



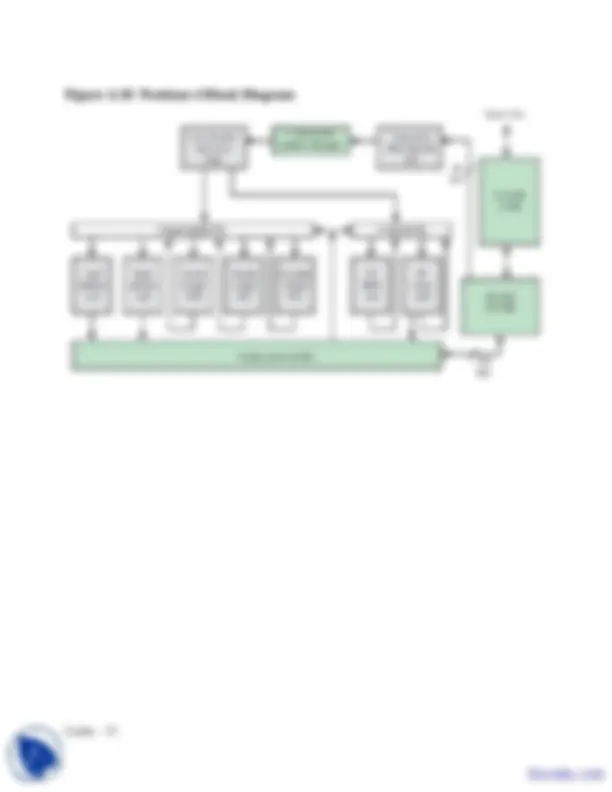
Memory Hierarchy
Goal: “Fast”, “unlimited” storage at a reasonable cost per bit.
Recall the von Neumann bottleneck - single, relatively slow path between the CPU and main
memory.
Cache - 1
Docsity.com









Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
In the lecture notes of the intro to computer architecture the main points are listed below:Memory Hierarchy, Reasonable Cost Per Bit, Neumann Bottleneck, Typical System View, Cache and Main Memory, Cache Sizes of Some Processors, Main Idea of Cache, Access Time, System Bus, Addressed Memory Value`Memory Hierarchy, Reasonable Cost Per Bit, Neumann Bottleneck, Typical System View, Cache and Main Memory, Cache Sizes of Some Processors, Main Idea of Cache, Access Time, System Bus, Addressed Memory
Typology: Study notes
1 / 15

This page cannot be seen from the preview
Don't miss anything!
16