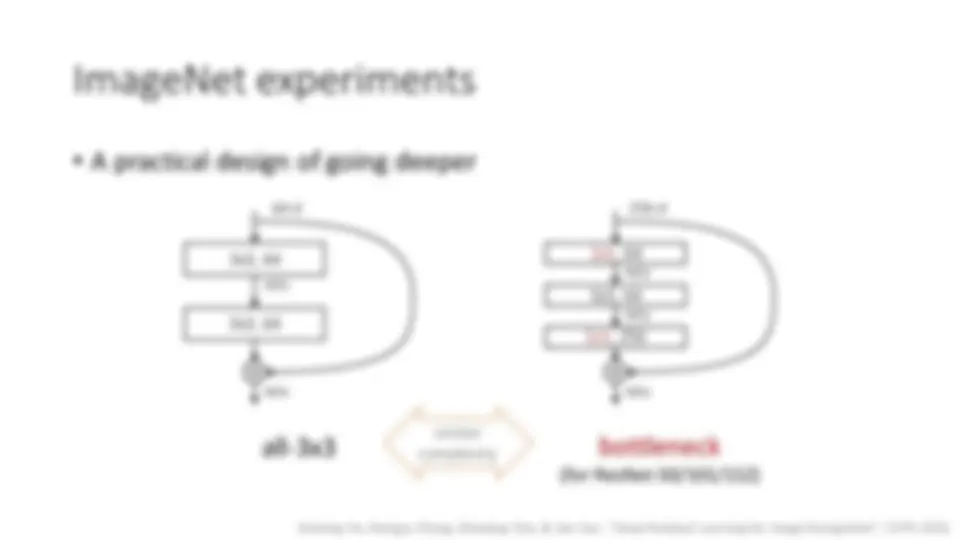
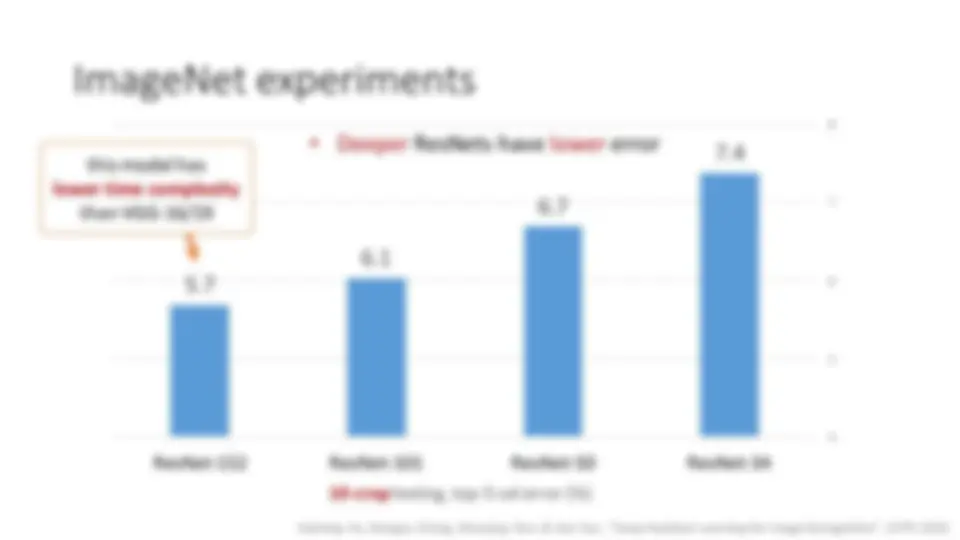
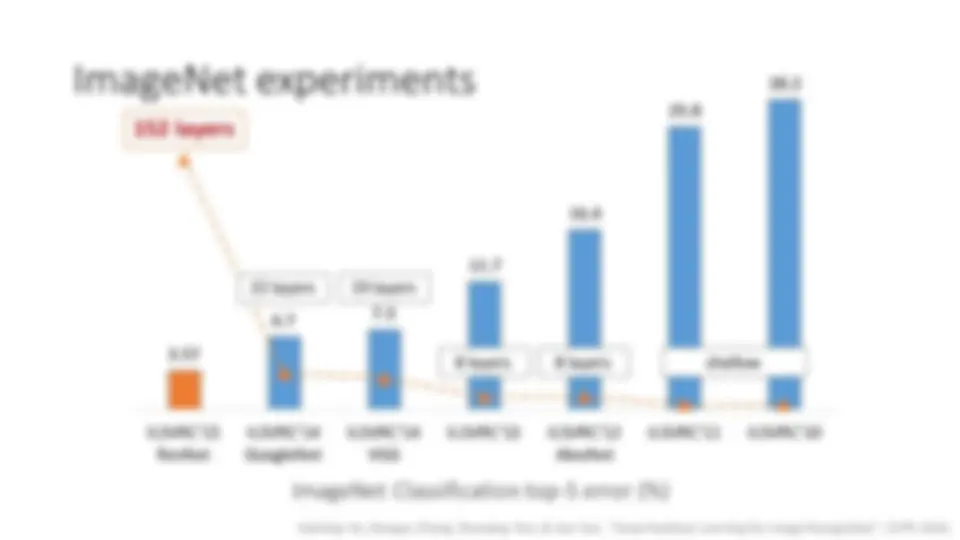
ResNets @ ILSVRC & COCO 2015 Competitions
- 1st places in all five main tracks
- ImageNet Classification: “ Ultra-deep ” 152 - layer nets
- ImageNet Detection: 16% better than 2nd
- ImageNet Localization: 27% better than 2nd
- COCO Detection: 11% better than 2nd
- COCO Segmentation: 12% better than 2nd Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016. *improvements are relative numbers
Revolution of Depth
11 x 11 conv, 96 , / 4 , pool/ 2 5 x 5 conv, 256 , pool/ 2 3 x 3 conv, 384 3 x 3 conv, 384 3 x 3 conv, 256 , pool/ 2 fc, 4096 fc, 4096 fc, 1000 AlexNet, 8 layers (ILSVRC 2012) Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016.
Revolution of Depth
11 x 11 conv, 96 , / 4 , pool/ 2 5 x 5 conv, 256 , pool/ 2 3 x 3 conv, 384 3 x 3 conv, 384 3 x 3 conv, 256 , pool/ 2 fc, 4096 fc, 4096 fc, 1000 AlexNet, 8 layers (ILSVRC 2012) 3 x 3 conv, 64 3 x 3 conv, 64 , pool/ 2 3 x 3 conv, 128 3 x 3 conv, 128 , pool/ 2 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 3 x 3 conv, 256 , pool/ 2 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 , pool/ 2 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 3 x 3 conv, 512 , pool/ 2 fc, 4096 fc, 4096 fc, 1000 VGG, 