Download Ensemble Methods in Machine Learning and Data Science and more Schemes and Mind Maps Theory of Machines in PDF only on Docsity!
ENCS
Machine Learning and Data Science
Ensemble Methods
Yazan Abu Farha - Birzeit University Some slides are taken from Carlos Guestrin
Introduction
Ensemble Learning
- Ensemble learning uses multiple weak classifiers and combine their predictions to get a stronger model.
- If different models make different mistakes, can we simply average the predictions?
- Voting classifiers: gives every model a vote on the class labels:
- Hard vote: majority class wins.
- Soft vote: average the class probabilities from the different models and select the class with highest average probability.
- Why does this work?
- Different models might be good at different parts of the data.
- Individual mistakes can be averaged out.
- Models must be uncorrelated but good enough (otherwise the ensemble is worse).
Ensemble Learning
Which models should we combine?
- If a model underfits (high bias, low variance), combine with other low variance models
- Need to be different (experts on different parts of the data).
- Bias reduction can be done with Boosting.
- If a model overfits (low bias, high variance) combine with other low bias models
- Need to be different (each model mistakes must be different).
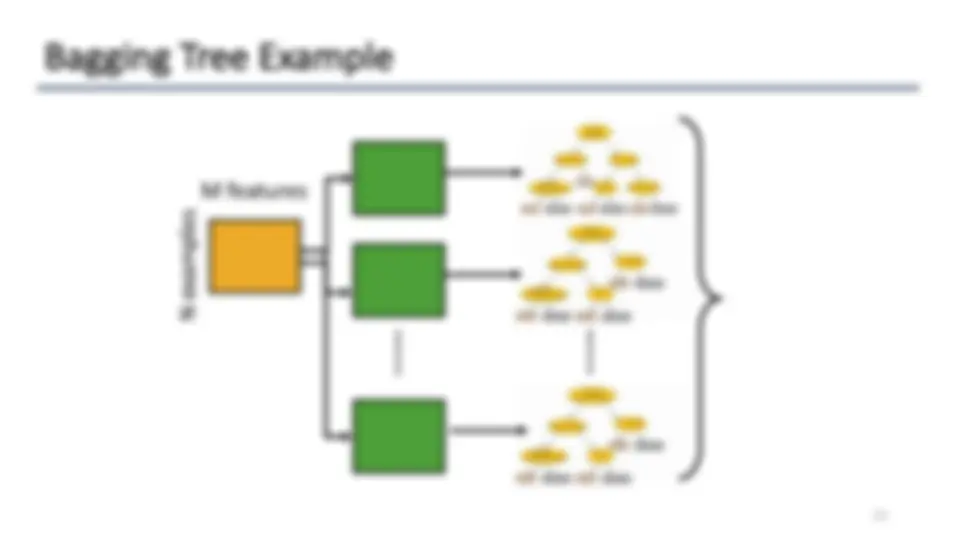
- Variance reduction can be done with Bagging.
For example, shallow trees have high bias and low variance, whereas deep trees have low bias and high
variance.
- We can combine multiple shallow trees via boosting (e.g AdaBoost).
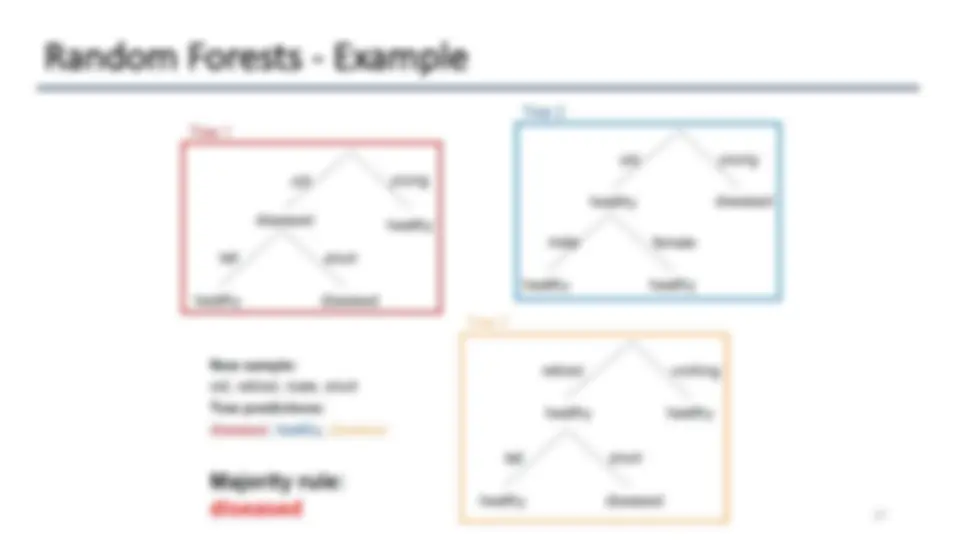
- We can combine multiple deep trees via bagging (e.g. Random Forest).
