



Plan 125
Ihsen Benhnia Digital Signal Processor
Chapitre III : Étude du pipeline
pour le TMS320C64x



















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Digital Signal Processor how it works
Typology: Slides
1 / 30

This page cannot be seen from the preview
Don't miss anything!
Plan 125
Chapitre III : Étude du pipeline
pour le TMS320C64x
Cours 2 128
Deux chemins de données : A et B
Chaque chemin contient 4 unités de traitement :
64 registres de 32 bits (A0 à A31) et (B0 à B31)
2 chemins croisés (1x et 2x) ( cross path )
.L1 .S1 .M1 .D1 .L2 .S2 .M2 .D
Registre A0 à A31 Registre B0 à B
Chemin de données A Chemin de données B
Chemin croisé
ISECS 2006-2007 Cours DSP Chapitre 3^129
Registres A 0 , A 1 , A 2 , B 0 , B 1 et B 2 peuvent êtres utilisés comme des registres à condition.
Registres A 4 à A 7 et B 4 à B 7 : pointeur pour le mode d’adressage circulaire.
Registres A 0 à A 9 et B 0 à B 9 : registre temporaire.
Registre A 10 à A 31 et B 10 à B 31 : mémorisés et puis restaurés à chaque appel à un sous programme.
On peut former 32 registres de 40 ou 64 bits en utilisant les paires de registres A 0 :A 1 , A 2 :A 3 , ……et B 30 :B 31.
Il existe d’autres registres de contrôles, d’interruptions, de modes, etc.
Cours 1 131
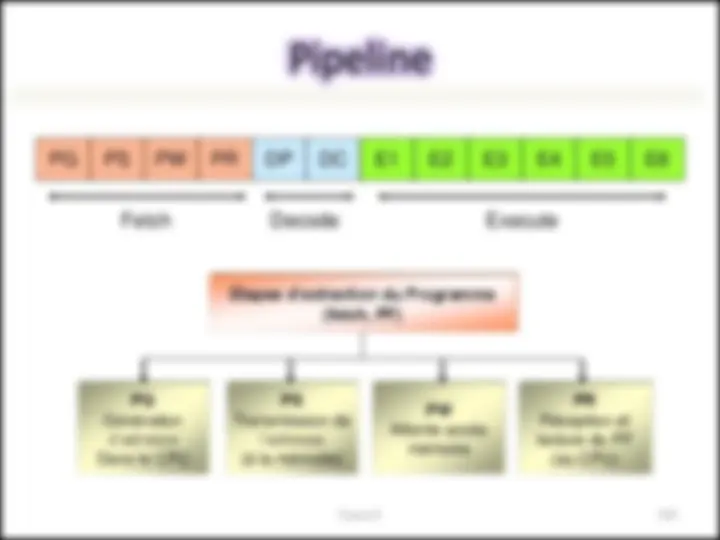
Fetch : 4 sous-étages
Decode : 2 sous-étages
Execute : au maximum 6 sous-étages
Paquet de Fetch et d’Exécution
Cours 2 132
Étage \ temps t1 t2 t3 t4 t5 t6 t7 t8 t Fetch F1 F2 F3 F4 F5 F6 … … … Decode D1 D2 D3 D4 D5 D6 … … Execute E1 E2 E3 E4 E5 E6 …
Étage \ temps t1 t2 t3 t4 t5 t6 t7 t8 t Fetch F1 F2 F Decode D1 D2 D Execute E1 E2 E
Instructions segmentées en étages.
Exécution entrelacée de plusieurs instructions.
Augmentation de la fréquence d'horloge.
Cours 2 134
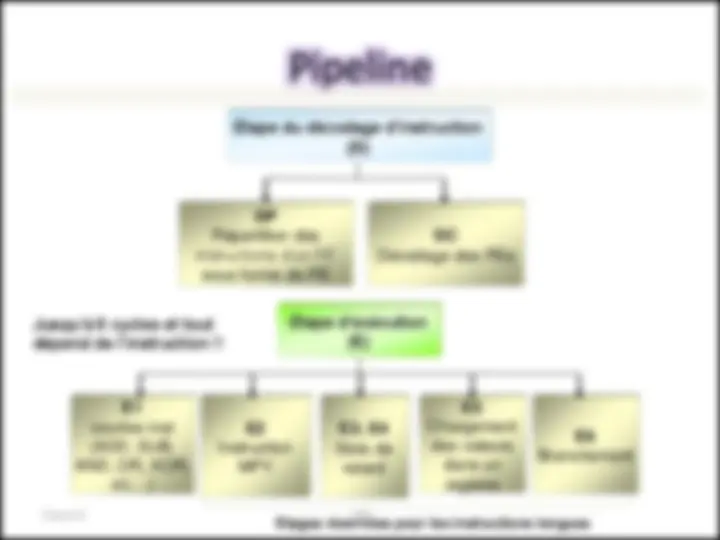
