



Part V
Some Broad Topic
Docsity.com




























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Some concept of Parallel Processing are Anatomy, Cache Access Time, Instruction Formats, Instruction Formats, Instruction Formats, Multidimensional Meshes, Network Processors, Snooping Protocol. Main points of this lecture are: Some Broad Topic, Emulations Among Architectures, Distributed Shared Memory, Task Scheduling Problem, Class of Scheduling Algorithms, Useful Bounds For Scheduling, Load Balancing, Dataflow Systems, Scheduling, Parallel Systems
Typology: Slides
1 / 96

This page cannot be seen from the preview
Don't miss anything!
Topics in This Part Chapter 17 Emulation and Scheduling Chapter 18 Data Storage, Input, and Output Chapter 19 Reliable Parallel Processing Chapter 20 System and Software Issues
Study topics that cut across all architectural classes:
17.1 Emulations Among Architectures
Usefulness of emulation:
a. Develop algorithms quickly for a new architecture b. Program on a user-friendly architecture, then emulate it c. Show versatility of a new architecture by emulating the hypercube on it
Two general emulation results:
EREW PRAM can emulate any degree- d network with slowdown O( d )
Load factor = p /
Congestion = p^2 / Dilation = 1
Versatility of the Butterfly Network
Fig. 17.1 Converting a routing step in a degree- network to three permutations or perfect matchings.
0
1
2 3
u (^) 0
u (^) 1
u (^) 2
u (^) 3
v (^) 0
v (^) 1
2
v (^) 3
v
u (^) 0
u (^) 1
u (^) 2
u (^) 3
v (^) 0
v (^) 1
2
v (^) 3
v
0 0
0
0
0 0
0
0
1
1 1
1
1
1 1
1
2
2 2
2
2
2 2 2
u (^) 3 v 3
u (^) 0
u (^) 1
u (^) 2
u
v (^) 0
v (^) 1
2
v
v
u (^) 0
u (^) 1
u (^) 2
v (^) 0
v (^) 1
v 2
u (^) 0
u (^) 1
u (^) 2
u
v (^) 0
v (^) 1
2
v
v
3 3 3 3
A (wrapped) butterfly can emulate any degree- d network with O( d log p ) slowdown
Thus, butterfly is a bounded-degree network that is universally efficient
Idea used in proof: One communication step in a degree- d network can be decomposed into at most d permutation routing steps
PRAM Emulation with Butterfly MIN
Less efficient than Fig. 17.2, which uses a smaller butterfly
Fig. 17.3 Distributed-memory machine, with a butterfly multistage interconnection network, emulating the PRAM.
dim (^0) dim 1 dim (^2) M
(^0) q + 1 Columns 1 2 3
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
2 Rowsq
One of p =2processors P q (^) Memory module holding m/p memory locations
Emulation of the p -processor PRAM on ( p log p )-node butterfly, with memory modules and processors connected to the two sides; O(log p ) avg. slowdown
By using p / (log p ) physical processors to emulate the p -processor PRAM, this new emulation scheme becomes quite efficient (pipeline the memory accesses of the log p virtual processors assigned to each physical processor)
Deterministic Shared-Memory Emulation
Deterministic emulation of p -processor PRAM on p -node butterfly
dim 0 (^) dim 1 dim 2
(^0 1) q + 1 Columns 2 3
0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7
2 Rowsq
One of p = processors
q Memory moduleholding m/p memory locations
P M P M P M P M
Each node = router + processor + memory
2 (q + 1)
Store log 2 m copies of each of the m memory location contents
Time-stamp each updated value
A “write” is complete once a majority of copies are updated
A “read” is satisfied when a majority of copies are accessed and the one with latest time stamp is used
Why it works: A few congested links won’t delay the operation
Write set Read set log 2 m copies
17.3 The Task Scheduling Problem
Task scheduling parameters and “goodness” criteria
Running times for tasks Creation (static / dynamic) Importance (priority) Relationships (precedence) Start times (release times) End times (deadlines)
Fig. 17.5 Example task system showing communications or dependencies.
1
2
3
4 5 (^76)
8
(^109) 11
x
x
x
y
Vertex v represents Task or Computation j
T Latency with p processors T Number of nodes (here 13) T Depth of the graph (here 8)
Output
1
2
3
1
p 1
j
12
13
Vertex v represents task or computation^ j^ j
