Download Multiprocessor - Advance Computers Architectures - Lecture Slides and more Slides Computer Architecture and Organization in PDF only on Docsity!
CIS 600 Advanced Computer
Architecture
Lecture 8 –Multiprocessor
Introduction
Uniprocessor Performance (SPECint)
1
10
100
1000
10000
1978 1980 1982 1984 1986 1988 1990 1992 1994 1996 1998 2000 2002 2004 2006
Performance (vs. VAX-11/780) 25%/year
52%/year
??%/year
- VAX : 25%/year 1978 to 1986
- RISC + x86: 52%/year 1986 to 2002
- RISC + x86: ??%/year 2002 to present
From Hennessy and Patterson, Computer Architecture: A Quantitative Approach , 4th edition, 2006
3X
Docsity.com
Other Factors ⇒ Multiprocessors
- Growth in data-intensive applications
- Data bases, file servers, …
- Growing interest in servers, server perf.
- Increasing desktop perf. less important
- Improved understanding in how to use multiprocessors effectively - Especially server where significant natural TLP
- Advantage of leveraging design investment by replication - Rather than unique design
Flynn’s Taxonomy
- Flynn classified by data and control streams in 1966
- SIMD ⇒ Data Level Parallelism
- MIMD ⇒ Thread Level Parallelism
- MIMD popular because
- Flexible: N pgms and 1 multithreaded pgm
- Cost-effective: same MPU in desktop & MIMD
Single Instruction Single Data (SISD) (Uniprocessor)
Single Instruction Multiple Data SIMD (single PC: Vector, CM-2) Multiple Instruction Single Data (MISD) (????)
Multiple Instruction Multiple Data MIMD (Clusters, SMP servers)
Proc. of the IEEE^ M.J. Flynn, "Very High-Speed Computers",, V 54, 1900-1909, Dec. 1966.
Centralized vs. Distributed Memory
P 1 $ Interconnection network
$
Pn
Mem (^) Mem
P 1 $ Interconnection network
$
Pn
Mem Mem
Centralized Memory Distributed Memory
Scale
Centralized Memory Multiprocessor
- Also called symmetric multiprocessors (SMPs) because single main memory has a symmetric relationship to all processors
- Large caches ⇒ single memory can satisfy memory demands of small number of processors
- Can scale to a few dozen processors by using a switch and by using many memory banks
- Although scaling beyond that is technically conceivable, it becomes less attractive as the number of processors sharing centralized memory increases
2 Models for Communication and
Memory Architecture
1. Communication occurs by explicitly passing
messages among the processors:
message-passing multiprocessors
2. Communication occurs through a shared
address space (via loads and stores):
shared memory multiprocessors either
- UMA (Uniform Memory Access time) for shared address, centralized memory MP
- NUMA (Non Uniform Memory Access time multiprocessor) for shared address, distributed memory MP
