


Feb. 2007 Computer Architecture, Data Path and Control Slide 1
Part IV
Data Path and Control





























































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
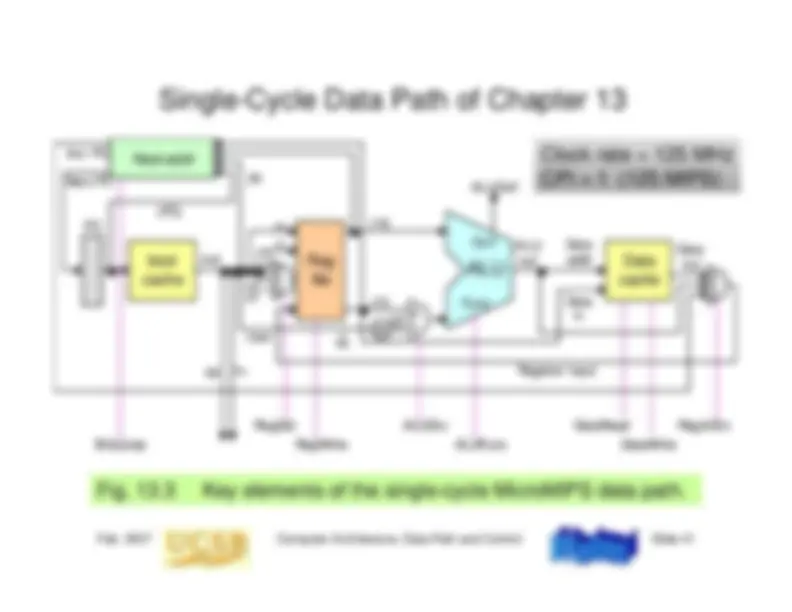
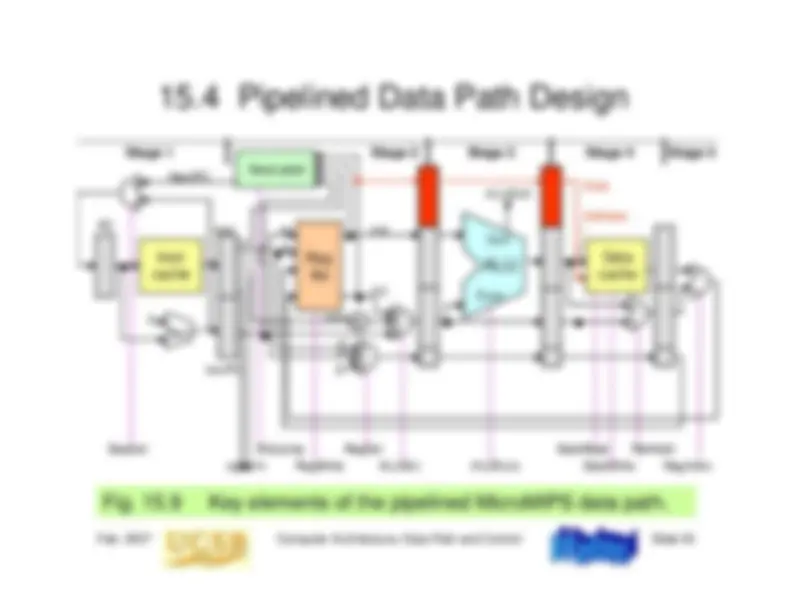
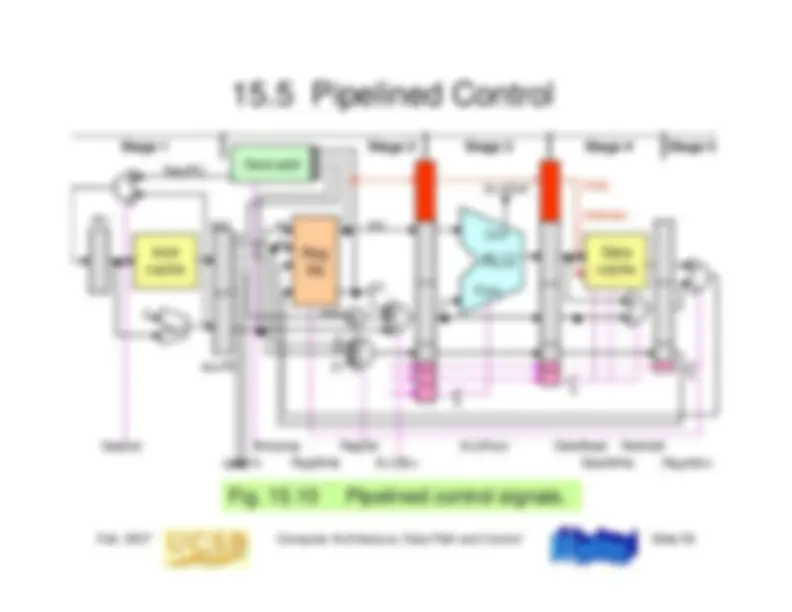
The design and implementation of single-cycle and multicycle data paths in computer architecture, including the control signals, instruction execution steps, and performance estimation. It also discusses pipelining concepts, pipeline stalls or bubbles, and pipelined data path design.
