


Theseareslideswithahistory.Ifoundthemonthe
web...TheyareapparentlybasedonDanWeld’sclassat
U.Washington,(whointurnbasedhisslidesonthose
byJeffDean,SanjayGhemawat,Google,Inc.)


































Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Notes; Class: Intermediate Computer Systems; Subject: Computer Science; University: Cornell University; Term: Spring 2008;
Typology: Study notes
1 / 42

This page cannot be seen from the preview
Don't miss anything!
These
are^ slides
with
a^ history.
I^ found
them
on^ the
web...
They
are^ apparently
based
on^ Dan
Weld’s
class
at
U.^ Washington,
(who
in^ turn
based
his^ slides
on^ those
by^ Jeff
Dean,
Sanjay
Ghemawat,
Google,
Inc.)
y^ Want
to^ use
1000s
of^ CPUs
y^ But^
don’t^ want
hassle
of^ managing
things
y^ But^
don t^ want
hassle
of^ managing
things
y^ Automatic
parallelization
&^ distribution
y^ Fault
tolerance y^ I/O
scheduling y^ I/O
scheduling y^ Monitoring
&^ status
updates
y^ (1^4
y^ (+^16
y^ emits
new‐
key^ /^
new‐val pairs
y^ emits
final^
output
(k^
l^ l^
map(key=url,
val=contents):
For^ each
word^ w
in^ contents,
emit^ (w,
“1”)
reduce(key=word,
values=uniq counts):
Count, Illustrated
reduce(key word,
values
uniq
_counts):
Sum^ all
“1”s^ in
values
list
Emit^ result
“(word,
sum)”
see bob throwsee spot run
see^
bob^
bob^
run^
see spot run
run^
see^
see^
spot^
spot^
throw
throw
Input
consists
of^ (url+offset,
single
line)
y^ map(key=url+offset,
val=line):
If^
h^
i^ (li^
“ ”)
y^ If^ contents
matches
regexp,
emit^ (line,
“1”)
y^ reduce(key=line,
values=uniq counts): (^ y^
q_^
y^ Don’t
do^ anything;
just^ emit
line
each^
file^ f^ and
each word
in^ the
file^ w
Output(f,w)
pairs
eliminating
duplicates
Model
is^ Widely
Applicabley pp
Example uses:Example
uses: distributed grep
distributed sort
web link-graph reversal
term-vector / host
web access log stats
inverted index construction
i^ i^ l^
hi
document clustering
machine learning
statistical machinetranslation
...^
...^
...
1.^ Partition
input
key/value
pairs
into^ chunks,
run
()^ t^ k
i^
ll l
map()
tasks
in^ parallel
2.^ After
all^ map()s
are^ complete,
consolidate
all^ emitted
values
for^ each
unique
emitted
key q^
y
3.^ Now
partition
space
of^ output
map^
keys,^
and^ run
reduce()
in^ parallel
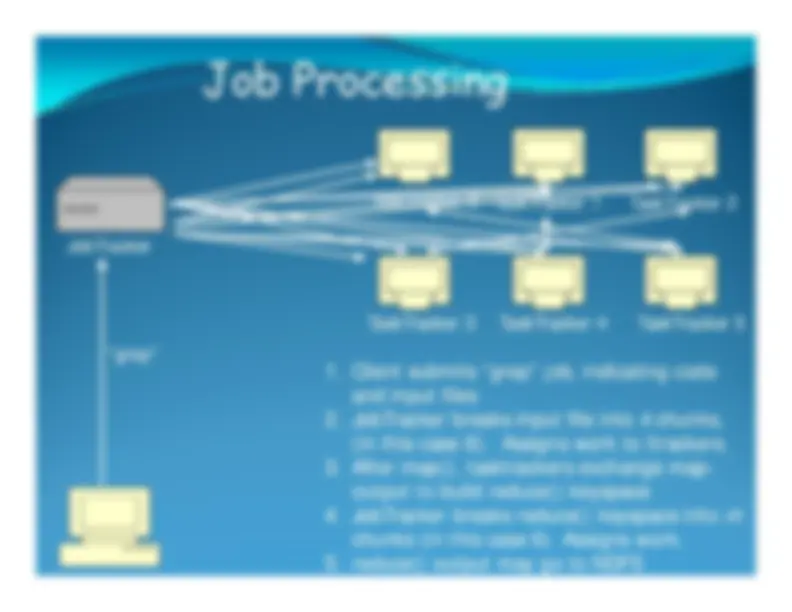
Job Processing
JobTracker
TaskTracker 0
TaskTracker 1
TaskTracker 2
TaskTracker 3
TaskTracker 4
TaskTracker 5
k chunks
“grep”
k chunks,
(in this case 6).
Assigns work to ttrackers.
p^
()^ y p
m
chunks (in this case 6). Assigns work.5. reduce() output may go to NDFS
T^ k G
l^ i & Pi
li i
Task
Granularity
&^ Pi
pelining
y^ Fine
granularity
tasks:
map
tasks
^ machines
y^ Fine
granularity
tasks:
map
tasks
^ machines
y^ Minimizes
time^ for
fault^ recovery
y^ Can pipeline
shuffling
with^ map
execution
d^
l^ d b l y^ Better
dynamic
load^ b
alancing
y^ Often
use^ 200,
map
&^5000
reduce
tasks,
running
on^2000
machines
running
on^2000
machines