- In past, confusion whether “sharing” means
sharing physical memory (Symmetric MP) or
sharing address space
Challenges of Parallel Processing
- First challenge is % of program inherently sequential
- Suppose 80X speedup from 100 processors. What fraction of original program can be sequential? a. 10% b. 5% c. 1% d. <1%
Challenges of Parallel Processing
- Application parallelism ⇒ primarily via new algorithms that have better parallel performance
- Long remote latency impact ⇒ both by architect and by the programmer
- For example, reduce frequency of remote accesses either by
- Caching shared data (HW)
- Restructuring the data layout to make more accesses local (SW)
- Today’s lecture on HW to help latency via caches
Symmetric Shared-Memory
Architectures
- From multiple boards on a shared bus to multiple processors inside a single chip
- Caches both
- Private data are used by a single processor
- Shared data are used by multiple processors
- Caching shared data ⇒ reduces latency to shared data, memory bandwidth for shared data, and interconnect bandwidth ⇒ cache coherence problem
Example
- Intuition not guaranteed by coherence
- expect memory to respect order between
accesses to different locations issued by a given process
- to preserve orders among accesses to same location by different processes
P 1 P 2 /Assume initial value of A and flag is 0/ A = 1; while (flag == 0); /spin idly/ flag = 1; print A;
Mem
P 1 Pn
Conceptual Picture
Intuitive Memory Model
- Too vague and simplistic; 2 issues
- Coherence defines values returned by a
read
- Consistency determines when a written
value will be returned by a read
P
Disk
Memory
L
L
100:
100:
100:
- Reading an address should return the last value written to that address
- Easy in uniprocessors, except for I/O
Write Consistency
- A write does not complete (and allow the
next write to occur) until all processors have seen the effect of that write
- The processor does not change the order of
any write with respect to any other memory access
⇒ if a processor writes location A followed by
location B, any processor that sees the new value of B must also see the new value of A
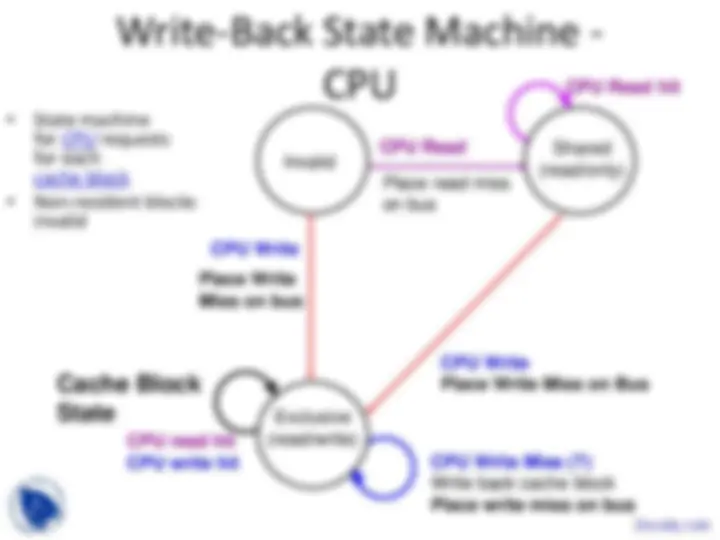
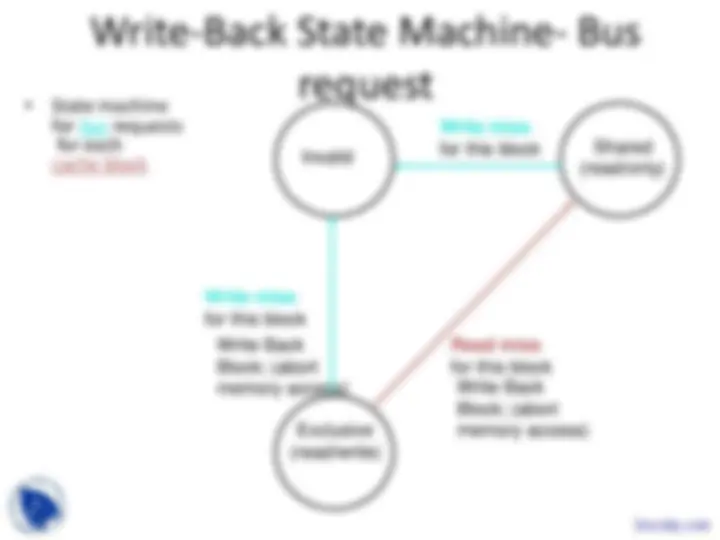
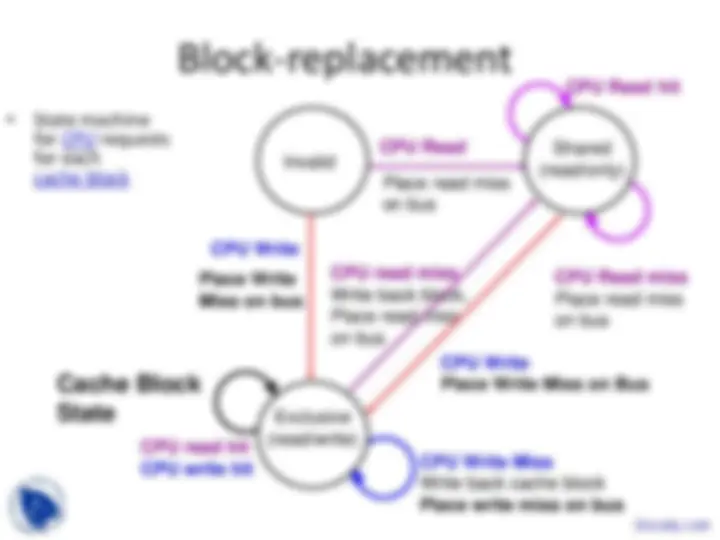
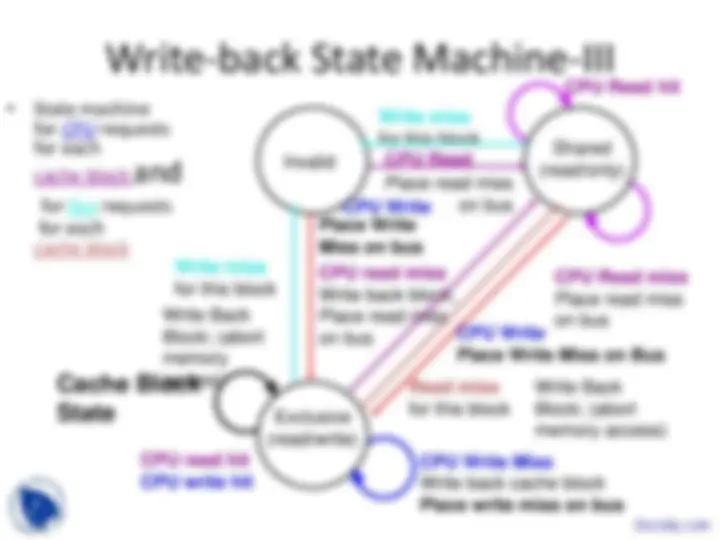
Basic Schemes for Enforcing Coherence
- Program on multiple processors will normally
have copies of the same data in several caches
- Unlike I/O, where its rare
- Rather than trying to avoid sharing in SW,
SMPs use a HW protocol to maintain coherent caches
- Migration and Replication key to performance of shared data
- Migration - data can be moved to a local cache
and used there in a transparent fashion