Typology: Study notes
1 / 80

This page cannot be seen from the preview
Don't miss anything!
Feb. 2007
Computer Architecture, Data Path and Control
Slide 1
Feb. 2007
Computer Architecture, Data Path and Control
Slide 2
About This Presentation
Feb. 2007
Computer Architecture, Data Path and Control
Slide 4
Feb. 2007
Computer Architecture, Data Path and Control
Slide 5
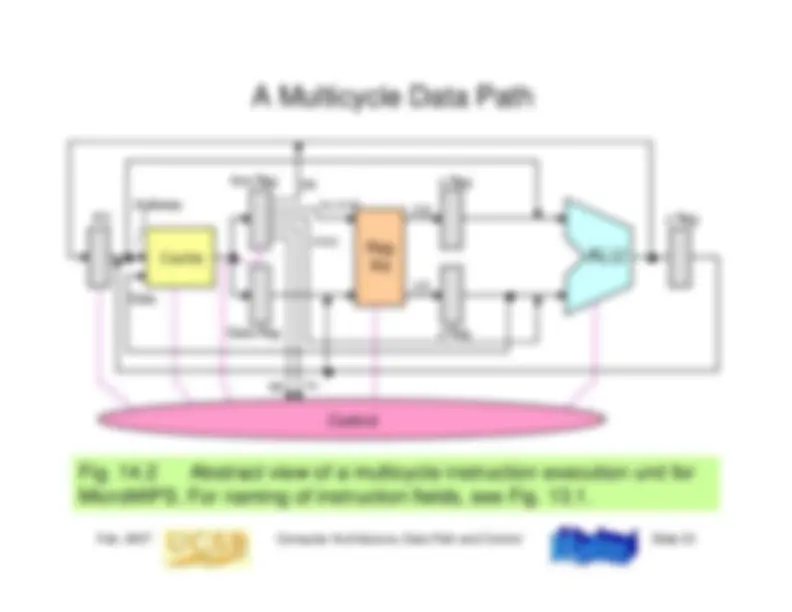
13 Instruction Execution Steps
Feb. 2007
Computer Architecture, Data Path and Control
Slide 7
Load upper immediate
lui
rt,imm
Add
add
rd,rs,rt
Subtract
sub
rd,rs,rt
Set less than
slt
rd,rs,rt
Add immediate
addi
rt,rs,imm
Set less than immediate
slti
rd,rs,imm
AND
and
rd,rs,rt
OR
or
rd,rs,rt
XOR
xor
rd,rs,rt
NOR
nor
rd,rs,rt
AND immediate
andi
rt,rs,imm
OR immediate
ori
rt,rs,imm
XOR immediate
xori
rt,rs,imm
Load word
lw
rt,imm(rs)
Store word
sw
rt,imm(rs)
Jump
j
L
Jump register
jr
rs
Branch less than 0
bltz
rs,L
Branch equal
beq
rs,rt,L
Branch not equal
bne
rs,rt,L
Jump and link
jal
L
System call
syscall
Feb. 2007
Computer Architecture, Data Path and Control
Slide 8
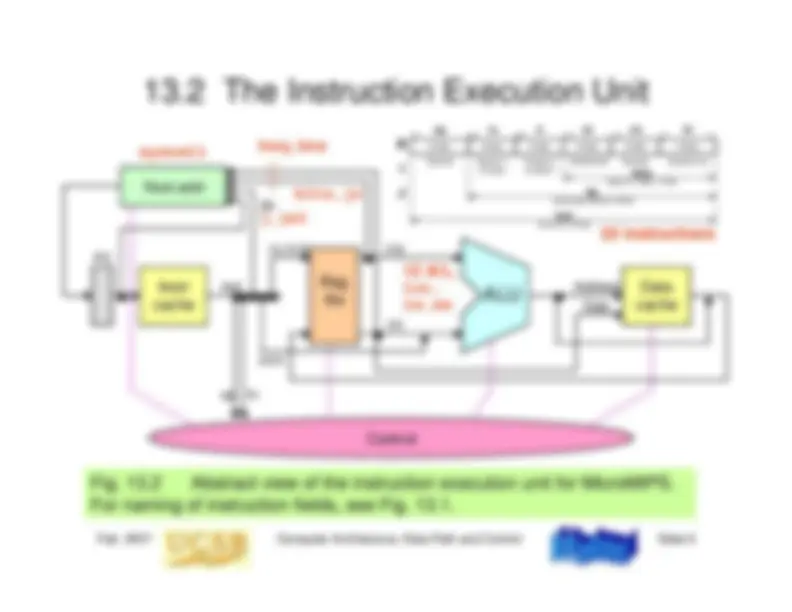
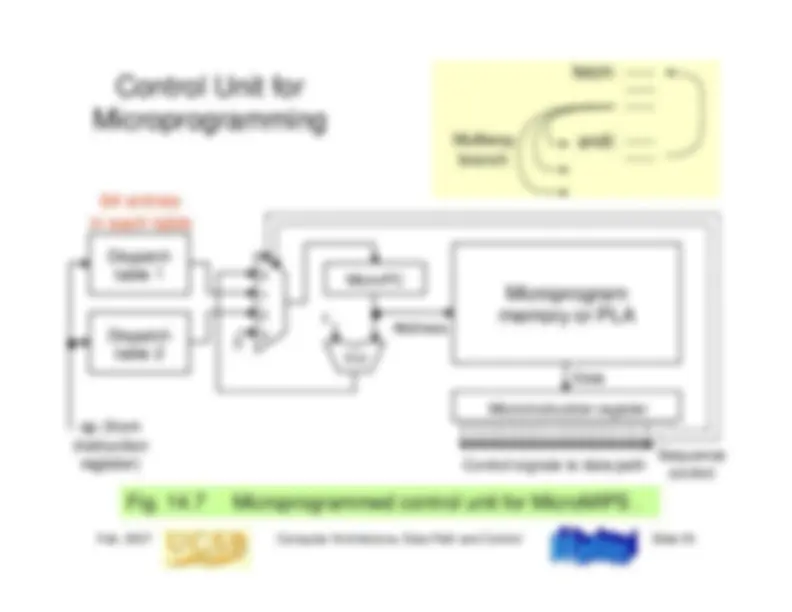
13.2 The Instruction Execution Unit
ALU
Data cache
Instr cache
Next addr
Control
Reg
file
op
jta
fn
inst
imm
rs,rt,rd