19 layers (ILSVRC 2014) input 7 x7^ Co +n v 2 (S) Ma 3 x3x +P oo 2 (Sl) LocalRespNorm 1 x1^ Co +n 1 v (V) 3 x3^ Co +n v 1 (S) LocalRespNorm Ma 3 x3x +P oo 2 (Sl) 1 x1^ Co +n 1 v (S) 3 x3Co +n v 1 (S) 5 x5Co +n 1 v (S) 1 x1Co +n v 1 (S) 1 x1^ Co +n v 1 (S) 1 x1Co +n 1 v (S) 3 x3Max +P oo 1 (lS) Dept hConcat 1 x1^ Co +n 1 v (S) 3 x3Co +n v 1 (S) 5 x5Co +n 1 v (S) 1 x1Co +n v 1 (S) 1 x1^ Co +n v 1 (S) 1 x1Co +n 1 v (S) 3 x3Max +P oo 1 (lS) Dept hConcat Ma 3 x3x +P oo 2 (Sl) 1 x1^ Co +n 1 v (S) 3 x3Co +n v 1 (S) 5 x5Co +n 1 v (S) 1 x1Co +n v 1 (S) 1 x1^ Co +n v 1 (S) 1 x1Co +n 1 v (S) 3 x3Max +P oo 1 (lS) Dept hConcat 1 x1^ Co +n v 1 (S) 3 x3Co n+ 1 v (^ S) 5 x5Co +n v 1 (S) 1 x1Co n+v 1 (S) 1 x1^ Co +n 1 v (^ S) 1 x1Co +n v 1 (S) 3 x3Max P+oo 1 (Sl)^ Av 5 x5^ erage + 3 P oo(V)l Dept hConcat 1 x1^ Co +n v 1 (S) 3 x3Co n+ 1 v (^ S) 5 x5Co +n v 1 (S) 1 x1Co n+v 1 (S) 1 x1^ Co n+ 1 v (^ S) 1 x1Co +n v 1 (S) 3 x3Max P+oo 1 (Sl) Dept hConcat 1 x1^ Co +n v 1 (S) 3 x3Co n+ 1 v (^ S) 5 x5Co +n v 1 (S) 1 x1Co n+v 1 (S) 1 x1^ Co n+ 1 v (^ S) 1 x1Co +n v 1 (S) 3 x3Max P+oo 1 (Sl) Dept hConcat 1 x1^ Co n+ 1 v^ (S) 3 x3Co +n 1 v (S) 5 x5Co n+v 1 (S) 1 x1Co +n 1 v (S) 1 x1^ Co +n 1 v (S) 1 x1Co +n v 1 (S) 3 x3Max +P 1 oo (Sl)^ Av 5 x5^ erage + 3 P (ooV)l Dept hConcat 3 x3^ Max P+oo 2 (lS) 1 x1^ Co +nv 1 (S) 3 x3Co +n 1 v (S) 5 x5Co +nv 1 (S) 1 x1Co +n 1 v (S) 1 x1^ Co +n 1 v (S) 1 x1Co +n v 1 (S) 3 x3Max +P 1 oo (Sl) Dept hConcat 1 x1^ Co +nv 1 (S) 3 x3Co +n 1 v (S) 5 x5Co +nv 1 (S) 1 x1Co +n 1 v (S) 1 x1^ Co +n 1 v (S) 1 x1Co +n v 1 (S) 3 x3Max +P 1 oo (Sl) Dept hConcat Av 7 x7 erage + 1 P (ooV)l FC 1 x1^ Co +n v 1 (S) FC FC Soft maxAct iv at ion soft max 1 x1^ Co +n v 1 (S) FC FC Soft maxAct iv at ion soft max Soft maxAct iv at ion soft max GoogleNet, 22 layers (ILSVRC 2014) Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016.
Revolution of Depth
34 58 66 86 HOG, DPM AlexNet (RCNN) VGG (RCNN) ResNet (Faster RCNN)* PASCAL VOC 2007 Object Detection mAP (%) shallow 8 layers 16 layers 101 layers *w/ other improvements & more data Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016. Engines of visual recognition
ResNet’s object detection result on COCO *the original image is from the COCO dataset Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Deep Residual Learning for Image Recognition”. CVPR 2016.
Background
From shallow to deep
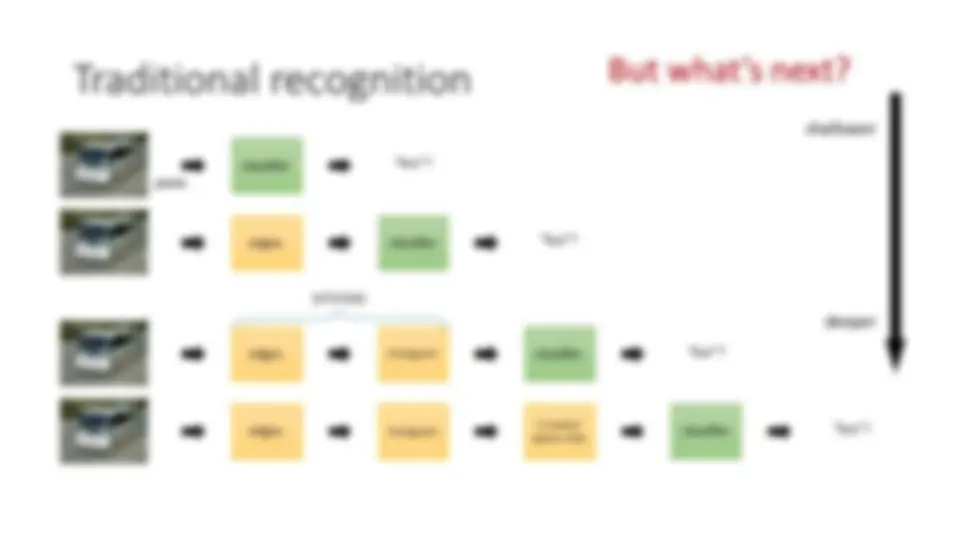
Traditional recognition
edges classifier “bus”? pixels classifier “bus”? edges^ histogram^ classifier “bus”? SIFT/HOG edges histogram classifier “bus”? K-means/ sparse code shallower deeper But what’s next?
