



Chord - A Distributed Hash Table
docsity.com











Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Distributed Operating Systems course is designed to examine the fundamental principles of distributed systems, and provide students hands-on experience in developing distributed protocols. This lecture includes: Distributed Hash Table, Peer-To-Peer Systems, Centralized Servers, Distributed Hash Tables, Chord Algorithm, Scalable Key Location, Node Joins
Typology: Slides
1 / 22

This page cannot be seen from the preview
Don't miss anything!
2
4
5
7
6
1
2
0
4
6 2
5
1
3
7
identifier
circle
8
1
2
6
0
4
6 2
5
1
3
7
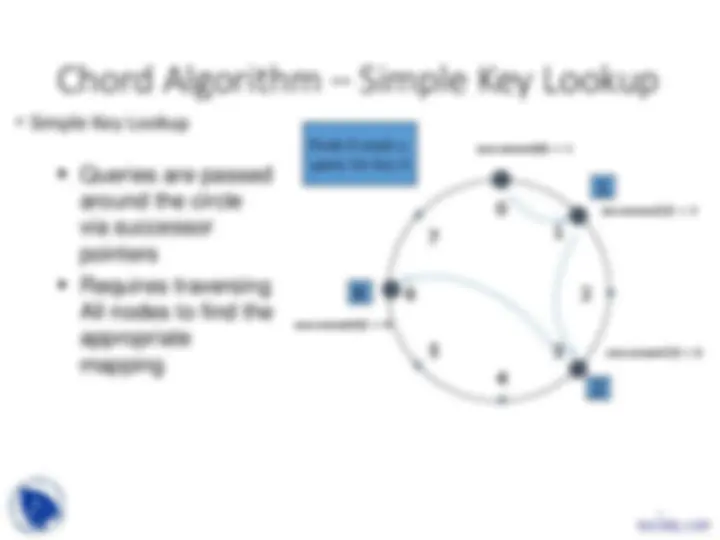
successor(1) = 3
successor(3) = 6
successor(6) = 0
successor(0) = 1
Node 0 sends a
query for key 6
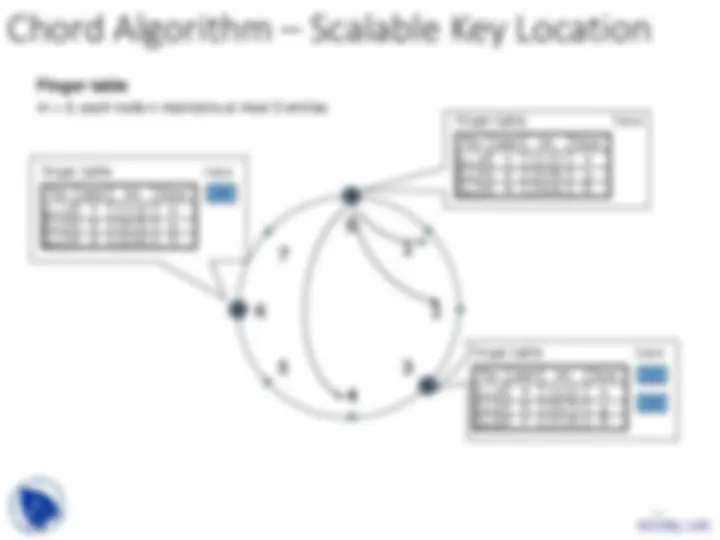
For. start Int. Succ.
10
Finger table
0
4
6 2
5
1
3
7
finger table keys
0+
0
0+
1
0+
2
1
2
4
[1,2) 3
3
6
[2,4)
[4,0)
finger table keys
For. start Int. Succ.
3+
0
3+
1
3+
2
4
5
7
[4,5) 6
6
0
[5,7)
[7,3)
1
2
finger table keys
For. start Int. Succ.
6+
0
6+
1
6+
2
7
0
2
[7,0) 0
0
3
[0,2)
[2,6)
5
11
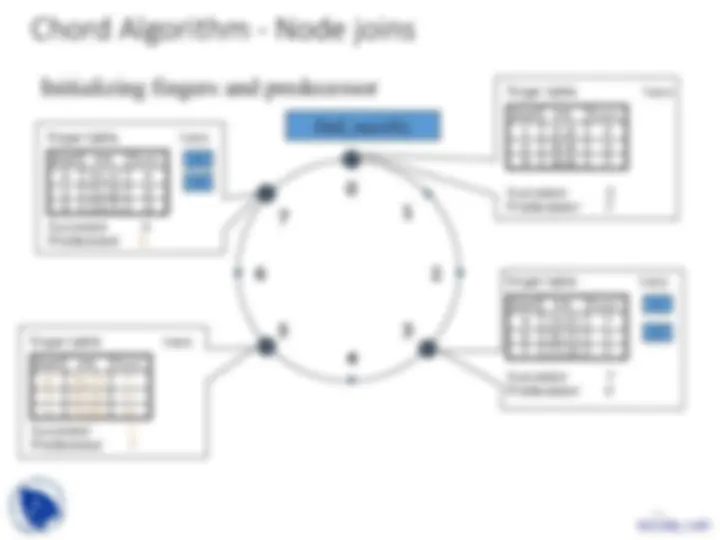
addition of n
associated with keys that node n is now responsible for
13
start Int. Succ.
1 [1,2) 3
2
[2,4) 3
4 [4,0) 7
14
0
4
6 2
5
1
3
7
finger table keys
finger table keys
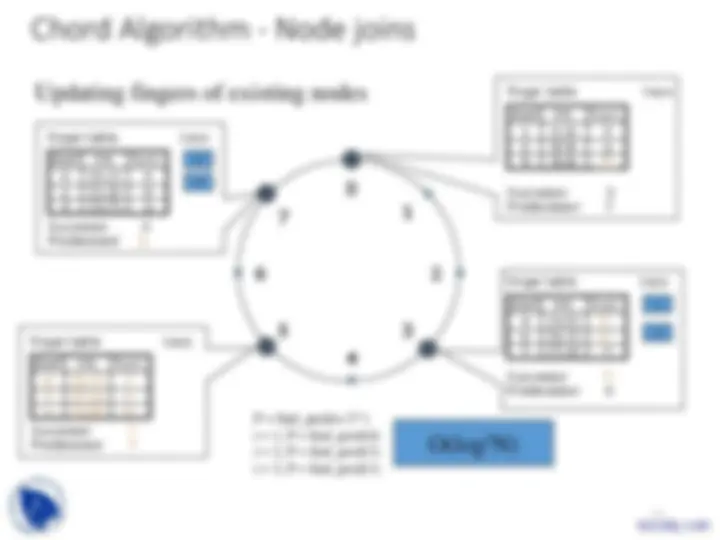
