



18: Distributed Coordination 1
OPERATING SYSTEMS
Distributed Coordination
Docsity.com























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
During the course of work of the Operating Systems, Distributed Computation, we learn the core of the programming. The main points disucss in these lecture slides are:Distributed Coordination, Event Ordering, Mutual Exclusion, Atomicity, Concurrency Control, Deadlock Handling, Election Algorithms, Reaching Agreement, Tightly Coupled Systems, Distributed Systems, Synchronization
Typology: Slides
1 / 31

This page cannot be seen from the preview
Don't miss anything!
18: Distributed Coordination 1
18: Distributed Coordination 2
18: Distributed Coordination 4
COORDINATION
"Happening before" vs. concurrent.
then set LC( B ) = LC( A ) + 1.
Event Ordering
18: Distributed Coordination 5
COORDINATION
Event Ordering
P
o
o
o
o
o
Q 0
Q
o
o
o
o
o
R 0
R
o
o
o
o
o
Time
18: Distributed Coordination 7
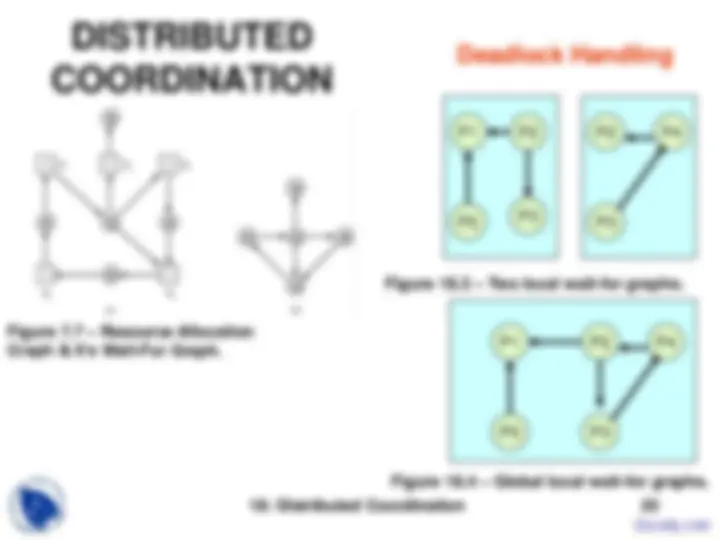
DISTRIBUTED COORDINATION
request, reply, release.
Mutual Exclusion/
Synchronization
18: Distributed Coordination 8
COORDINATION
Approach due to Lamport. These are the general properties for the method:
a) The general mechanism is for a process P[i] to send a request ( with ID and time stamp ) to all other processes.
b) When a process P[j] receives such a request, it may reply immediately or it may defer sending a reply back.
c) When responses are received from all processes, then P[i] can enter its Critical Section.
d) When P[i] exits its critical section, the process sends reply messages to all its deferred requests.
Mutual Exclusion/
Synchronization
18: Distributed Coordination 10
COORDINATION
The Fully Distributed Approach assures:
a) Mutual exclusion b) Freedom from deadlock c) Freedom from starvation, since entry to the critical section is scheduled according to the timestamp ordering. The timestamp ordering ensures that processes are served in a first-come, first-served order. d) 2 X ( n - 1 ) messages needed for each entry. This is the minimum number of required messages per critical-section entry when processes act independently and concurrently.
Problems with the method include:
a) Need to know identity of everyone in system. b) Fails if anyone dies - must continually monitor the state of all processes. c) Processes are always coming and going so it's hard to maintain current data.
Mutual Exclusion/
Synchronization
18: Distributed Coordination 11
COORDINATION
Tokens with rings
No starvation if the ring is unidirectional.
There are many messages passed per section entered if few users want to get in section.
Only one message/entry if everyone wants to get in.
Mutual Exclusion/
Synchronization
18: Distributed Coordination 13
Starting the execution of a transaction.
Breaking the transaction into a number of sub transactions, and distributing these sub transactions to the appropriate sites for execution.
Coordinating the termination of the transaction, which may result in the transaction being committed at all sites or aborted at all sites.
COORDINATION
Atomicity
18: Distributed Coordination 14
Two-Phase Commit Protocol (2PC)
COORDINATION
Atomicity
18: Distributed Coordination 16
Two-Phase Commit Protocol (2PC)
Phase 2: Recording the decision in the database
COORDINATION
Atomicity
18: Distributed Coordination 17
Failure Handling in Two-Phase Commit:
Failure of a participating Site:
Failure of the Coordinator Ci:
coordinator Ci cannot have decided to commit T. Rather than wait for Ci to recover, it is preferable to abort T.
this case we must wait for the coordinator to recover. Blocking problem - T is blocked pending the recovery of site Si.
COORDINATION
Atomicity
18: Distributed Coordination 19
Locking Protocols == Single-coordinator approach:
at that site.
COORDINATION
Concurrency Control
18: Distributed Coordination 20
Locking Protocols == Multiple-coordinator approach:
Distributes lock-manager function over several sites.
Majority protocol:
only one data item.
Biased protocol:
COORDINATION
Concurrency Control