Boosting Formulation
- Train a single simple classifier (for example a decision stump)
- Combine different classifiers to get a strong a classifier using
an additive model
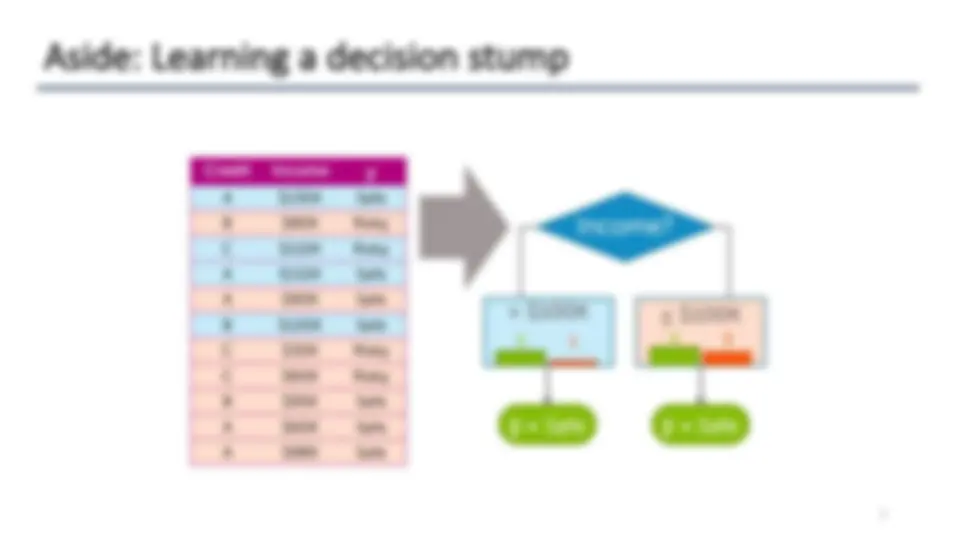
Aside: Learning a decision stump
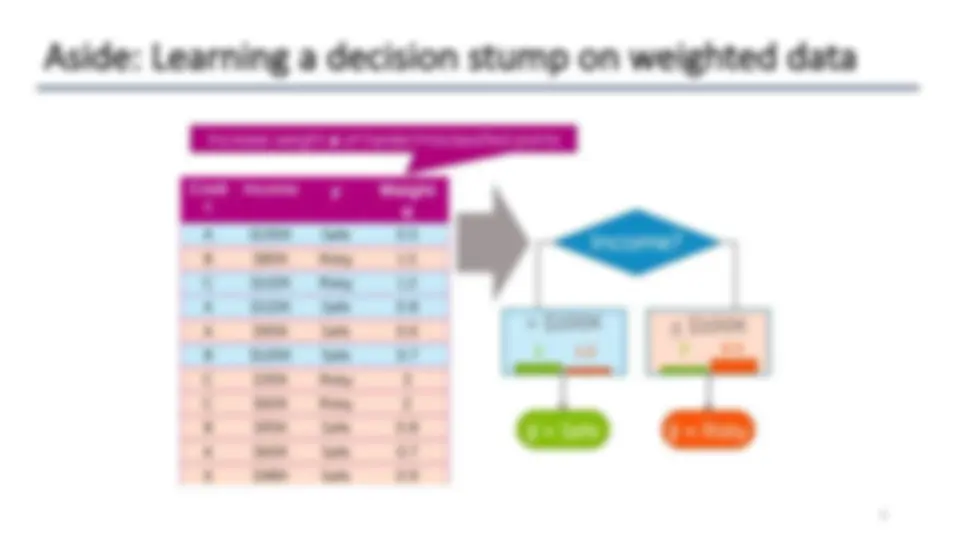
Aside: Learning a decision stump on weighted data
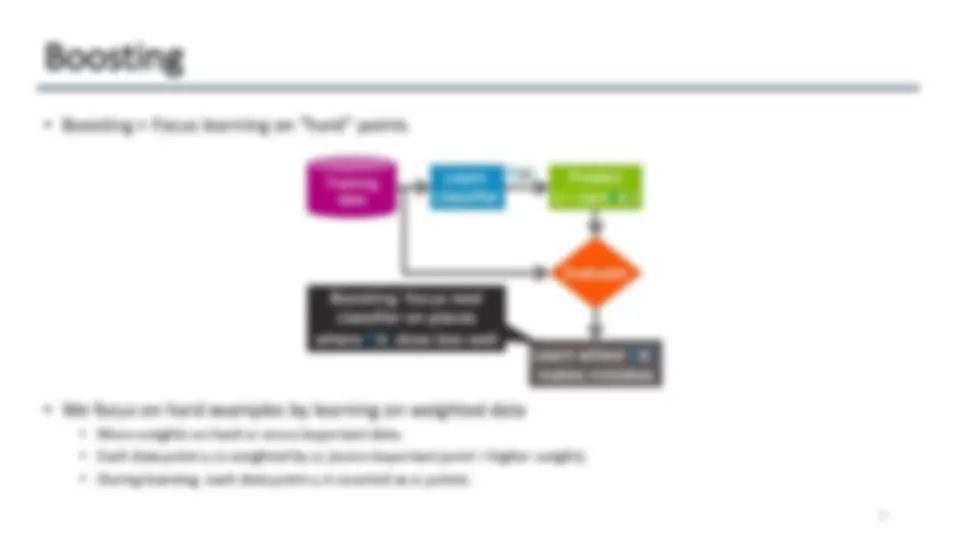
Boosting = gready learning ensembles from data
Boosting: Toy Example
Weak learners from the family of lines h => p(error) = 0.5 it is at chance Each data point has a class label: wt = and a weight:
yt =
Boosting: Toy Example
Each data point has a class label: wt = and a weight:
yt = This is a ‘ weak classifier ’: It performs slightly better than chance.
Boosting: Toy Example
We set a new problem for which the previous weak classifier performs at chance again Each data point has a class label: We update the weights:
yt = wt wt exp{-yt Ft}
Boosting: Toy Example
We set a new problem for which the previous weak classifier performs at chance again Each data point has a class label: We update the weights:
yt = wt wt exp{-yt Ft}
Flavors of boosting
- AdaBoost (Freund and Shapire, 1995)
- Real AdaBoost (Friedman et al, 1998)
- LogitBoost (Friedman et al, 1998)
- Gentle AdaBoost (Friedman et al, 1998)
- BrownBoosting (Freund, 2000)
- FloatBoost (Li et al, 2002)
- …
AdaBoost Algorithm
- Given ( x 1 , y 1 ), …, ( xm, ym ) where xiєX, yiє{- 1, +1}
- Initialise weights D 1 ( i ) = 1/ m
- Iterate t=1,…,T:
- Train weak learner using distribution Dt
- Get weak classifier: ht : X ® R
- Update:
- where Zt is a normalization factor (chosen so that Dt +1 will be a
distribution), and at:
- Output – the final classifier t t t i t i t Z D i yh x D i ( )exp( ( )) 1 (^ )
- a +^ =
ln
÷
÷
ø
ö
ç
ç
è
æ -
t t t e e a ( ) ( ( ) ) 1 å = = T t H x sign a t h t x