Download Framework for Parallel Processing: Shared Address Space and Message Passing Models and more Slides Advanced Computer Architecture in PDF only on Docsity!
Framework for Parallel processing
The framework for parallel architecture
is defined as a two layer representation
These layers define Programming and
Communication Models
These models present sharing of
address space and message passing
in parallel architecture
Framework for Parallel processing
The shared address space model at:
- The communication layer, defines the
communication via memory to handle
load, store, and etc.; and at
- The programming layer, it defines
handling several processors operating
on several data sets simultaneously;
and to exchange information globally
and simultaneously
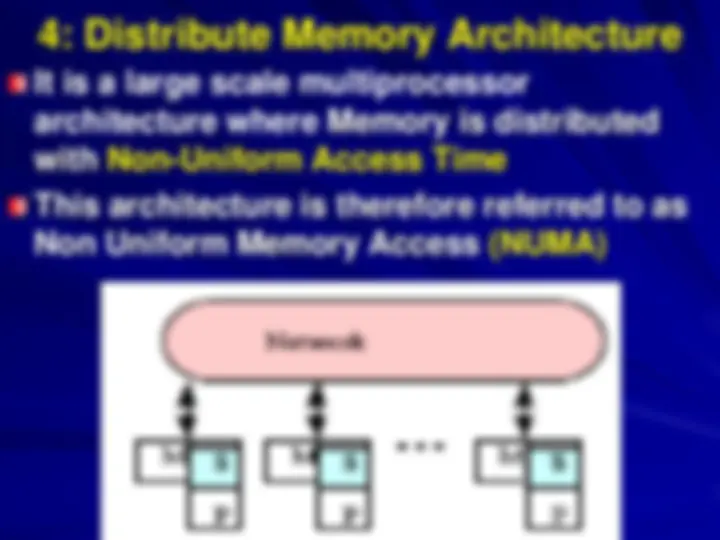
Shared Address Space Architecture (for Decentralized Memory Architecture)
Shared Address space is referred to as
the Distributed Shared Memory – DSM
where, each processor can name every
physical location in the machine; and
each process can name all data it
shares with other processes
Data transfer takes place via load and
store
Shared Address Space Architecture
(for Decentralized Memory Architecture)
Data size is defined as: byte, word, ... or cache blocks
Uses virtual memory to map virtual to local or remote physical
Processes on multiple processors are time shared
Multiple private address spaces offer message passing multicomputer via separate address space
Shared Address Space Architecture Programming Model
The programming model defines how
to share code, private stack, some
shared heap, some private heap
Here, Process is defined as virtual
address space plus one or more
threads of control
