Download Machine learning ensemble methods Machine learning ensemble methods and more Thesis Mathematical Methods in PDF only on Docsity!
ENCS
Machine Learning and Data Science
Regression
Yazan Abu Farha - Birzeit University
Introduction
- Regression is a supervised learning task where the target variable that we are trying to predict is continuous. Examples: predicting houses prices based on the living area, predicting stock price based on the history of previous prices.
- When there is a single input variable (x), the method is referred to as simple linear regression. E.g.: predicting blood pressure as a function of drug dose.
- When there are multiple input variables, literature from statistics often refers to the method as multiple linear regression. E.g.: predicting crop yields as a function of fertilizer and water.
- Linear regression is a model that assumes a linear relationship between the input variables (x) and the single output variable (y). More specifically, that y can be calculated from a linear combination of the input variables (x)
Linear regression example with more than one variable
- Now assume that we have two features: living areas, and the number of bedrooms
- In this case, our linear regression model will have the form y = f( x ) = w 0 + w 1 x 1 + w 2 x 2 where y is the predicted house price, x 1 is the first feature (living area), x 2 is the second feature (number of bedrooms), and x = (x 1 ,x 2 ) T is the input features
Linear regression
For x in ℝ, linear regression fits a line in a 2 - dimensional space (simple linear regression) For x in ℝ^2 , linear regression fits a plane in a 3 - dimensional space (multiple linear regression)
Prediction with linear regression model
- Example: Hours studying and grades We want to learn w 0 and w 1 such that Predicted final grade in class = w 0 + w 1 *(#hours you study/week)
- Assume after learning we have: Predicted final grade in class = 59.95 + 3.17*(# hours you study/week)
- We can now use this function to predict grades for new #hours Ex: Someone who studies for 12 hours Final grade = 59.95 + (3.17*12) = 97. 2.00 4.00 6.00 8.00 10. Number of hours spent studying
Final grade in course Final grade in course = 59.95 + 3.17 * study R-Square = 0.
Linear regression
- In general, if we have d features as input x = (x 1 , x 2 , …, xd) T , then the lineart regression would have the following form y = f( x ) = w 0 + w 1 x 1 + w 2 x 2 + … + wdxd
- To simplify notation, we can augment the input with an extra dimension that has the value 1 x = (x 1 , … , xd) à x = (1, x 1 , … , xd)
- We can now write the linear regression model as follows y = f( x ) = w 0 x 0 + w 1 x 1 + w 2 x 2 + … + wdxd = ∑!"# $ xi wi = x T 𝒘
Task Definition
Problem : Given a sample S = {( x 1 , y 1 ), …, ( x n , yn)} ⊆ ℝ
d
× ℝ, find a vector w ∈ ℝ
d
such
that
best interpolates S.
" best interpolates ”: for ( x , y) we measure the discrepancy between f( x ) and y by the
square loss function
E(f( x ), y) = (f( x ) – y)
2
Linear regression solution – simple case
- Let’s first consider the solution for the simple linear regression case. I.e., the input is only one variable x.
- Given a sent of n training examples: (x 1 ,y 1 ), … , (xn,yn), we want to learn w 0 and w 1 such that f(x) = y = w 0 + w 1 x
- The solution is found by minimizing the sum of squared errors: argmin %!,%"
!"# ' 𝑦𝑖 − 𝑓 𝑥𝑖 2 argmin %!,%"
!"# ' 𝑦𝑖 − 𝑤( − 𝑤#𝑥! 2
Linear regression solution – simple case
- The solution is found by minimizing the sum of squared errors: argmin %!,%"
!"# ' 𝑦𝑖 − 𝑤( − 𝑤#𝑥! 2 Find the derivative of the error function E w.r.t. each parameter and set it to 0 )* )%"
) )%"
' 𝑦𝑖 − 𝑤( − 𝑤#𝑥! 2 ) = ∑!"# ' ) )%"
2 = ∑!"# ' − 2 𝑥! 𝑦𝑖 − 𝑤( − 𝑤#𝑥! = − 2 ∑!"# ' 𝑦!𝑥! − 𝑤(𝑥! − 𝑤#𝑥! . )* )%" = 0 à 0 = ∑!"# ' 𝑦!𝑥! − ∑#$" % ,! '
∑#$" %
-! '
. à 𝑤# = ∑#$" % ,#-# / ∑#^ %$^ "'! ∑#^ %$^ "(! % ∑#$" %
- ) / ∑ #$" % (^) ( ! ∑#$" % (^) ( ! %
Recap - Task Definition Problem : Given a sample S = {( x 1 , y 1 ), …, ( x n , yn)} ⊆ ℝ d × ℝ, find a vector w ∈ ℝ d such that 𝑓 𝒙 = 𝒙 , 𝒘 best interpolates S. " best interpolates ”: for ( x , y) we measure the discrepancy between f( x ) and y by the square loss function E(f( x ), y) = (f( x ) – y) 2 Notion and notation:
- x ∈ ℝd^ is regarded as a column vector, its transpose x T^ as a row vector.
