



Instruction Scheduling
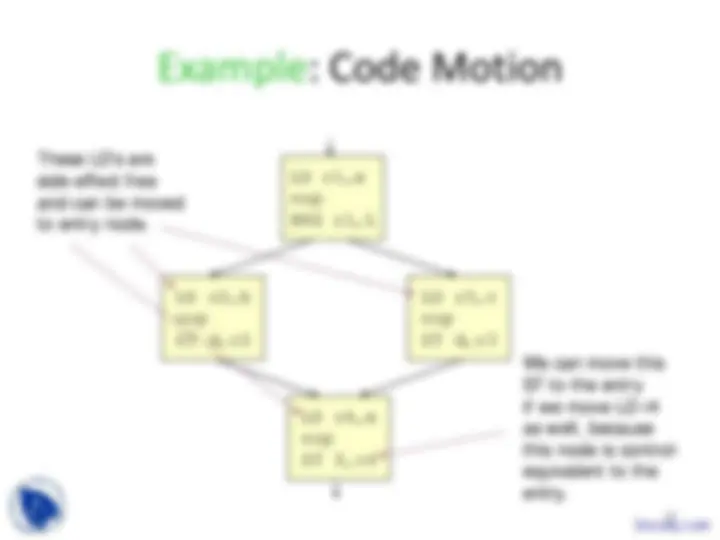
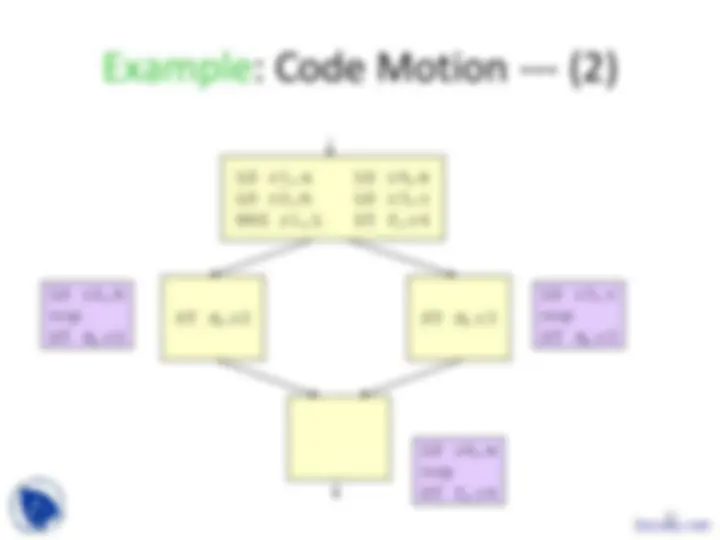
Increasing Parallelism
Basic-Block Scheduling
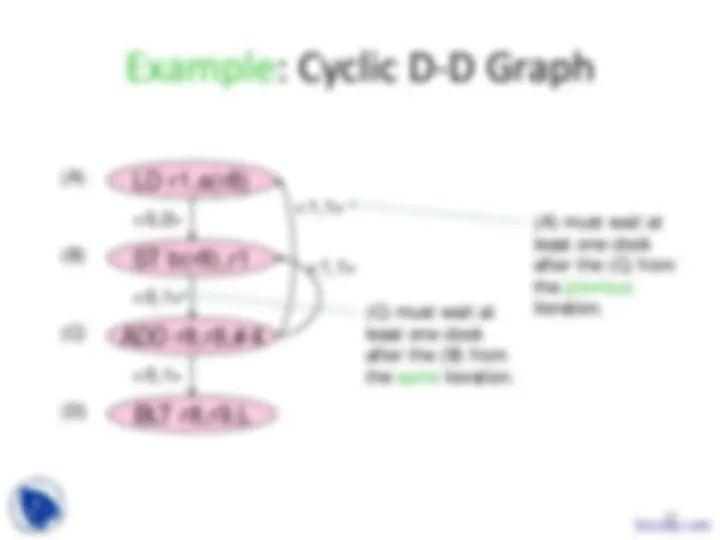
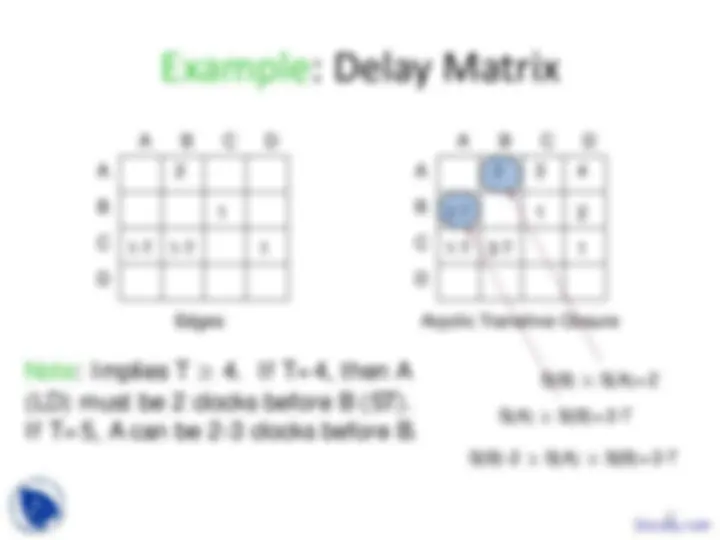
Data-Dependency Graphs
1
Docsity.com



