Jusqu’à 6 cycles et tout dépend de l’instruction !!
DP Répartition des instructions d’un PF sous forme de PE
DC Décodage des PEs
E courtes inst (ADD, SUB, AND, OR, XOR, etc…)
E Instruction MPY
E3; E Slots de retard
E Branchement
E Chargement des valeurs dans un registre
Etages réservées pour les instructions longues
Étape d’exécution (E)
Étape du décodage d’instruction (D)
135
31 0 p Instruction A
31 0 p Instruction B
31 0 p Instruction C
31 0 p Instruction D
31 0 p Instruction E
31 0 p Instruction F
31 0 p Instruction G
31 0 p Instruction H
137
Spécification des groupes d’instructions
exécutables en parallèle
exécutés en parallèle avec l’instruction précédente.
Instruction A
1
31 0 1
31 0 0
31 0 0
31 0 1
31 0 0
31 0 1
31 0 0
31 0
Instruction B Instruction C Instruction D Instruction E Instruction F Instruction G Instruction H
Cours 1 138
Spécification des groupes d’instructions
exécutables en parallèle
Exemple d’un paquet fetch contenant 3 paquets exécutables
Cours 2 140
Une seule INSTRUCTION par cycle entre dans le pipeline en arrivant à l’étape DC ( Decode ) :
PF DP DC E1 E2 E3 E4 E5 E
PF (^) Decode Execute Done
B MVK ADD ADD MPY MPY LDW LDB
PF
B .S MVK .S ADD .L ADD .L MPY .M MPY .M LDW .D LDB .D
Cours 2 141
PF DP DC E1 E2 E3 E4 E5 E
PF (^) Decode Execute Done
B MVK
+ + + + + +
ADD ADD MPY MPY LDW LDB
PF
Cours 2 143
PF DP DC E1 E2 E3 E4 E5 E
PF (^) Decode Execute Done
B MVK
+ + + + + + +
ADD ADD MPY MPY LDW LDB
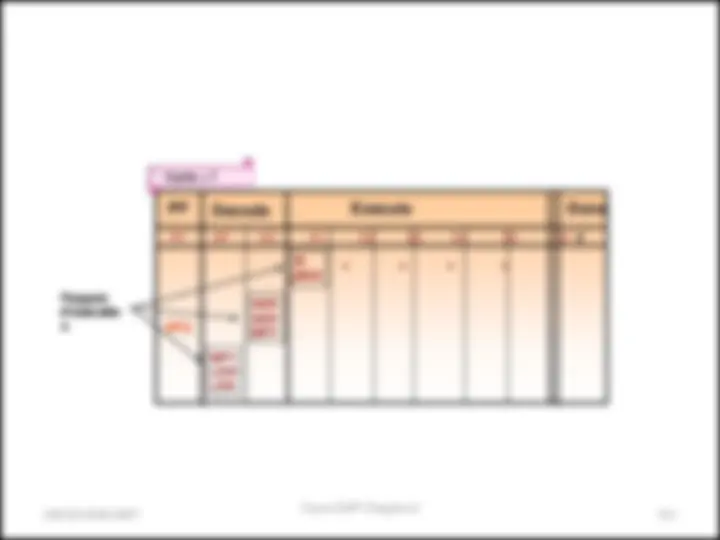
Paquets d’exécution
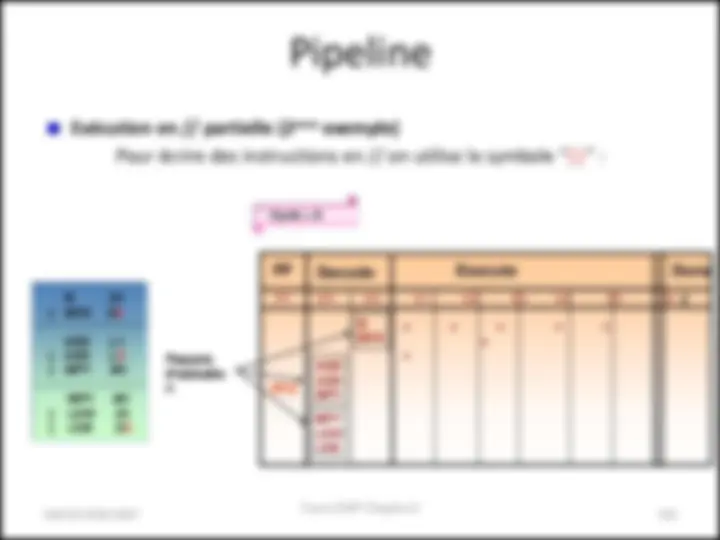
Comment écrire des instructions en //?
On utilise le symbole “ || ” :
B .S
ADD .L
MPY .M || LDW .D
PF
Cours 2 144
PF DP DC E1 E2 E3 E4 E5 E
PF (^) Decode Execute Done
B MVK
+ + + + +
ADD ADD MPY MPY LDW LDB
Paquets d’exécution (^) PF
Pipeline