(rs) (rt)
Address
Data
PC
5 bits
5 bits
31
25
20
15
0
Opcode
Source 1 or base
Source 2or dest’n
op
rs
rt
R
6 bits
5 bits
rd
5 bits
sh
6 bits
10
5
fn
jta
Jump target address, 26 bits
imm
Operand / Offset, 16 bits
Destination
Unused
Opcode ext
I J
inst
Instruction, 32 bits
Feb. 2007
Computer Architecture, Data Path and Control
Slide 10
Add
′
Sub
x
±
y
x y
Adder
c
c 32
0
k /
Shifter
Logic
unit
s
Logic function
Amount
5
2
ConstantamountVariableamount
5 5
Const
′
Var
0 1
0 1 2 3 Function
class
2
Shift function
5 LSBs
Shifted
y
32
32 32
2 c
^31
32- inputNOR
Ovfl
Zero
32
32
MSB
ALU
x y
s
Shorthand
symbolfor ALU
Ovfl
Zero
Func Control
0 or 1
AND 00
OR 01
XOR 10NOR 11
00 Shift01 Set less10 Arithmetic11 Logic
00 No shift01 Logical left10 Logical right11 Arith right
Feb. 2007
Computer Architecture, Data Path and Control
Slide 11
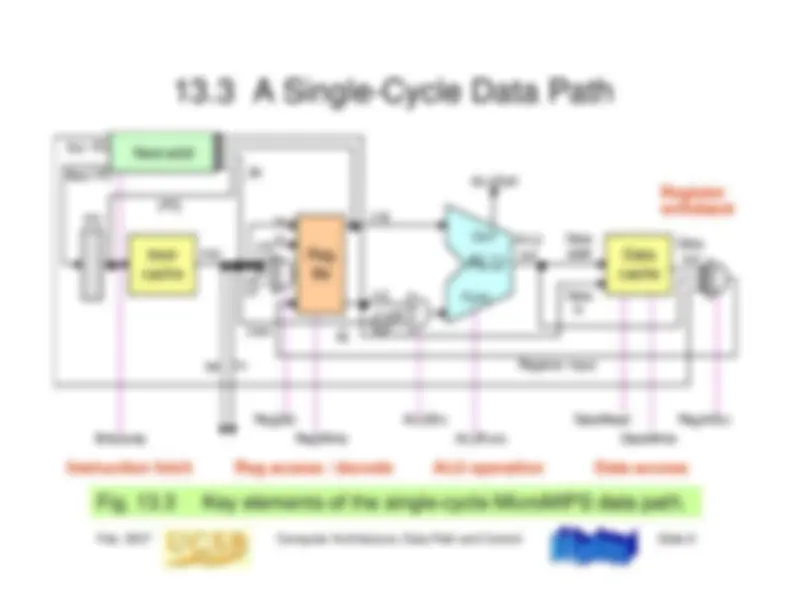
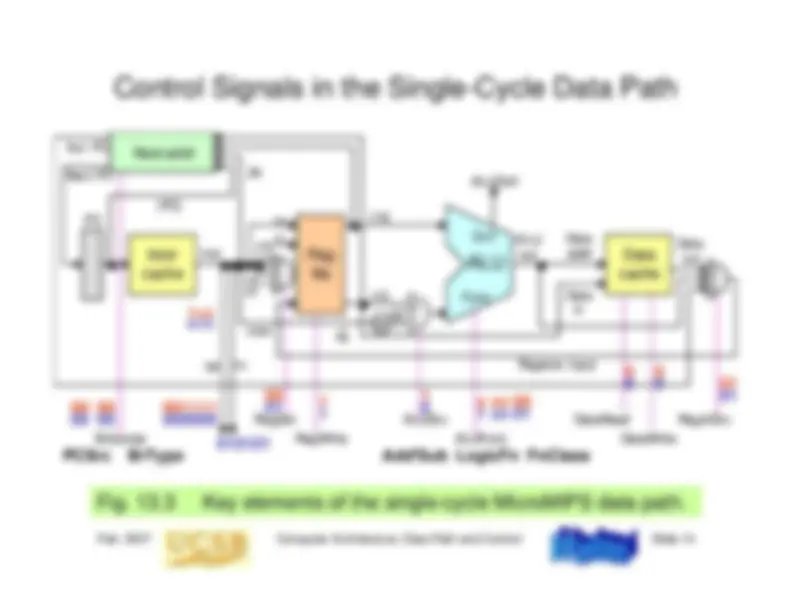
13.4 Branching and Jumping
Adder
jta
imm
(rt)^ (rs)
SE
SysCallAddr
PCSrc
(PC)
Branch
condition checker
in
c 1
0 1 2 3
/ 30
/
32
BrTrue
/
32
/
30
/
30
/
30
/
30
/
30
/
30
/
26
/
30
/
30
4
MSBs
30
MSBs
BrType
IncrPC
NextPC
/
30
31:
16
31:
31:
31:
31:
4 MSBs
Feb. 2007
Computer Architecture, Data Path and Control
Slide 13