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
An overview of instruction scheduling techniques, focusing on increasing parallelism through basic block scheduling and data-dependence graphs. It covers the register/parallelism tradeoff, rules for instruction scheduling, kinds of data dependence, and eliminating data dependences. The document also introduces the concept of global code motion and discusses upwards and downwards code motion. Lastly, it touches upon software pipelining and its limitations.
Typology: Slides
1 / 48

This page cannot be seen from the preview
Don't miss anything!
4
a = b+c e = a+d a = b-c f = a+d
a = b+c e = a+d a = b-c f = a+d
a1 = b+c e = a1+d a2 = b-c f = a2+d
a1 = b+c a2 = b-c e = a1+d f = a2+d
Assume 2 arithmetic operations per instruction
Don’t reuse a
5
13
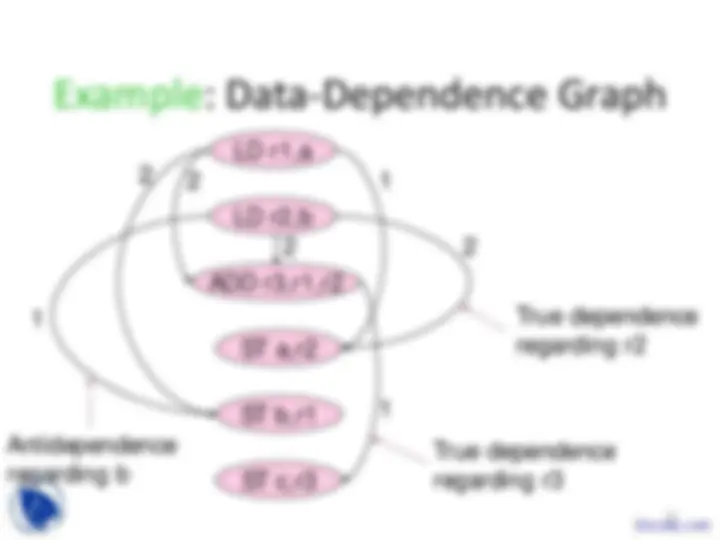
LD r1,a
LD r2,b
ADD r3,r1,r
ST a,r
ST b,r
ST c,r
True dependence regarding r
Antidependence regarding b
True dependence regarding r
16
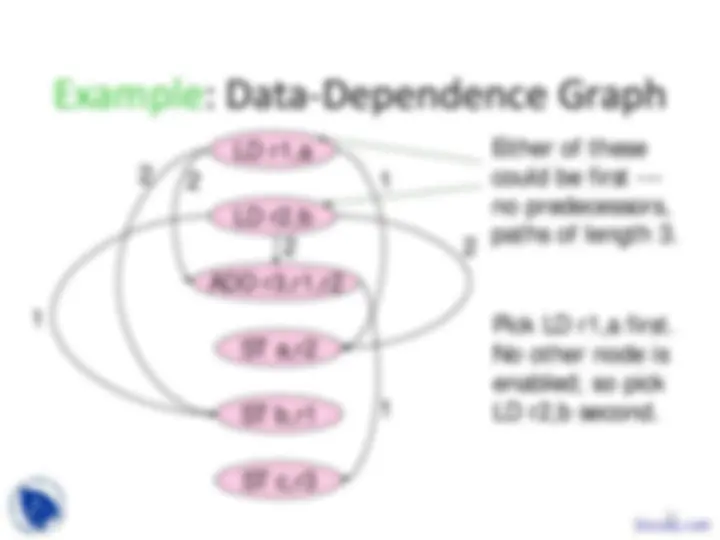
LD r1,a
LD r2,b
ADD r3,r1,r
ST a,r
ST b,r
ST c,r
Now, these three are enabled. Pick the ADD, since it has the longest path extending.
17
LD r1,a
LD r2,b
ADD r3,r1,r
ST a,r
ST b,r
ST c,r
These three can now occur in any order. Pick the order shown.
19
LD r1,a: clock 1 earliest. MEM available.
LD r1,a
20
LD r2,b: clock 1 earliest. MEM not available. Delay to clock 2.
LD r1,a LD r2,b