start Int. Succ.
4 [4,5) 7
5 [5,7) 7
7 [7,3) 7
1
2
finger table keys
start Int. Succ.
0 [0,1) 0
1 [1,3) 0
3 [3,7) 3
6
4
Successor 0
Predecessor 3 5
Successor 3
Predecessor 7
Successor 7
Predecessor 0
finger table keys
start Int. Succ.
6 [6,7)
7 [7,1)
1 [1,5)
7
7
3
Successor
Predecessor
7
3
find_succ(6);
start Int. Succ.
1 [1,2) 3
2
[2,4) 3
4 [4,0) 7
16
0
4
6 2
5
1
3
7
finger table keys
5
finger table keys
start Int. Succ.
4 [4,5) 7
5 [5,7) 7
7 [7,3) 7
5
1
2
finger table keys
start Int. Succ.
0 [0,1) 0
1 [1,3) 0
3 [3,7) 3
6
4
Successor 0
Predecessor 3 5
Successor 3
Predecessor 7
Successor 6
Predecessor 0
5
finger table keys
start Int. Succ.
6 [6,7)
7 [7,1)
1 [1,5)
7
7
3
Successor
Predecessor
7
3
5
start Int. Succ.
1 [1,2) 3
2
[2,4) 3
4 [4,0) 7
17
0
4
6 2
5
1
3
7
finger table keys
7
finger table keys
start Int. Succ.
4 [4,5) 7
5 [5,7) 7
7 [7,3) 7
7
1
2
finger table keys
start Int. Succ.
0 [0,1) 0
1 [1,3) 0
3 [3,7) 3
6
4
Successor 0
Predecessor 3 5
Successor 3
Predecessor 7
Successor 6
Predecessor 0
7
finger table keys
start Int. Succ.
6 [6,7)
7 [7,1)
1 [1,5)
7
7
3
Successor
Predecessor
7
3
7
Query without all finger tables been updated
succ(4) = 7
19
distributed hash table
fully distributed
cost of lookup grows logarithmic
automatically adjusts internal tables
no constraints on the structure of the keys
2
2
20