Download Distributed Hash Tables and more Exercises Geometry in PDF only on Docsity!
Distributed Hash Tables
DHTs
● Like it sounds – a distributed hash table
● Put(Key, Value)
● Get(Key) > Value
Last time: Unstructured Lookup
● Pure flooding (Gnutella), TTL limited
– Send message to all nodes
● Supernodes (Kazaa)
– Flood to supernodes only
● Adaptive “super” nodes and other tricks (GIA)
● None of these scales well for searching for
needles
Alternate Lookups
● Keep in mind contrasts to...
● Flooding (Unstructured) from last time
● Hierarchical lookups
– DNS
– Properties? Root is critical. Today's DNS root is
widely replicated, run in serious secure datacenters,
etc. Load is asymmetric.
● Not always bad – DNS works pretty well
● But not fully decentralized, if that's your goal
P2P Requirements
● Scale to those sizes...
● Be robust to faults and malice
● Specific challenges:
– Node arrival and departure – system stability
– Freeloading participants
– Malicious participants
– Understanding bounds of what systems can and
cannot be built on top of p2p frameworks
DHTs
● Two options:
– lookup(key) > node ID
– lookup(key) > data
● When you know the nodeID, you can ask it
directly for the data, but specifying interface as
> data provides more opportunities for caching
and computation at intermediaries
● Different systems do either. We'll focus on the
problem of locating the node responsible for the
data. The solutions are basically the same.
Consistent Hashing
● How can we map a key to a node?
● Consider ordinary hashing
– func(key) % N > node ID
– What happens if you add/remove a node?
● Consistent hashing:
– Map node IDs to a (large) circular space
– Map keys to same circular space
– Key “belongs” to nearest node
154 41 Spring 2004, Jeff Pang 11
DHT: Consistent Hashing
N
N
N
K
K
K
Circular ID space
Key 5
Node 105
A key is stored at its successor: node with next higher ID
154 41 Spring 2004, Jeff Pang 13
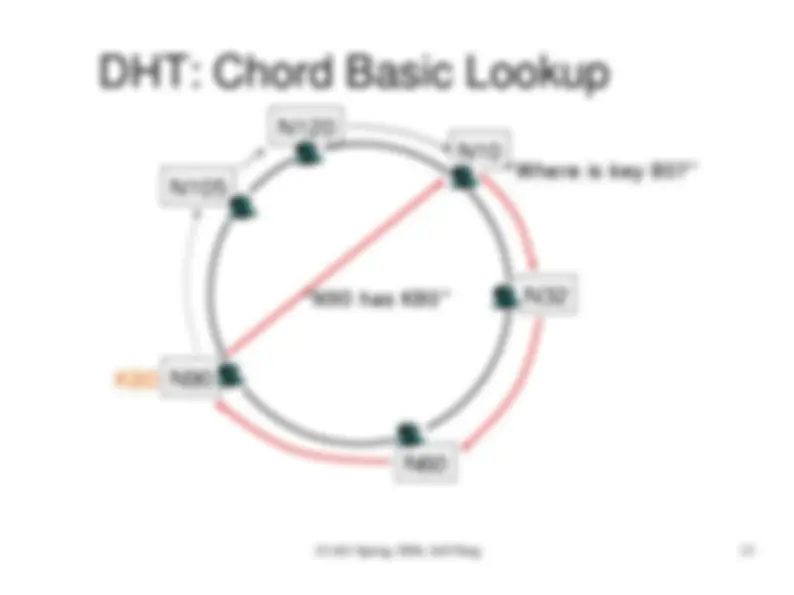
DHT: Chord Basic Lookup
N
N
N
N
N
N
K
“Where is key 80?”
“N90 has K80”
154 41 Spring 2004, Jeff Pang 14
DHT: Chord “Finger Table”
N
1/4^ 1/
- (^) Entry i in the finger table of node n is the first node that succeeds or
equals n + 2i
- (^) In other words, the ith finger points 1/2n^ i^ way around the ring
154 41 Spring 2004, Jeff Pang 16
DHT: Chord Join
• Node n2 joins
i id+2i^ succ 0 2 2 1 3 1 2 5 1
Succ. Table
i id+2i^ succ 0 3 1 1 4 1 2 6 1
Succ. Table
154 41 Spring 2004, Jeff Pang 17
DHT: Chord Join
• Nodes n0, n6 join
i id+2i^ succ 0 2 2 1 3 6 2 5 6
Succ. Table
i id+2i^ succ 0 3 6 1 4 6 2 6 6
Succ. Table
i id+2i^ succ 0 1 1 1 2 2 2 4 0
Succ. Table
i id+2i^ succ 0 7 0 1 0 0 2 2 2
Succ. Table
154 41 Spring 2004, Jeff Pang 19
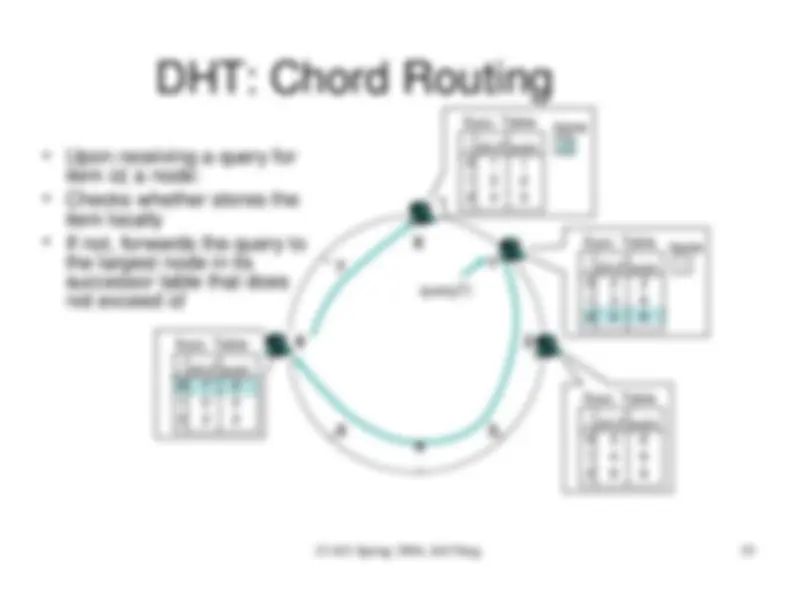
DHT: Chord Routing
- (^) Upon receiving a query for
item id, a node:
- (^) Checks whether stores the
item locally
- (^) If not, forwards the query to
the largest node in its
successor table that does
not exceed id
7 i id+2i^ succ
Succ. Table
i id+2i^ succ 0 3 6 1 4 6 2 6 6
Succ. Table
i id+2i^ succ 0 1 1 1 2 2 2 4 0
Succ. Table 7
Items 1
Items
i id+2i^ succ 0 7 0 1 0 0 2 2 2
Succ. Table
query(7)
154 41 Spring 2004, Jeff Pang 20
DHT: Chord Summary
• Routing table size?
– Log N fingers
• Routing time?
– Each hop expects to 1/2 the distance to the
desired id => expect O(log N) hops.