Spectrum of Depth
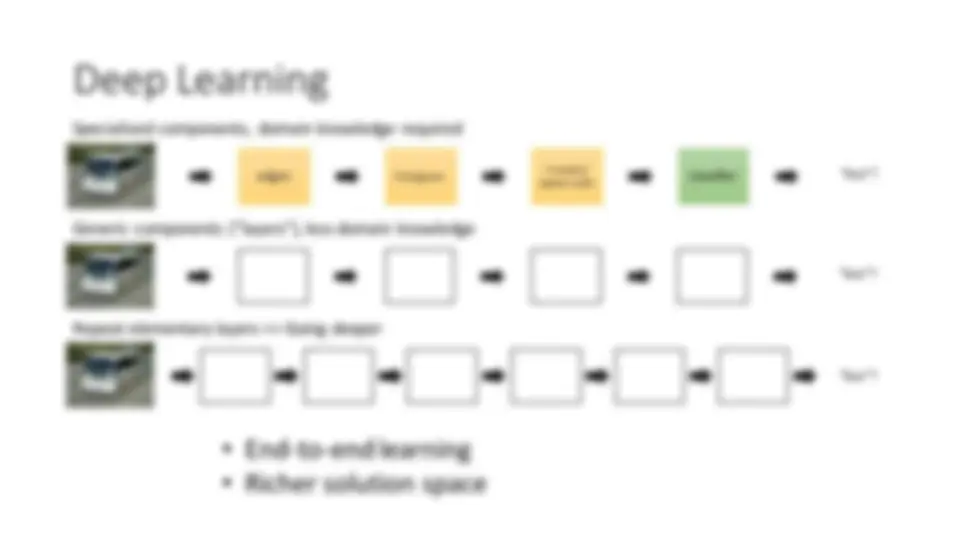
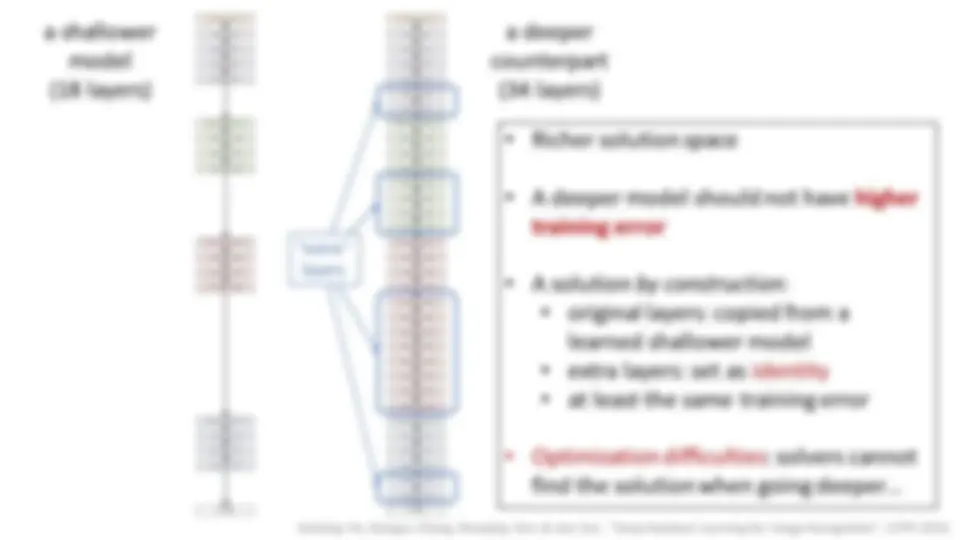
shallower deeper 5 layers: easy
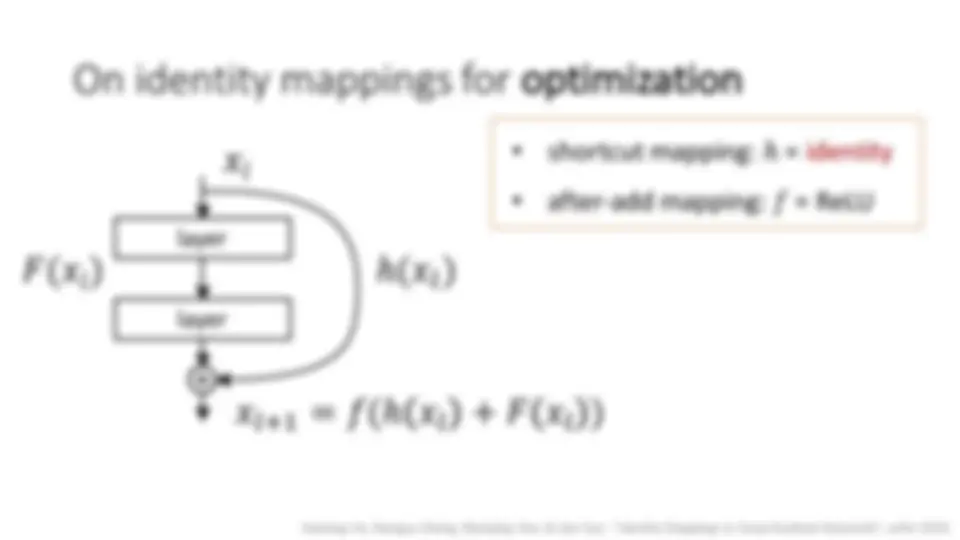
