



docsity.com


























Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
This is project presentation related to Application of Computer Science course. This presentation was delivered in presence of Prof. Ashish Behari at Alliance University. Its main points are: Mitochondrial, Protein, Sequence, Extraction, Selection, Strategies, Classification, Techniques, Amino, Acids
Typology: Slides
1 / 35

This page cannot be seen from the preview
Don't miss anything!
Introduction
Basic Concepts
Feature Extraction strategies
Feature Selection strategies
Classification techniques
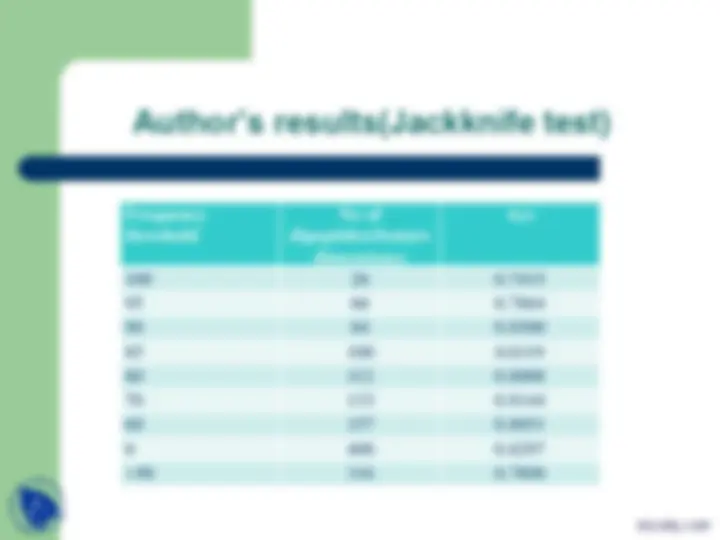
Description of Author’s results
Comparison with Author’s results
Comparison with other methods
Conclusions
Future Work
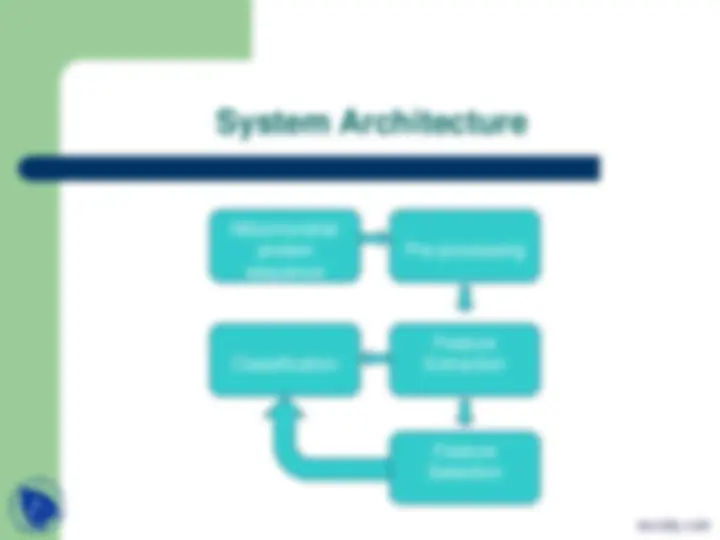
Before starting discussion to our project one must have some basic concepts discussed as :
Proteins are the major components of living organisms and constitute more than 25% weight of a cell.
It performs functions e.g. catalysis, transport, transportation, digestion, movement, sensory capabilities, sense of taste, sense of vision and control the gene function.
Proteins are made up of strings of amino acids(usually represented by English letters).
Amino acid 3-letter Abbreviation 1-letter Abbreviation Alanine Ala A Cysteine Cys C Aspartic acid Asp D Glutamic acid Glu E phenylalanine Phe F Glycine Gly G Histidine His H Isoleucine Ile I Lysine Lys K Leucine Leu L Methionine Met M Asparagine Asn N Proline Pro P Glutamine Gln Q Arganine Arg R Serine Ser S Threonine Thr T Valine Val V Tryptophan Trp W Tyrosine Tyr Y
>sp|P31937|3HIDH_HUMAN 3-hydroxyisobutyrate dehydrogenase, mitochondrial precursor (EC 1.1.1.31) (HIBADH) - Homo sapiens (Human).
The dataset used in this project has been generated in Jiang et al., 2006 and is received on request from [email protected].
Comprises of 499 and 681 mitochondrial (positive) and non- mitochondrial (negative) sequences.
We have used four kinds of proteins representations including:
Contains a set of greater than 20 discrete factors, where the first 20 represent the components of its conventional Amino Acid composition while the additional factors incorporate some sequence-order information via various modes. P = [ P 1 , P 2 ,…P 20 …. P20+ λ ]
Whereas P 1 , P 2 ,…P 20 are the normalized occurrence frequencies of 20 amino acids and
P 21 , P 22 , ……, PΛ are the 1st-teir to λ - tier correlation factor of amino acid sequence in the protein chain determined based on hydrophobicity and hydrophilicity.
Hydrophobicity and hydrophilicity correlation functions are used
It is used to transform the variable length of proteins sequences to fixed length feature vectors.
Occurrence frequency of every consecutive pair of amino acids is calculated F(i) = P(i) / P Where P(i) is the occurrence frequency of pair ‘ i’ and P is the total number of pairs in a protein sequence
400 dimensional feature vector.
We have some very small number of sequences in the dataset where total amino acids in the protein sequence is less than 50.
So for that we divided it into the same three parts but with:
We have employed two different feature selection strategies for dipeptide composition including:
Jackknifing test
Independent test
Self Consistency test
Sensitivity(), Specificity(), Accuracy (ACC), Mathew Correlation Coefficient (MCC)