Load upper immediateAddSubtractSet less thanAdd immediateSet less than immediateANDORXORNORAND immediateOR immediateXOR immediateLoad wordStore wordJumpJump registerBranch on less than 0Branch on equalBranch on not equalJump and linkSystem call
001111 000000 100000000000 100010000000 101010 001000001010 000000 100100000000 100101000000 100110000000 100111 001100001101001110100011101011000010 000000 001000 000001000100000101000011 000000 001100
1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 1 0
op
fn
0001010100000101010100000000 10
0101010101010101010101010100 10
1 0 0 0 1 1 0 0 0 0 1 1 1 1 1
0 1 1 0 1 0 0
00011011000110
001010011001111111111111111010
0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
000000000000000000000000000000 11011000
00000000000000000000000000000001100000000111
Instruction
RegWrite
RegDst
RegInS rc
ALUSrc
Add’Sub
LogicFn
FnClass
DataRead
DataW rite
BrType
PCSrc
Feb. 2007
Computer Architecture, Data Path and Control
Slide 14
/
Next addr
op
jta
fn
inst
imm
rs
(rs) (rt)
Dataaddr Data
in
0 1
ALUSrc
ALUFunc
DataWrite
DataRead
SE
RegInSrc
rt
rd
RegDst
RegWrite
32
/
16
Register input
Data
out
Func
ALUOvfl Ovfl
31
012
Incr PC Next PC
(PC)
Br&Jump
ALU
out
PC
012
Feb. 2007
Computer Architecture, Data Path and Control
Slide 16
0
addInst
subInst
jInst
sltInst
.. . ..
.
Feb. 2007
