



1
Data Warehousing
Lecture-25
Need for Speed: Parallelism Methodologies
Docsity.com















Study with the several resources on Docsity

Earn points by helping other students or get them with a premium plan

Prepare for your exams
Study with the several resources on Docsity
Earn points to download
Earn points by helping other students or get them with a premium plan
Need for Speed Parallelism Methodologies, Motivation, Data Parallelism Concept, Ensuring Speed UP, Temporal Parallelism, Pipelining Time Chart, Speed Up Calculation. Some Other terms are also described in these data warehousing lecture slides.
Typology: Slides
1 / 23

This page cannot be seen from the preview
Don't miss anything!
1
2
Motivation
with single infinitely fast processor with an infinite memory with infinite bandwidth and its infinitely cheap too (free!)
infinitely fast processor out of infinitely many processors of finite speed
Infinitely large memory with infinite memory bandwidth from infinite many finite storage units of finite speed
No text goes to graphics
4
Data Parallelism: Example
Emp Table
Partition 1Partition-
Partition-
Partition-k
. . .
62
440
1,
Query Server-
Query Server-
Query Server-k
. . .
Query Coordinator
Select count () from Emp where age > 50 AND sal > 10,000’;*
Ans = 62 + 440 + ... + 1,123 = 99,
5
servers.
performance bottlenecks.
suffice.
criterion across partitions.
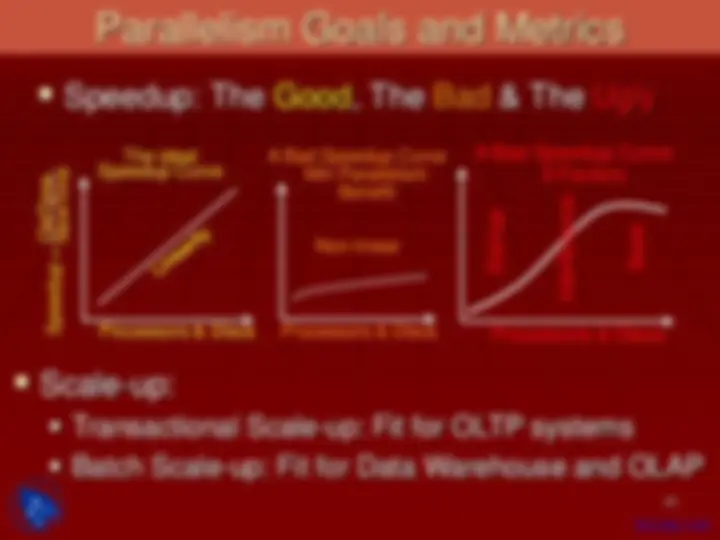
Data Parallelism: Ensuring Speed-UP
No text will go to graphics
7
Pipelining: Time Chart
Time = T/ []^ []
Time = T/3 Time = T/
Time = T/ []^ []
Time = T/3 Time = T/
Time = T/ []
Time = T/3 Time = T/
T = 0 T = 1^ T = 2
Time = T/ []
Time = T/
T = 3
8
Pipelining: Speed-Up Calculation
Time for sequential execution of 1 task = T
Time for sequential execution of N tasks = N * T
(Ideal) time for pipelined execution of one task using an M stage pipeline = T
(Ideal) time for pipelined execution of N tasks using an M stage pipeline = T + ((N-1) × (T/M))
Speed-up (S) =
Pipeline parallelism focuses on increasing throughput of task execution, NOT on decreasing sub-task execution time.
10
Pipelining: Input vs Speed-Up
1
2
3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Input (N)
Speed-up (S)
Asymptotic limit on speed-up for M stage pipeline is M.
The speed-up will NEVER be M, as initially filling the pipeline took T time units.
11
Pipelining: Limitations
Relational pipelines are rarely very long
Even a chain of length ten is unusual.
Some relational operators do not produce first
Aggregate and sort operators have this property. One cannot pipeline these operators.
Often, execution cost of one operator is much
e.g. Sum() or count() vs Group-by() or Join.
No text goes to graphics Docsity.com
13
Round Robin
Advantages
Range queries are difficult to process
Partitioning & Queries
yellow goes to graphics
14
Hash Partitioning
Good for sequential access
With uniform hashing and using partitioning attributes as a key, tuples will be equally distributed between disks.
Good for point queries on partitioning attribute
Can lookup single disk, leaving others available for answering other queries.
Index on partitioning attribute can be local to disk, making lookup and update very efficient even joins.
Partitioning & Queries
yellow goes to graphics
Docsity.com
16
Parallel Sorting
data
Processors
1 2 3 4 5
Hot spot P1 P2 P3 P4 P
1 4 1 2 1
17
Skew in Partitioning
i.e. some disks have many tuples, while others may have fewer tuples.
Attribute-value skew. Some values appear in the partitioning attributes of many tuples; all the tuples with the same value for the partitioning attribute end up in the same partition.
Can occur with range-partitioning and hash-partitioning.
Partition skew. With range-partitioning, badly chosen partition vector may assign too many tuples to some partitions and too few to others.
Less likely with hash-partitioning if a good hash-function is chosen.
yellow goes to graphics
19
Barriers to Linear Speedup & Scale-up
Time needed to start a large number of processors. Increase with increase in number of individual processors. May also include time spent in opening files etc.
Slow down that each processor imposes on all others when sharing a common pool of resources “(e.g. memory).
Variance dominating the mean. Service time of the job is service time of its slowest components.
yellow goes to graphics
20
Comparison of Partitioning Techniques
Shared disk/memory less sensitive to partitioning.
Shared nothing can benefit from good partitioning.
A…E F…J O…S K…N T…Z
Range
Good for equijoins, range queries, group-by clauses, can result in “hot spots”.
Users
A…E F…J O…S K…N T…Z
Round Robin
Good for load balancing, but impervious to nature of queries.
Users
A…E F…J O…S K…N T…Z
Hash
Good for equijoins, can results in uneven data distribution
Users