



ENCS5341
Machine Learning and Data Science
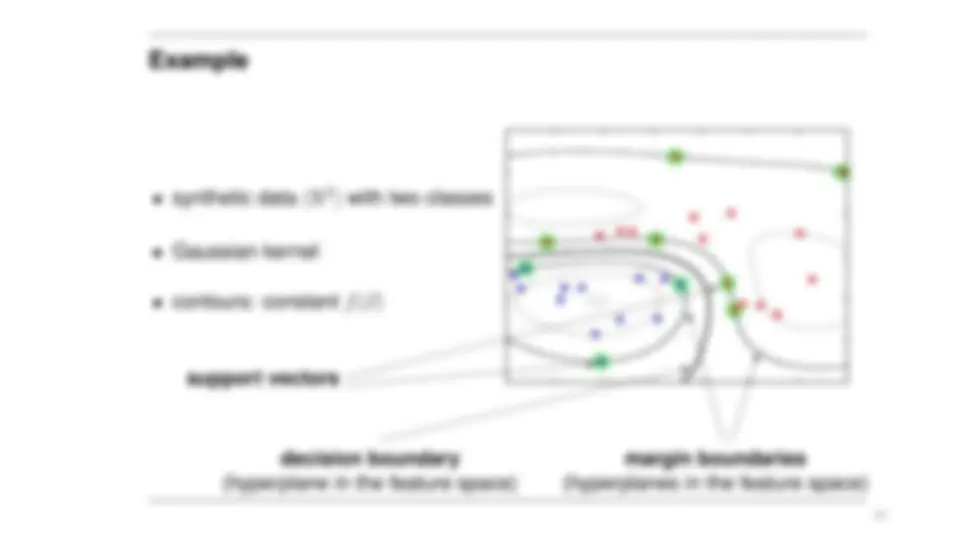
Kernels and SVM
Yaz an Ab u F arh a -Birzeit University
Based on slides prepared by Tam ás Horváth
































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods Machine learning ensemble methods
Typology: Cheat Sheet
1 / 44

This page cannot be seen from the preview
Don't miss anything!
Yazan Abu Farha - Birzeit University Based on slides prepared by Tamás Horváth
() "
) " x 1 x 2 1 2 3 1 2 3