T Latency with p processors T Number of nodes (here 13) T (^) ∞^1 Depth of the graph (here 8)
p
Output
Types of scheduling algorithms
Preemptive/nonpreemptive, fine/medium/coarse grain
Job-Shop Scheduling
0 2 4 6 8 10 12 14 Time
0
2
4
S^6 t a f f
8
Tb1 Tc
Ta
Ta
Tb
Td
Tb
Td
Job Task Machine Time Staff Ja Ta1 M1 2 3 Ja Ta2 M3 6 2 Jb Tb1 M2 5 2 Jb Tb2 M1 3 3 Jb Tb3 M2 3 2 Jc Tc1 M3 4 2 Jd Td1 M1 5 4 Jd Td2 M2 2 1
M1 M2 M 0 2 4 6 8 10 12 14 Time
0
2
4
S^6 t a f f
8
Tb
Tc Ta
Ta
Tb
Td
Tb
Td
Complexity of Scheduling Problems
Most scheduling problems, even with 2 processors, are NP-complete
Easy, or tractable (polynomial-time), cases include:
Surprisingly hard, or intractable, cases include:
Many practical scheduling problems are solved by heuristics
Heuristics typically have decision parameters that can be tuned to make them suitable for a particular application context
The scheduling literature is full of different heuristics and experimental studies of their performance in different domains
17.4 A Class of Scheduling Algorithms
With identical processors, list schedulers differ only in priority assignment
List scheduling
Assign a priority level to each task Construct task list in priority order; tag tasks that are ready for execution At each step, assign to an available processor the first tagged task Update the tags upon each task termination
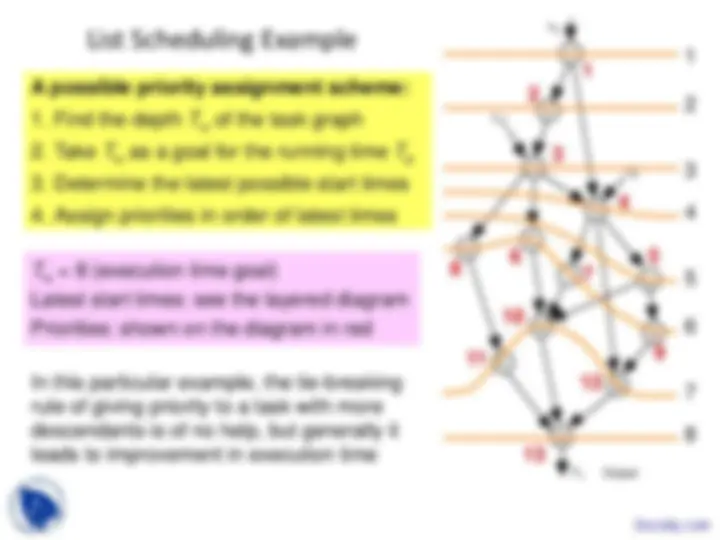
A possible priority assignment scheme for list scheduling:
Assignment to Processors (^1)
2
3
4 5 (^76)
8
(^109)
11
x
x
x
y
Vertex v represents Task or Computation j
T Latency with p proc T Number of nodes (h T Depth of the graph
Output
1
2
3
1
p 1
j
12
13
Vertex v represents task or computation^ j^ j
T Latency with p proce T Number of nodes (h T (^) ∞^1 Depth of the graph (
p
Output
Fig. 17.6 Schedules with p = 1, 2, 3 processors for an example task graph with unit-time tasks.
P 1 1 2 3 4 5 6 7 8 9 10 11 12 13
P 1 P 2
P 3
P 1 P 2
1 2 3 4 6 8 10 12 13 5 7 9 11
1 2 3 4 6 9 12 13 5 7 10 8 11
1 2 3 4 5 6 7 8 9 10 11 12 13 Time Step
Tasks listed in priority order 1* 2 3 4 6 5 7 8 9 10 11 12 13 t = 1 v 1 scheduled 2* 3 4 6 5 7 8 9 10 11 12 13 t = 2 v 2 scheduled
Scheduling with Non-Unit-Time Tasks x
x x
y Output
1
2 3
1
v (^1)
v (^3)
v (^5)
v 2 v^4
v (^6)
Fig. 17.7 Example task system with task running times of 1, 2, or 3 units.
Fig. 17.8 Schedules with p = 1, 2, 3 processors for an example task graph with nonuniform running times.
P 1 1 2 3 4 5 6
P 1
P 2
P 3
P 1
P 2
1 3 4 5 6 2
1 3 5 6
4
1 2 3 4 5 6 7 8 9 10 11 Time Step
2
Proof of Brent’s Theorem: Tp < T ∞ + T 1 / p
Let there be n (^) t nodes scheduled at time t ; Clearly, ∑ t n (^) t = T 1
First assume the availability of an unlimited number of processors and schedule each node at the earliest possible time
With only p processors, tasks scheduled for time step t can be executed in n (^) t / p steps by running them p at a time. Thus:
Tp ≤ ∑ t = 1 to T ∞ n (^) t / p
< ∑ t = 1 to T ∞ ( n (^) t / p + 1) = T ∞ + (∑ t n (^) t )/ p = T ∞ + T 1 / p
1
2
3 4 5 (^76)
8
(^109) 11
x
x
x
y
Vertex v represents Task or Computation j
T Latency with p processors T Number of nodes (here 13) T Depth of the graph (here 8)
Output
1
2
3
1
p 1
j
12
13
Vertex v represents task or computation^ j^ j T Latency with p processors T Number of nodes (here 13) T (^) ∞^1 Depth of the graph (here 8)
p
Output
8
7
6
5
4
3
2
1
n 2 = 1
n 4 = 3
n 6 = 2
n 1 = 1
n 3 = 1
n 5 = 3
n 7 = 1 n 8 = 1
Good-News Corollaries
Brent’s scheduling theorem: Tp < T ∞ + T 1 / p
Ideal run time Ideal speedup
Corollary 1: For p ≥ T 1 / T ∞ we have T ∞ ≤ Tp < 2 T ∞ T 1 / p ≤ T ∞ For a sufficiently large number p of processors, we can come within a factor of 2 of the best possible run time, even when we use a naïve scheduling algorithm
Corollary 2: For p ≤ T 1 / T ∞ we have T 1 / p ≤ Tp < 2 T 1 / p T ∞ ≤ T 1 / p If we do not have too many processors, we can come within a factor of 2 of the best possible speedup, even when we use a naïve scheduling algorithm
Choosing p ≅ T 1 / T ∞ leads to O( p ) speedup and near-minimal run time