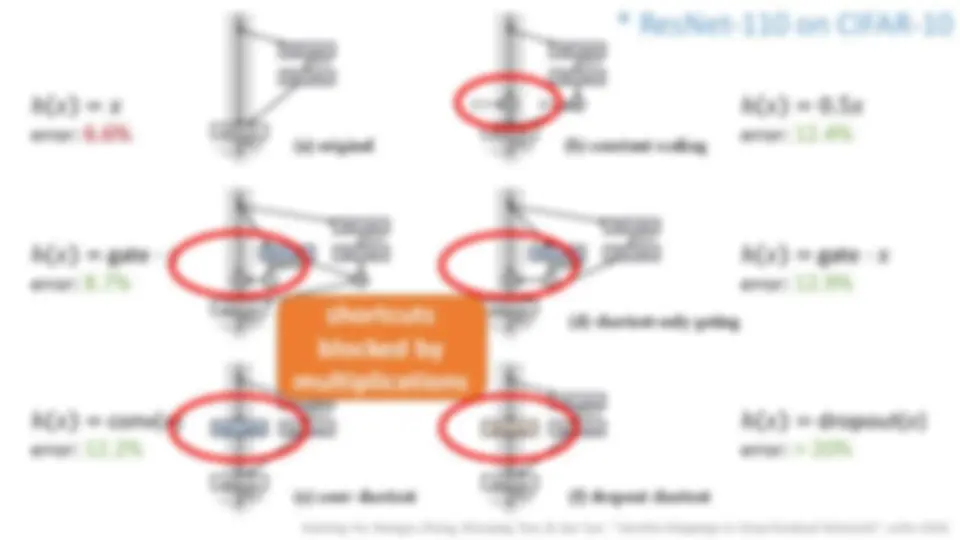
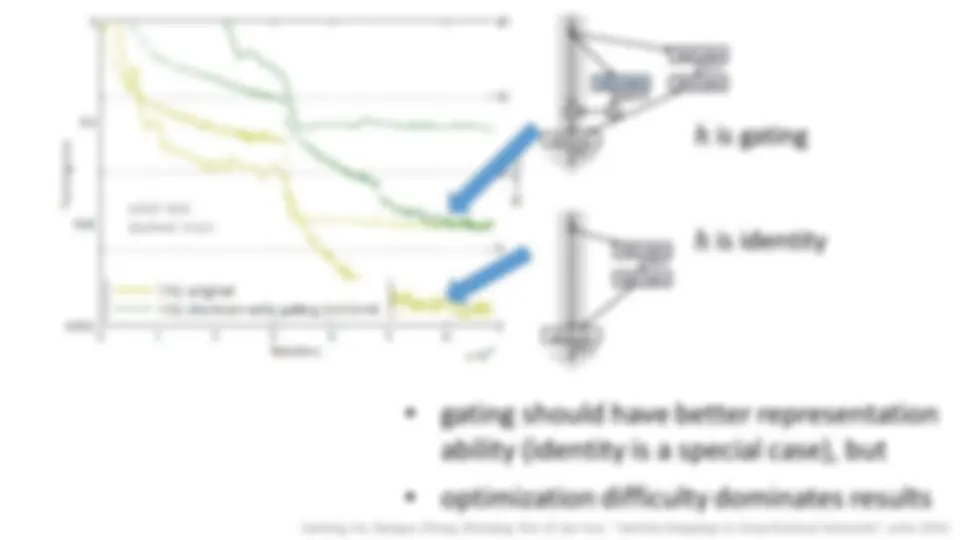
10 layers: initialization, Batch Normalization 30 layers: skip connections 100 layers: identity skip connections 1000 layers:?
