Download Direct and Indirect Interconnection - Parallel Processing - Lecture Slides and more Slides Parallel Computing and Programming in PDF only on Docsity!
Lecture 4: Direct and Indirect Interconnection Networks for Distributed-Memory Multiprocessors
Interconnection Networks
for Parallel Computers
- Interconnection networks carry data between processors and to memory.
- Interconnects are made of switches and links (wires, fiber).
- Interconnects are classified as static or dynamic.
- Static networks consist of point-to-point communication links among processing nodes and are also referred to as direct networks.
- Dynamic networks are built using switches and communication links. Dynamic networks are also referred to as indirect networks.
Interconnection Networks
- Switches map a fixed number of inputs to outputs.
- The total number of ports on a switch is the degree of the switch.
- The cost of a switch grows as the square of the degree of the switch, the peripheral hardware linearly as the degree, and the packaging costs linearly as the number of pins.
Interconnection Networks:
Network Interfaces
- Processors talk to the network via a network interface.
- The network interface may hang off the I/O bus or the memory bus.
- The relative speeds of the I/O and memory buses impact the performance of the network.
Network Topologies: Buses
- Some of the simplest and earliest parallel machines used buses.
- All processors access a common bus for exchanging data.
- The distance between any two nodes is O(1) in a bus. The bus also provides a convenient broadcast media.
- However, the bandwidth of the shared bus is a major bottleneck.
- Typical bus based machines are limited to dozens of nodes. Sun Enterprise servers and Intel Pentium based shared-bus multiprocessors are examples of such architectures.
Network Topologies: Buses
Bus-based interconnects (a) with no local caches; (b) with local memory/caches. Since much of the data accessed by processors is local to the processor, a local memory can improve the performance of bus-based machines.
Network Topologies: Crossbars
- The cost of a crossbar of p processors grows as O(p^2 ).
- This is generally difficult to scale for large values of p.
- Examples of machines that employ crossbars include the Sun Ultra HPC 10000 and the Fujitsu VPP500.
Network Topologies:
Multistage Networks
- Crossbars have excellent performance scalability but poor cost scalability.
- Buses have excellent cost scalability, but poor performance scalability.
- Multistage interconnects strike a compromise between these extremes.
Network Topologies: Multistage Omega Network
- One of the most commonly used multistage interconnects is the Omega network.
- This network consists of log p stages, where p is the number of inputs/outputs.
- At each stage, input i is connected to output j if:
Essentially, j is the rotate-left operation of the bit-repr. of i
Network Topologies: Multistage Omega Network
Each stage of the Omega network implements a perfect shuffle as follows:
A perfect shuffle interconnection for eight inputs and outputs.
Network Topologies: Multistage Omega Network
A complete omega network connecting eight inputs and eight outputs. An omega network has p/2 × log p switching nodes, and the cost of such a network grows as (p log p).
A complete Omega network with the perfect shuffle interconnects and switches can now be illustrated:
Network Topologies:
Multistage Omega Network – Routing
- Let s be the binary representation of the source and d be that of the destination processor.
- The data traverses the link to the first switching node. If the most significant bits of s and d are the same, then the data is routed in pass-through mode by the 1 ’st level switch else, it switches to crossover.
- If the j’th bits (counting from the left) of s and d are the same, then data is routed in pass- through mode by the ((log P)-j)’th level switchDocsity.com
Network Topologies:
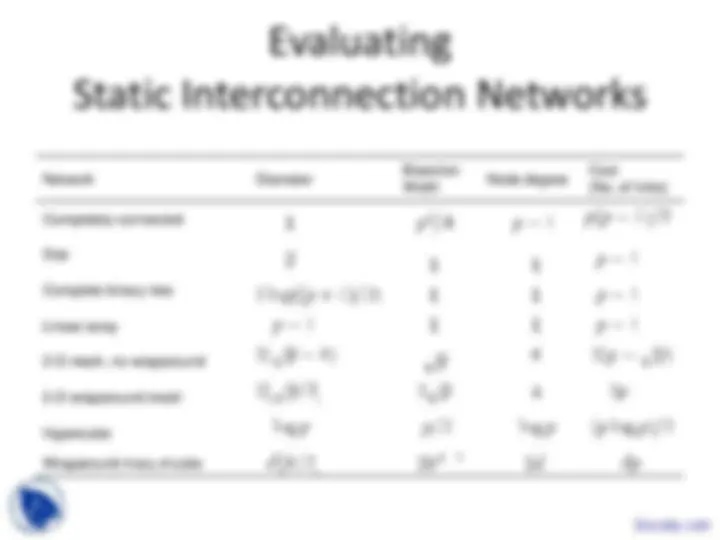
Completely Connected Network
- Each processor is connected to every other processor.
- The number of links in the network scales as O(p^2 ).
- While the performance scales very well, the hardware complexity is not realizable for large values of p.
- In this sense, these networks are static counterparts of crossbars.
Network Topologies: Completely Connected and Star Connected Networks
Example of an 8-node completely connected network.
(a) A completely-connected network of eight nodes; (b) a star connected network of nine nodes.