


CMSC423: Bioinformatic
Algorithms, Databases and Tools
Lecture 19
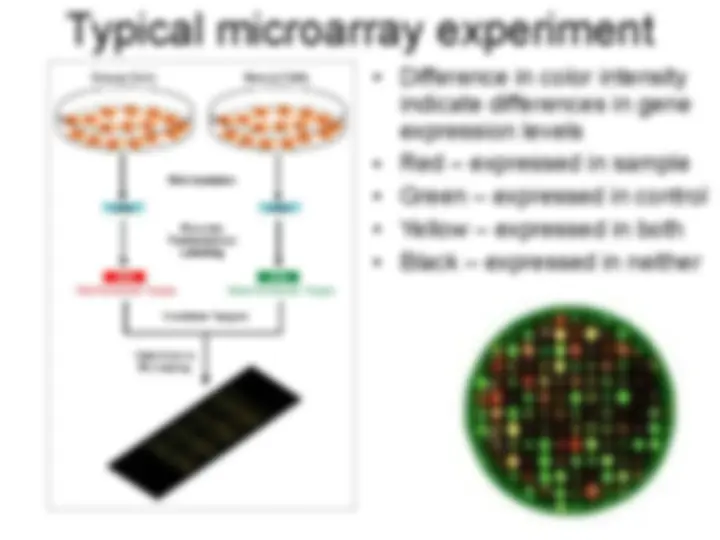
Microarray data analysis








Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Material Type: Notes; Class: BIOINFO ALGS, DB, TOOLS; Subject: Computer Science; University: University of Maryland; Term: Unknown 1989;
Typology: Study notes
1 / 14

This page cannot be seen from the preview
Don't miss anything!
distance
cluster
clusters – the sets of leaves in the corresponding subtrees