Computer Architecture, Data Path and Control
Slide 17
/
ALU
Data cache
Instr cache Next addr
Reg
file
op
jta
fn
inst
imm
rs
(rs) (rt)
Dataaddr Data
in
0 1 ALUSrc
ALUFunc
DataWrite
DataRead
SE
RegInSrc
rt
rd
RegDst
RegWrite
32
/ 16
Register input
Data
out
Func
ALUOvflOvfl
31
012
Incr PC Next PC
(PC)
Br&Jump
ALU
out
PC
012
addInst
subInst
jInst
sltInst
.. . ..
.
Add
′
Sub
x
±
y
x y
Adder c
c 32
^0
k /
Shifter Logic
unit
s
Logic function
Amount
5
2
Cons tantam ountVariableam ount
5 5 Const
′ Var
0 1
0 1 2 3 Function
class
2
Shift function
5 LSBs
Shifted
y
32
32 32
2 c
^31
32- inputNOR
Ovfl
Zero
32
32
MSB
A
x y
Shorth
sym
b
for A
L
Zero
Fu
n
Con
t
0 or 1
AND 00
OR 01 XOR 10NOR 11
00 Shif t01 Set less10 Arithmetic11 Logic
00 No shif t01 Logical lef t10 Logical right11 Arith right
imm
lui
Adder
jta
imm
(rt) (rs)
SE
SysCallAddr
PCSrc
(PC)
Branch conditionchecker
in c 1
0 1 2 3
/ 30
/ 32
BrTrue
/ 32
/ 30
/ 30
/ 30
/ 30
/ 30
/ 30
/ 26
/ 30
/ 30
4
MSBs
30 MSBs
BrType
IncrPC NextPC
/ 30
31:
16
4 MSBs
Feb. 2007
Computer Architecture, Data Path and Control
Slide 19
PC PC PC PC PC
ALU-type Load Store Branch Jump
Not used Not used
Not used
Not used
Not used
Not used Not used Not used
Not used
(and
jr
)
(except jr
&
jal
)
Feb. 2007
Computer Architecture, Data Path and Control
Slide 20