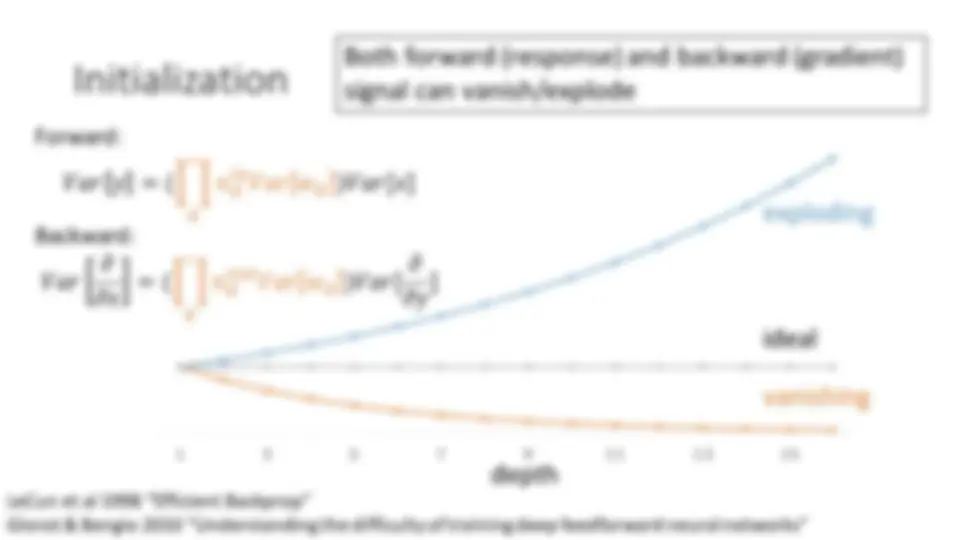
Initialization
LeCun et al 1998 “Efficient Backprop” Glorot & Bengio 2010 “Understanding the difficulty of training deep feedforward neural networks” input 𝑋 output 𝑌 = 𝑊𝑋 weight 𝑊 1 - layer: 𝑉𝑎𝑟 𝑦 = (𝑛 +, 𝑉𝑎𝑟 𝑤 )𝑉𝑎𝑟[𝑥] Multi-layer: 𝑉𝑎𝑟 𝑦 = ( 2 𝑛 3 +, 𝑉𝑎𝑟 𝑤 3 3 )𝑉𝑎𝑟[𝑥] If:
- Linear activation
- 𝑥, 𝑦, 𝑤: independent Then: 𝑛 +, 𝑛 567
Initialization
- Initialization under linear assumption LeCun et al 1998 “Efficient Backprop” Glorot & Bengio 2010 “Understanding the difficulty of training deep feedforward neural networks” ∏ 𝑛 3 +, 𝑉𝑎𝑟 𝑤 3 3 = 𝑐𝑜𝑛𝑠𝑡
? (healthy forward) and ∏ 𝑛 3 567 𝑉𝑎𝑟 𝑤 3 3 = 𝑐𝑜𝑛𝑠𝑡 @? (healthy backward) 𝑛 3 +, 𝑉𝑎𝑟 𝑤 3 = 1 or* 𝑛 3 567 𝑉𝑎𝑟 𝑤 3 = 1 *: 𝑛 3 567 = 𝑛 3 BC +, , so D5,E7FG D5,E7HG = ,IJKL MNO , HPQKL RS <^ ∞. It is sufficient to use either form. “ Xavier ” init in Caffe
Initialization
- Initialization under ReLU activation ∏ C V 𝑛 3 +, 𝑉𝑎𝑟 𝑤 3 3 = 𝑐𝑜𝑛𝑠𝑡>? (healthy forward) and ∏ C V 𝑛 3 567 𝑉𝑎𝑟 𝑤 3 3 = 𝑐𝑜𝑛𝑠𝑡@?(healthy backward) 1 2 𝑛 3 +, 𝑉𝑎𝑟 𝑤 3 = 1 or 1 2 𝑛 3 567 𝑉𝑎𝑟 𝑤 3 = 1 Kaiming He, Xiangyu Zhang, Shaoqing Ren, & Jian Sun. “Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification”. ICCV 2015. With 𝐷 layers, a factor of 2 per layer has exponential impact of 2 Y “ MSRA ” init in Caffe