- X is an n × d data matrix (i.e. its i-th row is x iT); y = (y 1 , …, yn)T
- Inner product of x , z ∈ ℝd^ : 𝒙 , 𝒛 = x T^ 𝒛 = ∑#$% & xi zi
- Euclidean norm of a vector x ∈ ℝd^ : 𝒙 = 𝒙 , 𝒙
Linear Regression – The normal equations
- Convex minimization problem: min w E[ w ] = min w $ ,
X w − y
2
∇ w E[ w ] =
. .𝐰
$ ,
X w − y
2
. .𝐰
$ ,
( w
T
X
T
X w – 2 w
T
X
T
y + y
T
y ) )
$ ,
(2 X
T
X w - 2 X
T
y )
X w = X
T
y
- And solve the linear system of equations: w = ( X T
X)
- 1
X
T
y
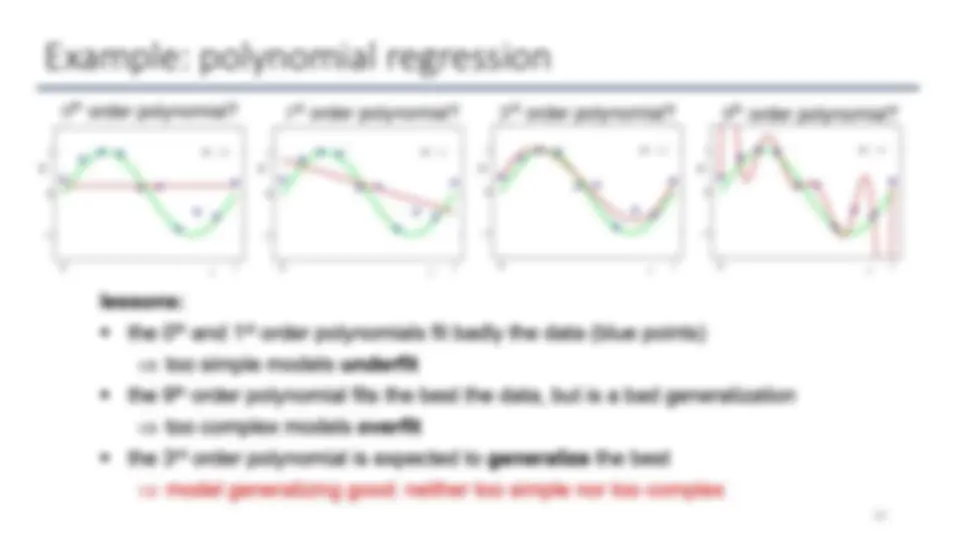
Linear Regression and overfitting
- Linear regression solution: w = ( X T
X)
- 1
X
T
y
- High values in w correspond to an overfitting problem.
- Solution: use regularizer to discourage coefficient from taking large values
- Penalize the sum of the squares of the coefficients, i.e. 𝐰 2
- Solve min w 0 X w − y 2 + λ 𝐰 2
- Solution: w = ( X T X + λ Id) - 1 X T y (λ is a hyper-parameter and Id is d × d identity matrix)
- This case is called Ridge Regression (ridge regression = Regularised Least Squares)
Probabilistic Interpretation of Linear Regression
- Our goal is to approximate f by f’
- The maximum likelihood estimate of f’ is
f’ML = argmax
56
6
= argmax
56
"#$ 7
6
= argmax
56
"#$ 7 $ 012
3 ! " #! $%( &! " ' "
Maximize natural log of this instead ….
f 𝜖 4 e 4 e (^1) e 3 e 2 e 5
Probabilistic Interpretation of Linear Regression
f’ML = argmax
56
"#$ 7
$ 012
* −^
$ 0 (^8) + 356 9 +
2
= argmax
56
"#$ 7
$ 0 (^8) + 356 9 +
2
= argmax
56
"#$ 7
2
f’ML = argm𝑖𝑛
56
"#$ 7
2
Maximum Likelihood estimate f’ML minimizes the sum of squared errors
f 𝜖 4 e 4 e (^1) e 3 e 2 e 5