Shared Address Space Architecture Programming Model
Multiple processes can overlap, but ALL threads share a process address space, i.e., portions of address spaces of processes are shared; and
writes to shared address space by one thread are visible to reads of all threads in other processes as well
There exist number of shared address space architectures
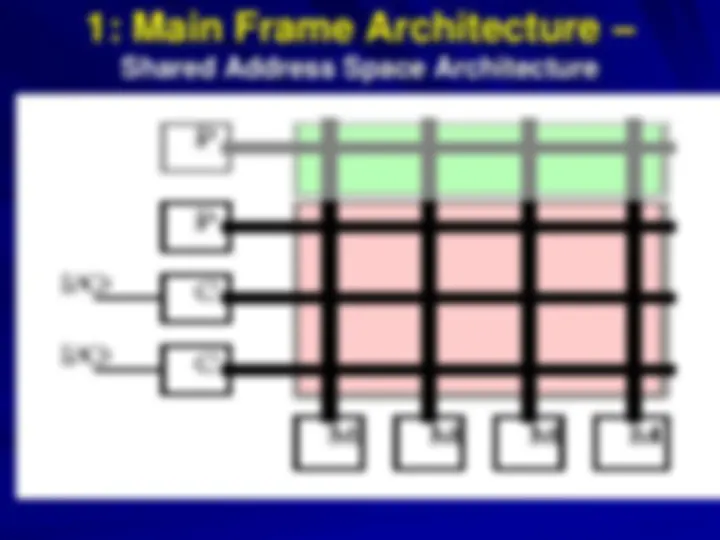
1: Main Frame Architecture –
Shared Address Space Architecture
1: Main Frame Architecture .. Cont’d
The main frame architecture was motivated by multiprogramming
As shown here, it extends crossbar for processor interface to memory modules and I/O
Initially this architecture was limited by processor cost; but, later by the cost of crossbar
IBM S/390 (now z-Server) is typical example of cross-bar architecture
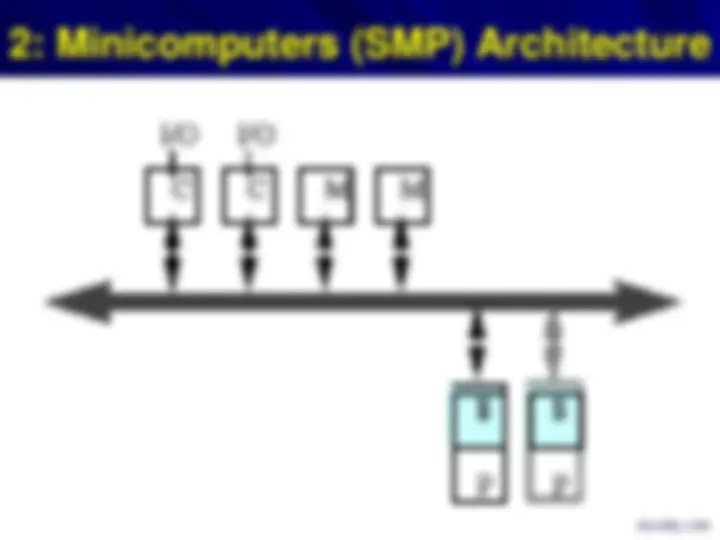
2: Minicomputers (SMP) Architecture
2: Minicomputers (SMP) Architecture
However, the bus is bandwidth bottleneck as sharing is limited by Bandwidth when we add processors, I/O
Furthermore, caching is key to the coherence problem – we will talk about this later
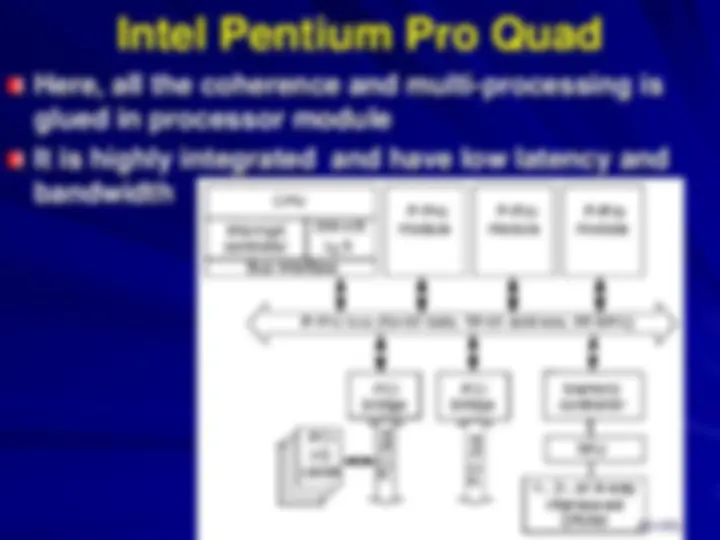
The typical example of SMP architecture is Intl Pentium Pro Quad
3: Dance Hall Architecture
All processors are on one side of the network and all memories on the other side
3: Dance Hall Architecture
As we have notice that in the cross-bar architecture the major cost is of interconnect and in SMPs bus bandwidth is the bottleneck
This architecture offers solution to both the problems through its scalable interconnect network where the bandwidth is scalable
However, the interconnect network has larger access latency; and
caching is key to the coherence problem